Python 官方文档:入门教程 => 点击学习
目录引言1. 简介2. Symbolic TransfORMers3. Attention 机制4. Attention Masking5. 非标准 Attention6. Enco
展示神经符号编程的力量
在过去的几年里,我们看到了基于 Transformer 的模型的兴起,并在自然语言处理或计算机视觉等许多领域取得了成功的应用。在本文中,我们将探索一种简洁、可解释和可扩展的方式来表达深度学习模型,特别是 Transformer,作为混合架构,即通过将深度学习与符号人工智能结合起来。为此,我们将在名为 PyNeuraLogic 的 python 神经符号框架中实现模型。
将符号表示与深度学习相结合,填补了当前深度学习模型的空白,例如开箱即用的可解释性或缺少推理技术。也许,增加参数的数量并不是实现这些预期结果的最合理方法,就像增加相机百万像素的数量不一定会产生更好的照片一样。
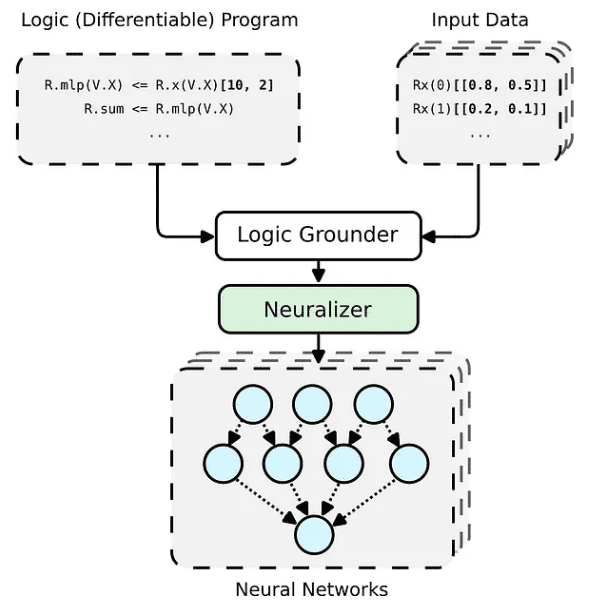
PyNeuraLogic 框架基于逻辑编程——逻辑程序包含可微分的参数。该框架非常适合较小的结构化数据(例如分子)和复杂模型(例如 Transformers 和图形神经网络)。另一方面,PyNeuraLogic 不是非关系型和大型张量数据的最佳选择。
该框架的关键组成部分是一个可微分的逻辑程序,我们称之为模板。模板由以抽象方式定义神经网络结构的逻辑规则组成——我们可以将模板视为模型架构的蓝图。然后将模板应用于每个输入数据实例,以生成(通过基础和神经化)输入样本独有的神经网络。这个过程与其他具有预定义架构的框架完全不同,这些框架无法针对不同的输入样本进行自我调整。
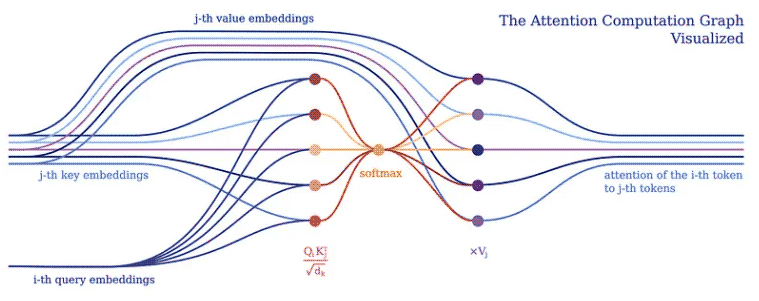
我们通常倾向于将深度学习模型实现为对批处理成一个大张量的输入令牌的张量操作。这是有道理的,因为深度学习框架和硬件(例如 GPU)通常针对处理更大的张量而不是形状和大小不同的多个张量进行了优化。 Transformers 也不例外,通常将单个标记向量表示批处理到一个大矩阵中,并将模型表示为对此类矩阵的操作。然而,这样的实现隐藏了各个输入标记如何相互关联,这可以在 Transformer 的注意力机制中得到证明。
注意力机制构成了所有 Transformer 模型的核心。具体来说,它的经典版本使用了所谓的多头缩放点积注意力。让我们用一个头(为了清楚起见)将缩放的点积注意力分解成一个简单的逻辑程序。
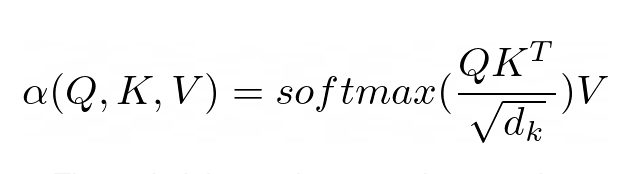
