Python 官方文档:入门教程 => 点击学习
首先我们一起回顾一些并发的场景 首先最基本的,我们要弄清楚什么的并发嘞?我简单粗暴的理解就是:一段代码,在同一时间段内,被多个线程同时处理的情况就是并发现象。下面简单画了个图: 那
首先我们一起回顾一些并发的场景
首先最基本的,我们要弄清楚什么的并发嘞?我简单粗暴的理解就是:一段代码,在同一时间段内,被多个线程同时处理的情况就是并发现象。下面简单画了个图:
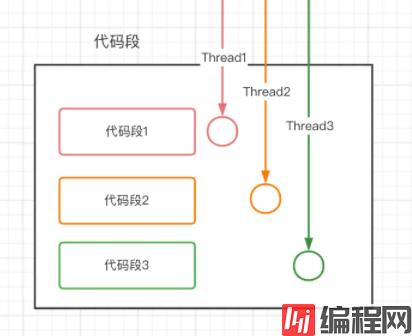
那么只要是并发现象就需要我们进行并发处理吗?那肯定不是滴。我们就拿大家都能理解的订单业务来举例,比如说下面两种简单的场景:
以上两种场景的区别基本上就是随机唯一序列号和顺序递增序列号的区别。伪代码如下:
public void addOrder() {
// 1.获取当前年月日以及商户标识
String currentDate = "yyyyMMddHHmmss";
String busineSSMan = "商户标识";
// 2.获取获取序列号
long index = getIndex();
// 3.拼接订单号
String orderNum = businessman + currentDate + index;
// 4.生成订单
save(订单对象);
}那么对于C端的随机唯一序列号来讲,我认为肯定是没必要进行并发控制的,只要写一个生成随机唯一序列号的算法就好了,这样生成出来的订单号必然是唯一的。
public String getIndex() {
// 根据算法生成唯一序列号
return buildIndexUtils.build();
}但对于B端的顺序递增序列号来讲,就需要进行并发控制了。因为既然要保证顺序递增,我在生成当前序列号的同时就必然需要之前上一个单子的序列号是什么,因此我就必然需要一个地方去存储这个序列号。伪代码如下:
public String getIndex() {
// 1.获取当前商户、当前单据已生成的最大序列号
Integer index = dao.getIndex(商户, 单据) + 1;
// 2.序列号 + 1
index = index++;
// 3.修改当前商户、当前单据已生成的最大序列号
dao.update(商户, 单据, index);
// 4.返回序列号
return index + "";
}此时如果事务为可重复读,Thread1开启事务并获取并修改序列号,此时在Thread1未提交事务之前Thread2开启事务并获取序列号。此时两个线程获取到的序列号必然是一致的,这样就会出现订单号重复的问题。
如果更换隔离级别呢?是否能够解决这个问题?
那么加锁呢?
最后我们能得出一个结论。是否进行并发控制要依据该并发操作是否会造成数据安全问题来决定的。好了,下面向大家分享一些在学习工作中对于并发问题的处理思路
由于请求重试导致的并发安全问题
在与第三方系统交互或者微服务内部跨模块交互时,我们通常会采用Http或rpc等方式,并设置最大请求时间以及重试次数。因为我们绝对不允许因为下游服务的异常问题而拖累当前服务的正常运行。而通常情况下,最大请求时间也是根据两个服务之间的实际业务以及下游接口进行多次测试而设定的,一般来说不会随便的出现请求超时的情况。但是一旦下游业务的接口因为某种原因(比如网络卡顿或者出现效率问题)导致请求超时的情况,就很有可能因为上游服务的重试而导致下游服务数据重复的问题。
这种情况从本质上来说也就是个重复消费的问题。我们只需要双方配合做好幂等就好了。
1.首先,如果涉及到前端,比如说点击前端的按钮触发业务并且调用下游服务的业务。这个时候既要考虑前端重复提交也要考虑后端的重复发送以及重复消费问题。前端最常用的方式就是做一个进度条或进行防抖处理,避免一个用户频繁点击按钮。
那么如果是多个用户同时提交同一条数据呢?这个情况主要是在B端业务中出现,比如说多个用户均具有这条数据的修改权限,此时也并发点击按钮提交了这条数据。一般来说,这种情况出现的概率还是极少数的,也不会有多少并发量。因此我们直接采用数据库的乐观锁进行保底控制就好了,只允许一个人操作成功,其他人操作失败并提示该数据已被修改。
public void update(Long id, Integer status) {
// 1.根据ID查询数据
PO po = dao.select(id);
// 2.判断数据的状态是否符合修改要求(这一步主要是应对两个线程都进入Controller层,其中线程1刚好提交事务后,线程2开始事务的情况)
if(!status.equals(po.getStatus())) {
throw new TJCException("数据已被修改,请刷新后重试");
}
// 3.修改数据(启用乐观锁机制,主要应对线程1提交事务之前线程2开启事务的情况)
int i = dao.update("update table set xxx = ?, version = version + 1 where id = ? and version > ?");
if(i == 0) {
throw new TJCException("数据已被修改,请刷新后重试");
}
// 继续执行下面业务
}2.上游服务请求下游服务时,在请求头或消息中添加消息唯一ID。下游服务第一次接收到这个消息后首先将消息保存在缓存中并根据测试结果设置合理的有效期(有效期尽可能比正常请求时间长个一两分钟就好)。这样就可以拦截上述所说的重试导致的重复消费问题。
// 上游服务发送消息
public void request() {
String messageId = "xxxx";
rpc.request(messageId, message);
}
// 下游服务消费消息
public void consume(String messageId, String message) {
// 将messageId存储在redis中, 单机环境也可以直接找个map去存或者存在Guava中
Boolean flag = stringRedisTemplate.opsForValue()
.setIfAbsent(messageId, "1", 60, TimeUnit.SECONDS);
if(!flag) {
log.error("重复消息拦截");
return;
}
// 继续执行下面业务
.....
