目录前言Go语言定义适用范围一、基础语法1.1 变量、常量、nil与零值、方法、包、可见性、指针1.1.1 变量声明1.1.2 常量声明1.1.3 nil与零值1.1.4 方法、包1
Go(又称 golang)是 Google 的 Robert Griesemer,Rob Pike 及 Ken Thompson 开发的一种静态、强类型、编译型语言。Go 语言语法与 C 相近,但功能上有:内存安全,GC,结构形态及 CSP-style 并发计算。
本篇文章适用于学习过其他面向对象语言(Java、PHP),但没有学过Go语言的初学者。文章主要从Go与Java功能上的对比来阐述Go语言的基础语法、面向对象编程、并发与错误四个方面。
Go语言的基础语法与常规的编程语言基本类似,所不同的有声明变量的方式,数组、切片、字典的概念及功能与Java不太相同,不过Java中这些数据结构都可以通过类比功能的方式在Go中使用。
Go语言中有两种方式
1.使用var关键字声明,且需要注意的是,与大多数强类型语言不同,Go语言的声明变量类型位于变量名称的后面。Go语句结束不需要分号。
var num int
var result string = "this is result"2.使用:=赋值。
num := 3 等同于 var num int = 3
其中变量的类型会根据右侧的值进行匹配,例如"3"会匹配为int,"3.0"会匹配为float64,"result"会匹配为string。
使用const来声明一个常量,一个常量在声明后不可改变。
const laugh string = "go"只声明未赋值的变量,其值为nil。类似于java中的“null” 。
没有明确初始值的变量声明会被赋予它们的 零值。
零值是:
0,false,""(空字符串)。使用func关键字来定义一个方法,后面跟方法名,然后是参数,返回值(如果有的话,没有返回值则不写)。
func MethodName(p1 Parm, p2 Parm) int{}
//学习一个语言应该从Hello World开始!
package main
import "fmt"
func main() {
fmt.Println("Hello World!")// Hello World!
fmt.Println(add(3, 5)) //8
var sum = add(3, 5)
}
func add(a int, b int) int{
return a+b;
}Go 函数与其他编程语言一大不同之处在于支持多返回值,这在处理程序出错的时候非常有用。例如,如果上述 add 函数只支持非负整数相加,传入负数则会报错。
//返回值只定义了类型 没有定义返回参数
func add(a, b int) (int, error) {
if a < 0 || b < 0 {
err := errors.New("只支持非负整数相加")
return 0, err
}
a *= 2
b *= 3
return a + b, nil
}
//返回值还定义了参数 这样可以直接return 并且定义的参数可以直接使用 return时只会返回这两个参数
func add1(a, b int) (z int, err error) {
if a < 0 || b < 0 {
err := errors.New("只支持非负整数相加")
return //实际返回0 err 因为z只定义没有赋值 则nil值为0
}
a *= 2
b *= 3
z = a + b
return //返回 z err
}
func main() {
x, y := -1, 2
z, err := add(x, y)
if err != nil {
fmt.Println(err.Error())
return
}
fmt.Printf("add(%d, %d) = %d\n", x, y, z)
}func myfunc(numbers ...int) {
for _, number := range numbers {
fmt.Println(number)
}
}
slice := []int{1, 2, 3, 4, 5}
//使用...将slice打碎传入
myfunc(slice...)在 Go 语言中,无论是变量、函数还是类属性和成员方法,它们的可见性都是以包为维度的,而不是类似传统面向编程那样,类属性和成员方法的可见性封装在所属的类中,然后通过 private、protected 和 public 这些关键字来修饰其可见性。
Go 语言没有提供这些关键字,不管是变量、函数,还是自定义类的属性和成员方法,它们的可见性都是根据其首字母的大小写来决定的,如果变量名、属性名、函数名或方法名首字母大写,就可以在包外直接访问这些变量、属性、函数和方法,否则只能在包内访问,因此 Go 语言类属性和成员方法的可见性都是包一级的,而不是类一级的。
假如说一个名为domain的文件夹下有3个.go文件,则三个文件中的package都应为domain,其中程序的入口main方法所在的文件,包为main
//定义了此文件属于 main 包
package main
//通过import导入标注库中包
import "fmt"
func main() {
fmt.Println("Hello World!")// Hello World!
