Python 官方文档:入门教程 => 点击学习
目录1、前言2、成员变量的设定3、构造方法4、hash方法以及阈值判断方法5、put方法6、resize 方法7、get 方法1、前言 上期讲解了 HashMap 和 HashSet
上期讲解了 HashMap 和 HashSet 的一些相关源码,本期我们就来简单的模拟实现一下 HashMap,当然肯定没有源码那么的复杂,但是简单的结构还是要去实现一下的,当然,这也是数据结构课程中最后一起了,后续博主也会带来 Mysql基础,和 Java EE 一些相关的内容。如果数据结构在学习的过程中,感到特别困难的话,记得多画图,多调试。
public class MyHashMap<K, V> {
private Entry<K, V>[] table; //哈希表
private int size; // 有效数据个数
private static final float DEFAULT_LOAD_FACTOR = 0.75f; //负载因子设定
private static final int DEFAULT_CAPACITY = 6; //默认容量
// 节点
public static class Entry<K, V> {
private K key;
private V value;
private Entry<K, V> next;
public Entry(K key, V value) {
this.key = key;
this.value = value;
}
}
}这里我们采用数组来存储我们的数据,而每个数组的元素是 Entry 这样的节点,Entry 中包含一个 next 引用,用来存放下一个节点,从而实现数组中每个元素可以是一个链表的结构,那么大概是这样的一个结构:

通常我们画数组都是横过来画的,只不过这次我们把数组竖过来画的,这样能更清晰看到链表的结构,从美观上也更漂亮。
简而言之,我们今天实现的结构就是数组元素中放链表的结构,当然涉及到了泛型的知识,如果对泛型还不够了解,可以看下博主 JavaSE 系列泛型的博客。
public MyHashMap() {
this.table = (Entry<K, V>[])new Entry[DEFAULT_CAPACITY];
this.size = 0;
}
public MyHashMap(int capacity) {
this.table = (Entry<K, V>[])new Entry[capacity];
this.size = capacity;
}因为是模拟实现,我们就尽可能的简化,体现出 HashMap 底层的结构即可,这我们就默认令 HashMap 的大小为6,也有一个带参数的构造方法,可以指定哈希表的大小。
有了上述的准备工作,我们这里就可以来实现下主要的几个方法了,主要实现 put,get,resize(扩容),hash 这些方法。
这里我们简单设计一下即可,就获取对象的 hashCode % 哈希表的长度即可:
private int hash(K key) {
return (key == null) ? 0 : key.hashCode() % table.length;
}判断是否达到阈值,也就是是否超过设定的负载因子了,就需要考虑扩容的情况,上期介绍到,求负载因子:哈希表的长度 / 元素个数,有了这样的公式,那自然就好判断是否到达了阈值了:
private boolean loadFactor() {
return size * 1.0 / table.length >= DEFAULT_LOAD_FACTOR;
}在 jdk1.7 及之前链表采用的是头插的方式,JDK1.8 及以后采用的是尾插方式,那么我们就来模拟实现一下尾插的一个逻辑。
这里思考插入时的两种情况:
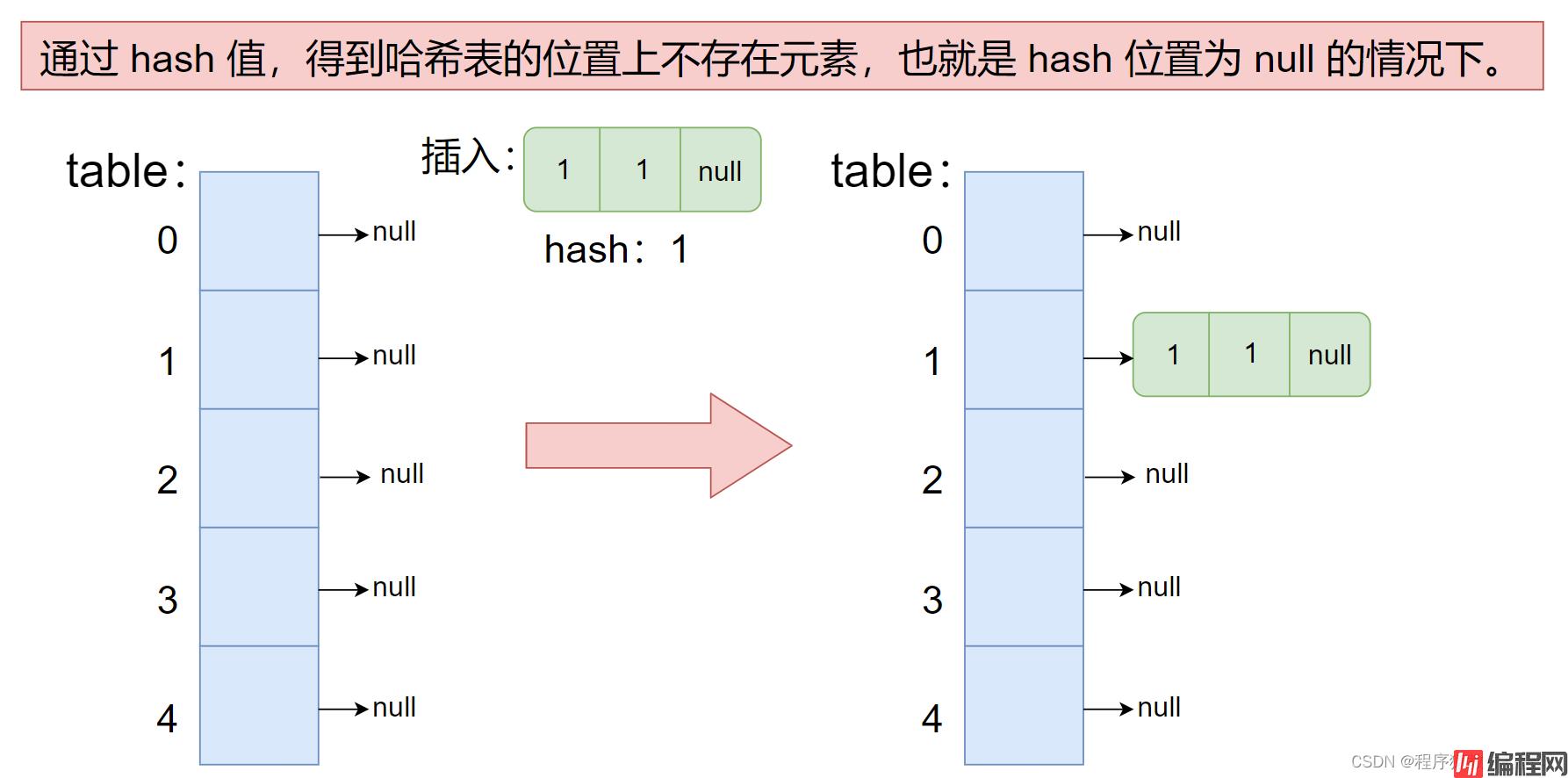
1. 通过 hash 值,得到哈希表的位置上不存在元素,也就是 hash 位置为 null 的情况下。
直接在当前哈希表元素 new 一个节点插入即可。
我们就按照上述的两种情况来进行插入元素。
2. 通过 hash 值,得到哈希表的位置上已经存在元素了,也就是 hash 位置 不为 null 的情况下。


分析上述的情况,也有图解的情况,接下来就可以来实现我们的代码了:
public V put(K key, V value) {
return putVal(hash(key), key, value);
}
private V putVal(int hash, K key, V value) {
// 通过 hash 值, 找到对应位置
Entry<K, V> cur = table[hash];
Entry<K, V> prev = null;