// 事务完成后(提交/回滚),删除标识
TransactionSynchronizationManager.reGISterSynchronization(new TransactionSynchronizationAdapter() {
@Override
public void afterCompletion(int status) {
stringRedisTemplate.delete(messageId);
}
});
}在这里是否有小伙伴会有这样的一个疑问,如果重复发送的消息中messageId不一致或者上游服务接口本身就被调用了多次怎么办?
(1)首先,我觉得在上游服务接口本身就被调用了多次的情况下,第一点中的第2步骤(判断数据状态)这种方式就可以把它拦截掉。
(2)其次,如果出现重复发送的消息中messageId不一致的情况,我认为这就属于程序员问题了,可以不放在这里进行考虑。如果硬要考虑的话,貌似也没什么更好的办法,那就加锁吧。
顺序递增订单号问题
在开头我们通过引用这个生成订单号的例子分析了一些什么情况下需要进行并发处理问题,并且上面是采用加锁方式处理的。那么是否还有其他的方式比加锁更好一些呢?比较加锁影响吞吐量呀,哈哈。非必要情况下,我是不会进行加锁处理的,除非在定制开发的过程中,用户的要求是能用就行,那就可以偷懒了哈哈,节省时间去摸鱼!!!!
下面给大家分享一些我常用的一种方式:Redis+lua。我们都知道操作内存肯定是比操作数据库要更快一些的,那么我们可以干脆将各个单据的序列号添加到Redis中。并且订单号是根据年月日来进行重置的,所以我们可以将序列号的过期时间设置为24小时。
伪代码如下:
// 序列号的key可以设置为(模块名:orderIndex:订单类型:yyyyMMdd)
String dateFORMat = getCurrentDateFormat("yyyyMMdd");
// key
String key = 模块名 + ":" + orderIndex + ":" + 订单类型 + ":" + dateFormat;
String script = "if (redis.call('exists', KEYS[1]) == 0) then redis.call('setex', KEYS[1], ARGV[1], ARGV[2]) return 1 else return redis.call('incr', KEYS[1]) end";
DefaultRedisScript<Long> defaultRedisScript = new DefaultRedisScript<>();
defaultRedisScript.setResultType(Long.class);
defaultRedisScript.setScriptText(script);
long count = stringRedisTemplate.execute(defaultRedisScript, Arrays.asList(key), (3600 * 24) + "", "1");
我们都清楚,Redis多指令执行是没办法保证原子性的。所以我们要借助Lua脚本将多个Redis执行以脚本的方式执行来保证多指令执行的原子性,再配合Redis基于内存以及单线程执行指令的优势,可以代替锁来赋予功能更大的吞吐量。
计数统计问题
在工作中我还做过这样一个需求。首先通过消息队列接收、主动拉取数据源的方式获取用户在实际业务中产生的源数据并根据设置的规则比对校验生成符合条件的数据保存在数据库中。并且对通过各个维度对生成的数据进行计数统计并推送下游单据。
比如说其中有一个统计维度为“在各个班的工作时间内,根据次数统计符合条件的数据并汇总推送下游单据”。那么要做这项业务,首先我们要对各个班的数据进行分别计数,当前班开始工作时同步开启计数,结束工作时停止计数,当计数器达到设置的标准后,将这些数据进行统计处理后推送下游单据。
根据上面的业务,通常来说有两种方式解决:
最后通过实际的业务分析决定采用Redis+Lua的方式进行处理。只不过这次的Lua要写相对复杂的业务了。
伪代码如下:
public List<Long> countMonitor(Long indexStdId, Long currentTeamClassId, Long
dataid, Integer count) {
StringBuilder countMonitorLua = new StringBuilder();
countMonitorLua.append("if (redis.call('hget', KEYS[1], KEYS[2]) == ARGV[2]) ");
countMonitorLua.append("then ");
countMonitorLua.append(" if (redis.call('hget', KEYS[1], KEYS[3]) == ARGV[3]) ");
countMonitorLua.append(" then ");
countMonitorLua.append(" redis.call('hset', KEYS[1], KEYS[3], 0) ");
countMonitorLua.append(" redis.call('lpush', KEYS[4], ARGV[1]) ");
countMonitorLua.append(" local list = redis.call('lrange', KEYS[4], 0, -1) ");
countMonitorLua.append(" redis.call('del', KEYS[4]) ");
countMonitorLua.append(" return list ");
countMonitorLua.append(" else ");
countMonitorLua.append(" redis.call('lpush', KEYS[4], ARGV[1]) ");
countMonitorLua.append(" redis.call('hincrby', KEYS[1], KEYS[3], 1) ");