fmt.Println(add(3, 5)) //8
var sum = add(3, 5)
}
func add(a int, b int) int{
return a+b;
}对于学过C语言来说,指针还是比较熟悉的,我所理解的指针,其实就是一个在内存中实际的16进制的地址值,引用变量的值通过此地址去内存中取出对应的真实值。
func main() {
i := 0
//使用&来传入地址
fmt.Println(&i) //0xc00000c054
var a, b int = 3 ,4
//传入 0xc00000a089 0xc00000a090
fmt.Println(add(&a, &b))
}
//使用*来声明一个指针类型的参数与使用指针
func add(a *int, b *int)int{
//接收到 0xc00000a089 0xc00000a090
//前往 0xc00000a089位置查找具体数据 并取赋给x
x := *a
//前往 0xc00000a090位置查找具体数据 并取赋给y
y := *b
return x+y
}与Java语言的if基本相同
// if
if condition {
// do something
}
// if...else...
if condition {
// do something
} else {
// do something
}
// if...else if...else...
if condition1 {
// do something
} else if condition2 {
// do something else
} else {
// catch-all or default
}sum := 0
//普通for循环
for i := 1; i <= 100; i++ {
sum += i
}
//无限循环
for{
sum++
if sum = 100{
break;
}
}
//带条件的循环
for res := sum+1; sum < 15{
sum++
res++
}
//使用kv循环一个map或一个数组 k为索引或键值 v为值 k、v不需要时可以用_带替
for k, v := range a {
fmt.Println(k, v)
}score := 100
switch score {
case 90, 100:
fmt.Println("Grade: A")
case 80:
fmt.Println("Grade: B")
case 70:
fmt.Println("Grade: C")
case 65:
fmt.Println("Grade: D")
default:
fmt.Println("Grade: F")
}数组功能与Java语言类似,都是长度不可变,并且可以使用多维数组,也可以通过arrays[i]来存储或获取值。
//声明
var nums [3]int
//声明并初始化
var nums = [3]int{1,2,3} <==> nums:=[3]int{1,2,3}
//使用
for sum := 0, i := 0;i<10{
sum += nums[i]
i++
}
//修改值
num[0] = -1数组使用较为简单,但是存在着难以解决的问题:长度固定 。
例如当我们在程序中需要一个数据结构来存储获取到的所有用户,因为用户数量是会随着时间变化的,但是数组其长度却不可改变,所以数组并不适合存储长度会发生改变的数据。因此在Go语言中通过使用切片来解决以上问题。
切片相比于Java来说是一种全新的概念。在Java中,对于不定长的数据存储结构,可以使用List接口来完成操作,例如有ArrayList与LinkList,这些接口可以实现数据的随时添加与获取,并没有对长度进行限制。但是在Go中不存在这样的接口,而是通过切片(Slice)来完成不定长的数据长度存储。
切片与数组最大的不同就是切片不用声明长度。但是切片与数组并非毫无关系,数组可以看作是切片的底层数组,而切片则可以看作是数组某个连续片段的引用。切片可以只使用数组的一部分元素或者整个数组来创建,甚至可以创建一个比所基于的数组还要大的切片:
切片的长度就是它所包含的元素个数。
切片的容量是从它的第一个元素开始数,到其底层数组元素末尾的个数。
切片 s 的长度和容量可通过表达式 len(s) 和 cap(s) 来获取。
切片的长度从功能上类比与Java中List的size(),即通过len(slice)来感知切片的长度,即可对len(slice)进行循环,来动态控制切片内的具体内容。切片的容量在实际开发中运用不多,了解其概念即可。
//声明一个数组
var nums =[3]int{1, 2, 3}
//0.直接声明
var slice =[]int{0, 1, 2}
//1.从数组中引用切片 其中a:b是指包括a但不包括b
var slice1 = nums[0:2] //{1,2}