注意力的目的是决定网络应该关注输入的哪些部分。注意通过计算值 V 的加权和来实现,其中权重表示输入键 K 和查询 Q 的兼容性。在这个特定版本中,权重由查询 Q 和查询的点积的 softmax 函数计算键 K,除以输入特征向量维数 d_k 的平方根。
(R.weights(V.I, V.J) <= (R.d_k, R.k(V.J).T, R.q(V.I))) | [F.product, F.softmax_agg(agg_terms=[V.J])],
(R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.J)) | [F.product]
在 PyNeuraLogic 中,我们可以通过上述逻辑规则充分捕捉注意力机制。第一条规则表示权重的计算——它计算维度的平方根倒数与转置的第 j 个键向量和第 i 个查询向量的乘积。然后我们用 softmax 聚合给定 i 和所有可能的 j 的所有结果。
然后,第二条规则计算该权重向量与相应的第 j 个值向量之间的乘积,并对每个第 i 个标记的不同 j 的结果求和。
在训练和评估期间,我们通常会限制输入令牌可以参与的内容。例如,我们想限制标记向前看和关注即将到来的单词。流行的框架,例如 PyTorch,通过屏蔽实现这一点,即将缩放的点积结果的元素子集设置为某个非常低的负数。这些数字强制 softmax 函数将零指定为相应标记对的权重。
(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I), R.special.leq(V.J, V.I)
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],
使用我们的符号表示,我们可以通过简单地添加一个身体关系作为约束来实现这一点。在计算权重时,我们限制第 j 个指标小于或等于第 i 个指标。与掩码相反,我们只计算所需的缩放点积。
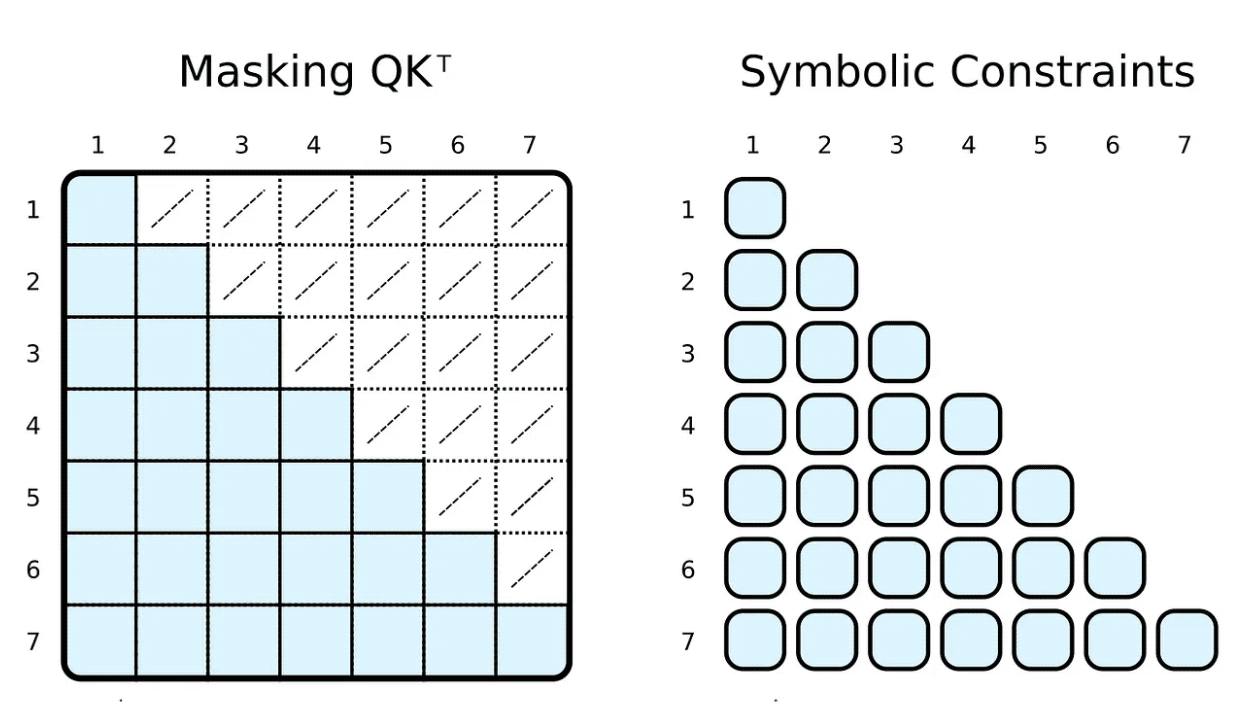
当然,象征性的“掩蔽”可以是完全任意的。我们大多数人都听说过基于稀疏变换器的 GPT-3⁴(或其应用程序,例如 ChatGPT)。⁵ 稀疏变换器的注意力(跨步版本)有两种类型的注意力头:
两种类型的头的实现都只需要微小的改变(例如,对于 n = 5)。
(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I),
R.special.leq(V.D, 5), R.special.sub(V.I, V.J, V.D),
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],
(R.weights(V.I, V.J) <= (
R.d_k, R.k(V.J).T, R.q(V.I),