countMonitorLua.append(" return {} ");
countMonitorLua.append(" end ");
countMonitorLua.append("else ");
countMonitorLua.append(" redis.call('del', KEYS[4]) ");
countMonitorLua.append(" redis.call('lpush', KEYS[4], ARGV[1]) ");
countMonitorLua.append(" redis.call('hset', KEYS[1], KEYS[3], 1) ");
countMonitorLua.append(" redis.call('hset', KEYS[1], KEYS[2], ARGV[2]) ");
countMonitorLua.append(" if (redis.call('hget', KEYS[1], KEYS[3]) == ARGV[4]) ");
countMonitorLua.append(" then ");
countMonitorLua.append(" redis.call('hset', KEYS[1], KEYS[3], 0) ");
countMonitorLua.append(" local list2 = redis.call('lrange', KEYS[4], 0, -1) ");
countMonitorLua.append(" redis.call('del', KEYS[4]) ");
countMonitorLua.append(" return list2 ");
countMonitorLua.append(" else ");
countMonitorLua.append(" return {} ");
countMonitorLua.append(" end ");
countMonitorLua.append("end ");
DefaultRedisScript<List> defaultRedisScript = new DefaultRedisScript<>();
defaultRedisScript.setResultType(List.class);
defaultRedisScript.setScriptText(countMonitorLua.toString());
List<String> keys = new ArrayList<>();
keys.add(COUNTMONITOR_HASH.replace("${indexStd}", indexStdId.toString()));
keys.add(COUNTMONITOR_HASH_CURRENTTEAMCLASSID);
keys.add(COUNTMONITOR_HASH_COUNT);
keys.add(COUNTMONITOR_LIST.replace("${indexStd}", indexStdId.toString()));
List dataIdList = stringRedisTemplate.execute(defaultRedisScript, keys, gapDataId.toString(), currentTeamClassId.toString(), (count - 1) + "", count + "");
List<Long> collect = null;
if(!gapDataIdList.isEmpty()) {
collect = (List<Long>) gapDataIdList.stream().map(o -> Long.valueOf(o.toString())).collect(Collectors.toList());
}
return collect;
}以上代码是根据我实际的业务代码改编成的伪代码,这个段代码没必要看懂哈,首先是伪代码,其实这个业务比较复杂,我也没写注释。更多的还是分享一下优化的处理思路:
首先计数量是由客户定的,可以设置的很小也可以设置的很大。由于这一点考虑,我将计数分成的两部分,一个是String类型的key做计数器,一个是List类型的key用来记录正在被计数的数据ID。这个List有可能是一个大key。所以我们不会去频繁的读取它的数量进行判断,而是通过读取这个String类型的计数器来校验计数。当计数符合条件后就将List取出来。这样做的好处是节省了频繁读取大key的耗时(实际上Redis读取大Key是非常耗时的,我们在实际开发中要时刻注意这一点)。
总结
总体来说,优化并发问题本质上就是通过优化各种请求的耗时(例如事务的耗时、数据库连接的耗时、http/rpc的耗时)来提升功能的吞吐量,达到用最少的资源浪费处理更多的事情。
我处理并发问题的思路总体上也就是通过同步锁、数据库锁以及唯一约束、Redis单线程的天然优势这三点上进行综合考虑,选择中更适合业务场景的一种处理方式。实际上退一万步说,对于一些B端的业务,用户的需求只是能用就行,那我们做定制开发的小伙伴们就直接一个锁就解决问题了,这样何乐而不为呢?还能节省出更多的摸鱼时间!哈哈!!!
但对于做通用产品来说,还是要尽可能的考虑更大的吞吐量。有的小伙伴可能有有疑问,Redis通常的使用规范不是只允许存放那些查询频率非常高的热点数据吗?嗯,那是对于大多数C端互联网项目而言的。而B端项目普遍业务要更加的复杂,而在这个基础上我们要想追求更大的吞吐量,其实用一用Redis也未尝不可哈。毕竟B端的QPS相比于C端来说要根本不在一个数量级。就算是偶然出现几个大Key,能有什么关系呢,只要我们设计的严谨一点,能够把控整体的资源就好啦。
以上就是Java中对于并发问题的处理思路分享的详细内容,更多关于Java处理并发问题的资料请关注编程网其它相关文章!
--结束END--
本文标题: Java中对于并发问题的处理思路分享
本文链接: https://lsjlt.com/news/197299.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0