//如果不写的则默认为0(左边)或最大值(右边)
var slice2 = slice1[:2] <==> var slice2 = slice1[0:] <==>var slice2 = slice1[:]
//2.使用make创建Slice 其中int为切片类型,4为其长度,5为容量
slice3 := make([]int, 5)
slice4 := make([]int, 4, 5)//使用append向切片中动态的添加元素
func append(s []T, vs ...T) []T
slice5 := make([]int, 4, 5) //{0, 0, 0, 0}
slice5 = append(slice5, 1) //{0,0,0,0,1}
//删除第一个0
sliece5 = slice5[1:]模拟上述提到的问题使用切片解决方案
//声明切片
var userIds = []int{}
//模拟获取所有用户ID
for i := 0; i< 100{
userIds = append(userIdS, i);
i++;
}
//对用户信息进行处理
for k,v := range userIds{
userIds[k] = v++
}字典也可称为 ‘键值对’ 或 ‘key-value’,是一种常用的数据结构,Java中有各种Map接口,常用的有HashMap等。在Go中通过使用字典来实现键值对的存储,字典是无序的,所以不会根据添加顺序来保证数据的顺序。
//string为键类型,int为值类型
maps := map[string]int{
"java" : 1,
"go" : 2,
"python" : 3,
}
//还可以通过make来创建字典 100为其初始容量 超出可扩容
maps = make(map[string]int, 100)//直接使用
fmt.Println(maps["java"]) //1
//赋值
maps["go"] = 4
//取值 同时判断map中是否存在该键 ok为bool型
value, ok := maps["one"]
if ok { // 找到了
// 处理找到的value
}
//删除
delete(testMap, "four")众所周知,在面向对象的语言中,一个类应该具有属性、构造方法、成员方法三种结构,Go语言也不例外。
Go语言中并没有明确的类的概念,只有struct关键字可以从功能上类比为 面向对象语言中的“类” 。比如要定义一个学生类,可以这么做:
type Student struct {
id int
name string
male bool
score float64
}//定义了一个学生类,属性有id name等,每个属性的类型都在其后面
//定义学生类的构造方法
func NewStudent(id uint, name string, male bool, score float64) *Student {
return &Student{id, name, male, score}
}
//实例化一个类对象
student := NewStudent(1, "学院君", 100)
fmt.Println(student)Go中的成员方法声明与其他语言不大相同。以Student类为例,
//在方法名前,添加对应的类,即可认为改方法为该类的成员方法。
func (s Student) GetName() string {
return s.name
}
//注意这里的Student是带了*的 这是因为在方法传值过程中 存在着值传递与引用传递 即指针的概念 当使用值传递时 编译器会为该参数创建一个副本传入 因此如果对副本进行修改其实是不生效的 因为在执行完此方法后该副本会被销毁 所以此处应该是用*Student 将要修改的对象指针传入 修改值才能起作用
func (s *Student) SetName(name string) {
//这里其实是应该使用(*s).name = name,因为对于一个地址来说 其属性是没意义的 不过这样使用也是可以的 因为编译器会帮我们自动转换
s.name = name
}接口在 Go 语言中有着至关重要的地位,如果说 goroutine 和 channel 是支撑起 Go 语言并发模型的基石,那么接口就是 Go 语言整个类型系统的基石。Go 语言的接口不单单只是接口,下面就让我们一步步来探索 Go 语言的接口特性。
和类的实现相似,Go 语言的接口和其他语言中提供的接口概念完全不同。以 Java、php 为例,接口主要作为不同类之间的契约(Contract)存在,对契约的实现是强制的,体现在具体的细节上就是如果一个类实现了某个接口,就必须实现该接口声明的所有方法,这个叫「履行契约」:
// 声明一个'iTemplate'接口
interface iTemplate
{
public function setVariable($name, $var);