R.special.mod(V.D, 5, 0), R.special.sub(V.I, V.J, V.D),
)) | [F.product, F.softmax_agg(agg_terms=[V.J])],
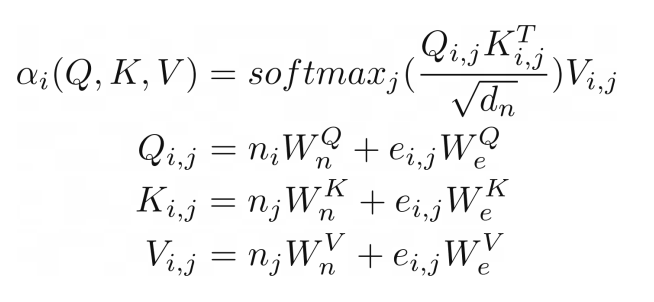
我们可以走得更远,将对类似图形(关系)输入的注意力进行概括,就像在关系注意力中一样。⁶ 这种类型的注意力在图形上运行,其中节点只关注它们的邻居(由边连接的节点)。查询 Q、键 K 和值 V 是边嵌入与节点向量嵌入相加的结果。
(R.weights(V.I, V.J) <= (R.d_k, R.k(V.I, V.J).T, R.q(V.I, V.J))) | [F.product, F.softmax_agg(agg_terms=[V.J])],
(R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.I, V.J)) | [F.product],
R.q(V.I, V.J) <= (R.n(V.I)[W_qn], R.e(V.I, V.J)[W_qe]),
R.k(V.I, V.J) <= (R.n(V.J)[W_kn], R.e(V.I, V.J)[W_ke]),
R.v(V.I, V.J) <= (R.n(V.J)[W_vn], R.e(V.I, V.J)[W_ve]),
在我们的例子中,这种类型的注意力与之前显示的缩放点积注意力几乎相同。唯一的区别是添加了额外的术语来捕获边缘。将图作为注意力机制的输入似乎很自然,这并不奇怪,因为 Transformer 是一种图神经网络,作用于完全连接的图(未应用掩码时)。在传统的张量表示中,这并不是那么明显。
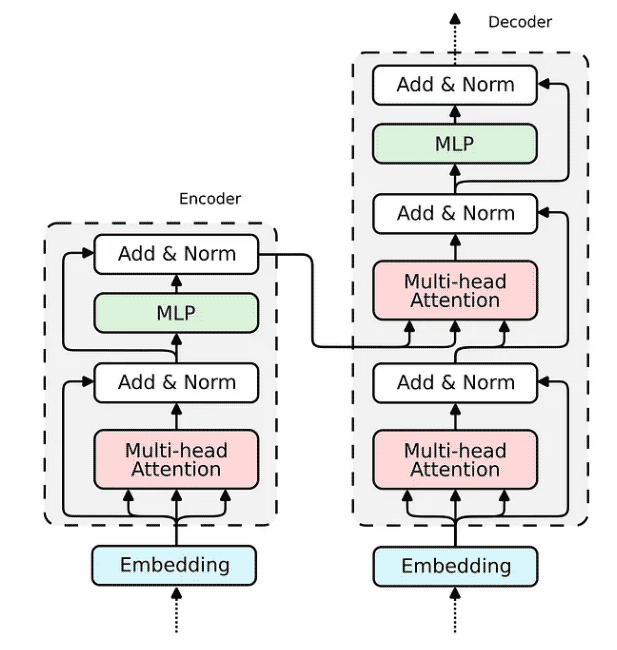
现在,当我们展示 Attention 机制的实现时,构建整个 transformer 编码器块的缺失部分相对简单。
我们已经在 Relational Attention 中看到了如何实现嵌入。对于传统的 Transformer,嵌入将非常相似。我们将输入向量投影到三个嵌入向量中——键、查询和值。
R.q(V.I) <= R.input(V.I)[W_q],
R.k(V.I) <= R.input(V.I)[W_k],
R.v(V.I) <= R.input(V.I)[W_v],
查询嵌入通过跳过连接与注意力的输出相加。然后将生成的向量归一化并传递到多层感知器 (MLP)。
(R.norm1(V.I) <= (R.attention(V.I), R.q(V.I))) | [F.norm],