public function gethtml($template);
}
// 实现接口
// 下面的写法是正确的
class Template implements iTemplate
{
private $vars = array();
public function setVariable($name, $var)
{
$this->vars[$name] = $var;
}
public function getHtml($template)
{
foreach($this->vars as $name => $value) {
$template = str_replace('{' . $name . '}', $value, $template);
}
return $template;
}
}这个时候,如果有另外有一个接口 iTemplate2 声明了与 iTemplate 完全一样的接口方法,甚至名字也叫 iTemplate,只不过位于不同的命名空间下,编译器也会认为上面的类 Template 只实现了 iTemplate 而没有实现 iTemplate2 接口。
这在我们之前的认知中是理所当然的,无论是类与类之间的继承,还是类与接口之间的实现,在 Java、PHP 这种单继承语言中,存在着严格的层级关系,一个类只能直接继承自一个父类,一个类也只能实现指定的接口,如果没有显式声明继承自某个父类或者实现某个接口,那么这个类就与该父类或者该接口没有任何关系。
我们把这种接口称为侵入式接口,所谓「侵入式」指的是实现类必须明确声明自己实现了某个接口。这种实现方式虽然足够明确和简单明了,但也存在一些问题,尤其是在设计标准库的时候,因为标准库必然涉及到接口设计,接口的需求方是业务实现类,只有具体编写业务实现类的时候才知道需要定义哪些方法,而在此之前,标准库的接口就已经设计好了,我们要么按照约定好的接口进行实现,如果没有合适的接口需要自己去设计,这里的问题就是接口的设计和业务的实现是分离的,接口的设计者并不能总是预判到业务方要实现哪些功能,这就造成了设计与实现的脱节。
接口的过分设计会导致某些声明的方法实现类完全不需要,如果设计的太简单又会导致无法满足业务的需求,这确实是一个问题,而且脱离了用户使用场景讨论这些并没有意义,以 PHP 自带的 SessionHandlerInterface 接口为例,该接口声明的接口方法如下:
SessionHandlerInterface {
abstract public close ( void ) : bool
abstract public destroy ( string $session_id ) : bool
abstract public gc ( int $maxlifetime ) : int
abstract public open ( string $save_path , string $session_name ) : bool
abstract public read ( string $session_id ) : string
abstract public write ( string $session_id , string $session_data ) : bool
}用户自定义的 Session 管理器需要实现该接口,也就是要实现该接口声明的所有方法,但是实际在做业务开发的时候,某些方法其实并不需要实现,比如如果我们基于 Redis 或 Memcached 作为 Session 存储器的话,它们自身就包含了过期回收机制,所以 gc 方法根本不需要实现,又比如 close 方法对于大部分驱动来说,也是没有什么意义的。
正是因为这种不合理的设计,所以在编写 PHP 类库中的每个接口时都需要纠结以下两个问题(Java 也类似):
SessionHandlerInterface,有没有必要拆分成多个更细分的接口,以适应不同实现类的需要?接下我们来看看 Go 语言的接口是如何避免这些问题的。
在 Go 语言中,类对接口的实现和子类对父类的继承一样,并没有提供类似 implement 这种关键字显式声明该类实现了哪个接口,一个类只要实现了某个接口要求的所有方法,我们就说这个类实现了该接口。
例如,我们定义了一个 File 类,并实现了 Read()、Write()、Seek()、Close() 四个方法:
type File struct {
// ...
}
func (f *File) Read(buf []byte) (n int, err error)
func (f *File) Write(buf []byte) (n int, err error)
func (f *File) Seek(off int64, whence int) (pos int64, err error)
func (f *File) Close() error假设我们有如下接口(Go 语言通过关键字 interface 来声明接口,以示和结构体类型的区别,花括号内包含的是待实现的方法集合):
type IFile interface {
Read(buf []byte) (n int, err error)
Write(buf []byte) (n int, err error)
Seek(off int64, whence int) (pos int64, err error)
Close() error
}
type IReader interface {
Read(buf []byte) (n int, err error)
}
type IWriter interface {
Write(buf []byte) (n int, err error)
}
type ICloser interface {
Close() error
}尽管 File 类并没有显式实现这些接口,甚至根本不知道这些接口的存在,但是我们说 File 类实现了这些接口,因为 File 类实现了上述所有接口声明的方法。当一个类的成员方法集合包含了某个接口声明的所有方法,换句话说,如果一个接口的方法集合是某个类成员方法集合的子集,我们就认为该类实现了这个接口。
与 Java、PHP 相对,我们把 Go 语言的这种接口称作非侵入式接口,因为类与接口的实现关系不是通过显式声明,而是系统根据两者的方法集合进行判断。这样做有两个好处:
这样一来,就完美地避免了传统面向对象编程中的接口设计问题。
对于任何一个优秀的语言来说,并发处理的能力都是决定其优劣的关键。在Go语言中,通过Goroutine来实现并发的处理。
func say(s string) {
fmt.Println(s)
}
func main() {
//通过 go 关键字新开一个协程
go say("world")
say("hello")
}Go语言中没有像Java那么多的锁来限制资源同时访问,只提供了Mutex来进行同步操作。
//给类SafeCounter添加锁
type SafeCounter struct {
v map[string]int
mux sync.Mutex
}
// Inc 增加给定 key 的计数器的值。
func (c *SafeCounter) Inc(key string) {
//给该对象上锁
c.mux.Lock()
// Lock 之后同一时刻只有一个 goroutine 能访问 c.v
c.v[key]++
//解锁
c.mux.Unlock()
}多协程之间通过Channel进行通信,从功能上可以类比为Java的volatile关键字。
ch := make(chan int) 声明一个int型的Channel,两个协程之间可以通过ch进行int数据通信。
通过Channel进行数据传输。
ch <- v // 将 v 发送至信道 ch。
v := <-ch // 从 ch 接收值并赋予 v。package main
import "fmt"
func sum(s []int, c chan int) {
sum := 0
for _, v := range s {
sum += v
}
c <- sum // 将和送入 c
}
//对于main方法来说 相当于就是开启了一个协程
func main() {
s := []int{7, 2, 8, -9, 4, 0}
c := make(chan int)
//通过go关键字开启两个协程 将chaneel当做参数传入
go sum(s[:len(s)/2], c)
go sum(s[len(s)/2:], c)
//通过箭头方向获取或传入信息
x, y := <-c, <-c // 从 c 中接收
fmt.Println(x, y, x+y)
}Go 语言错误处理机制非常简单明了,不需要学习了解复杂的概念、函数和类型,Go 语言为错误处理定义了一个标准模式,即 error 接口,该接口的定义非常简单:
type error interface {
Error() string
}其中只声明了一个 Error() 方法,用于返回字符串类型的错误消息。对于大多数函数或类方法,如果要返回错误,基本都可以定义成如下模式 —— 将错误类型作为第二个参数返回:
func Foo(param int) (n int, err error) {
// ...
}然后在调用返回错误信息的函数/方法时,按照如下「卫述语句」模板编写处理代码即可:
n, err := Foo(0)
if err != nil {
// 错误处理
} else{
// 使用返回值 n
}非常简洁优雅。
defer用于确保一个方法执行完成之后,无论执行结果是否成功,都要执行defer中的语句。类似于Java中的try..catch..finally用法。例如在文件处理中,无论结果是否成功,都要关闭文件流。
func ReadFile(filename string) ([]byte, error) {
f, err := os.Open(filename)