对于 MLP,我们将实现一个具有两个隐藏层的全连接神经网络,它可以优雅地表达为一个逻辑规则。
(R.mlp(V.I)[W_2] <= (R.norm(V.I)[W_1])) | [F.relu],
最后一个带有规范化的跳过连接与前一个相同。
(R.norm2(V.I) <= (R.mlp(V.I), R.norm1(V.I))) | [F.norm],
我们已经构建了构建 Transformer 编码器所需的所有部分。解码器使用相同的组件;因此,其实施将是类似的。让我们将所有块组合成一个可微分逻辑程序,该程序可以嵌入到 Python 脚本中并使用 PyNeuraLogic 编译到神经网络中。
R.q(V.I) <= R.input(V.I)[W_q],
R.k(V.I) <= R.input(V.I)[W_k],
R.v(V.I) <= R.input(V.I)[W_v],
R.d_k[1 / math.sqrt(embed_dim)],
(R.weights(V.I, V.J) <= (R.d_k, R.k(V.J).T, R.q(V.I))) | [F.product, F.softmax_agg(agg_terms=[V.J])],
(R.attention(V.I) <= (R.weights(V.I, V.J), R.v(V.J)) | [F.product],
(R.norm1(V.I) <= (R.attention(V.I), R.q(V.I))) | [F.norm],
(R.mlp(V.I)[W_2] <= (R.norm(V.I)[W_1])) | [F.relu],
(R.norm2(V.I) <= (R.mlp(V.I), R.norm1(V.I))) | [F.norm],
在本文中,我们分析了 Transformer 架构并演示了它在名为 PyNeuraLogic 的神经符号框架中的实现。通过这种方法,我们能够实现各种类型的 Transformer,只需对代码进行微小的更改,说明每个人都可以如何快速转向和开发新颖的 Transformer 架构。它还指出了各种版本的 Transformers 以及带有 GNN 的 Transformers 的明显相似之处。
以上就是详解python使用 PyNeuraLogic超越Transformers的详细内容,更多关于PyNeuraLogic超越Transformers的资料请关注编程网其它相关文章!
--结束END--
本文标题: 详解python架构 PyNeuraLogic超越Transformers
本文链接: https://lsjlt.com/news/200916.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0