if err != nil {
return nil, err
}
//无论结果如何 都要关闭文件流
defer f.Close()
var n int64 = bytes.MinRead
if fi, err := f.Stat(); err == nil {
if size := fi.Size() + bytes.MinRead; size > n {
n = size
}
}
return readAll(f, n)
}Go语言中没有太多的异常类,不像Java一样有Error、Exception等错误类型,当然也没有try..catch语句。
Panic(恐慌),意味在程序运行中出现了错误,如果该错误未被捕获的话,就会造成系统崩溃退出。例如一个简单的panic:a := 1/0。
就会引发panic: integer divide by zero。
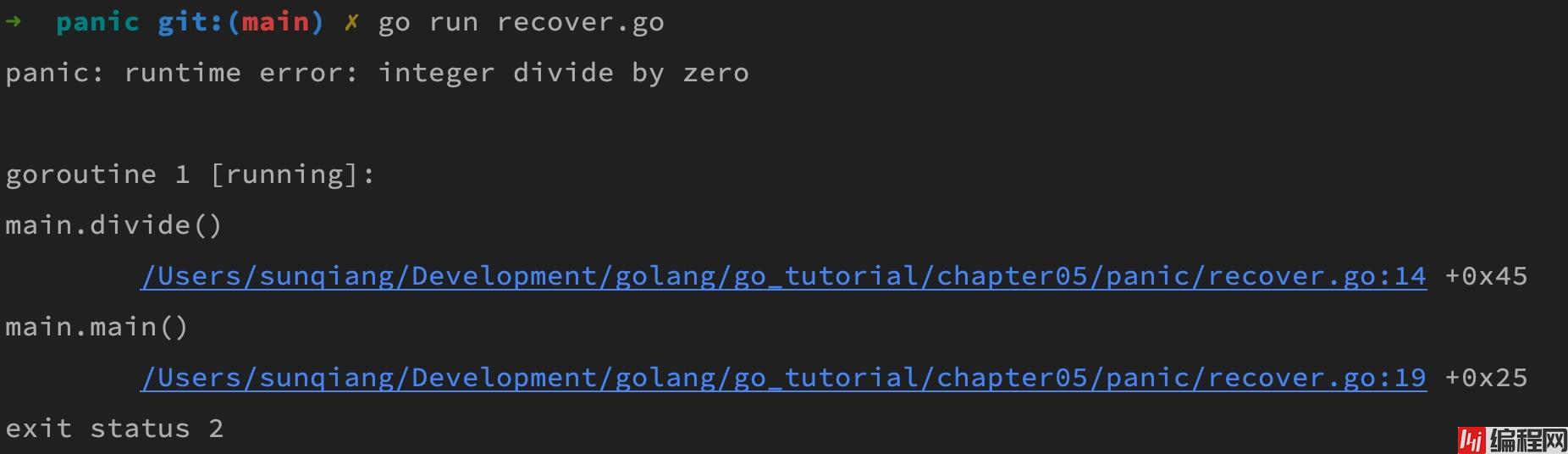
其中第一行表示出问题的协程,第二行是问题代码所在的包和函数,第三行是问题代码的具体位置,最后一行则是程序的退出状态,通过这些信息,可以帮助你快速定位问题并予以解决。
当有可以预见的错误时,又不希望程序崩溃退出,可以使用recover()语句来捕获未处理的panic。recover应当放在defer语句中,且该语句应该在方法中前部,避免未能执行到defer语句时就引发了系统异常退出。
package main
import (
"fmt"
)
func divide() {
//通过defer,确保该方法只要执行完毕都要执行该匿名方法
defer func() {
//进行异常捕获
if err := recover(); err != nil {
fmt.Printf("Runtime panic caught: %v\n", err)
}
}()
var i = 1
var j = 0
k := i / j
fmt.Printf("%d / %d = %d\n", i, j, k)
}
func main() {
divide()
fmt.Println("divide 方法调用完毕,回到 main 函数")
}
可以看到,虽然会出现异常,但我们使用recover()捕获之后,就不会出现系统崩溃退出的情形,而只是将该方法结束。其中fmt.Printf("%d / %d = %d\n", i, j, k)语句并没有执行到,因为代码执行到他的上一步已经出现异常导致该方法提前结束。
4 recover
当有可以预见的错误时,又不希望程序崩溃退出,可以使用recover()语句来捕获未处理的panic。recover应当放在defer语句中,且该语句应该在方法中前部,避免未能执行到defer语句时就引发了系统异常退出。
package main
import (
"fmt"
)
func divide() {
//通过defer,确保该方法只要执行完毕都要执行该匿名方法
defer func() {
//进行异常捕获
if err := recover(); err != nil {
fmt.Printf("Runtime panic caught: %v\n", err)
}
}()
var i = 1
var j = 0
k := i / j
fmt.Printf("%d / %d = %d\n", i, j, k)
}
func main() {
divide()
fmt.Println("divide 方法调用完毕,回到 main 函数")
}可以看到,虽然会出现异常,但我们使用recover()捕获之后,就不会出现系统崩溃退出的情形,而只是将该方法结束。其中fmt.Printf("%d / %d = %d\n", i, j, k)语句并没有执行到,因为代码执行到他的上一步已经出现异常导致该方法提前结束。
通过以上的学习,大家可以以使用为目的的初步了解到go的基础语法,但是仅凭本文想要学明白go是完全不够的。例如go的最大优势之一“协程”,由于文章目的就没有特别详细展开,有兴趣的同学可以继续学习。
到此这篇关于通过与Java功能上的对比来学习Go语言的文章就介绍到这了,更多相关对比Java来学习Go语言内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 通过与Java功能上的对比来学习Go语言
本文链接: https://lsjlt.com/news/196116.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-04-05
2024-04-05
2024-04-05
2024-04-04
2024-04-05
2024-04-05
2024-04-05
2024-04-05
2024-04-04
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0