if (cur == null) {
table[hash] = new Entry<>(key, value);
} else {
while (cur != null) {
// 碰到相同值的情况
if (cur.key.equals(key)) {
cur.value = value; //更新下value值
return value;
}
prev = cur;
cur = cur.next;
}
// prev 后面插入节点
prev.next = new Entry<>(key, value);
}
size++;
// 判断是否超过了阈值考虑扩容问题。
if (loadFactor()) {
resize();
}
return value;
}这里我是采用 prev 记录 cur 的前一个节点,当 cur 为 null 就结束循环了,进行尾插,当然你也可也当 cur.next 为 null,结束循环,最后使得 cur.next = new Entry<>(key,value) 也是可以的。
这里每插入一个元素,都需要判断是否超过了设定的 0.75 的负载因子了,如果超过的话,就需要重新调整哈希表的大小。
给哈希表扩容的目的就是减少冲突的概率,但是这里得考虑到一个问题,可以直接扩容吗?我们 hash 函数设置是 key.hashCode % table.length,那么如果哈希表的长度改变了,之前表中元素 key 对应的 hash 值也会发生改变,所以我们通过新的 hash 值,不一定能找到之前元素的位置了。所以扩容之后,原来表中所有元素的位置都要通过新的 hash 值放入新的位置上。
private void resize() {
// 重新扩容势必会考虑到一个问题, 重新 hash 的问题
// 即现在表中的元素, 要通过新的 hash 值, 放入扩容后新的位置上
// 二倍式扩容
Entry<K, V>[] oldTable = table;
table = (Entry<K, V>[])new Entry[table.length * 2];
// 将 oldTable 的数据通过新的 hash, 拷贝进 table 中
copyData(oldTable);
}
private void copyData(Entry<K, V>[] oldTable) {
// 遍历这个 oldTable 将数据拷贝进他 table 中
for (int i = 0; i < oldTable.length; i++) {
Entry<K, V> node = oldTable[i];
while (node != null) {
// 不能直接将 node 插入进去, 因为 node.next 后面可能还有其他元素
// 所以我们要拷贝一份新的 node 进行插入
Entry<K, V> insertNode = new Entry<>(node.key, node.value);
int index = hash(node.key); // node要被hash到的新位置
Entry<K, V> cur = table[index];
// table当前位置没有元素, 直接插入该节点作为链表的头节点
if (cur == null) {
table[index] = insertNode;
} else {
Entry<K, V> prev = null;
// 如果当前数组下标已经有元素了, 就遍历数组中链表往后找
while (cur != null) {
prev = cur;
cur = cur.next;
}
prev.next = insertNode;
}
// 插入 oldTable[i] 当前链表中节点后, node 往后走, 判断还有没有节点需要重新 hash 插入
node = node.next;
}
}
}表中的每个元素是一个链表,但是需要对个元素进行重新 hash,不能直接移动整条链表,只能拿出每个元素,分别重新 hash 放入新的位置上,所以这里我采取将老节点复制出来进行重新hash。
这里我也写了一个测试样例,来证明该代码上下文代码结合跑起来扩容后是会重新 hash 放入新的位置的:
public static void main(String[] args) {
MyHashMap<Integer, Integer> map = new MyHashMap<>();
map.put(1, 1);
map.put(17, 2);
map.put(21, 3);
map.put(11, 4);
System.out.println("扩容前: ");
System.out.println(map);
map.put(13, 5);
System.out.println("扩容后: ");
System.out.println(map);
}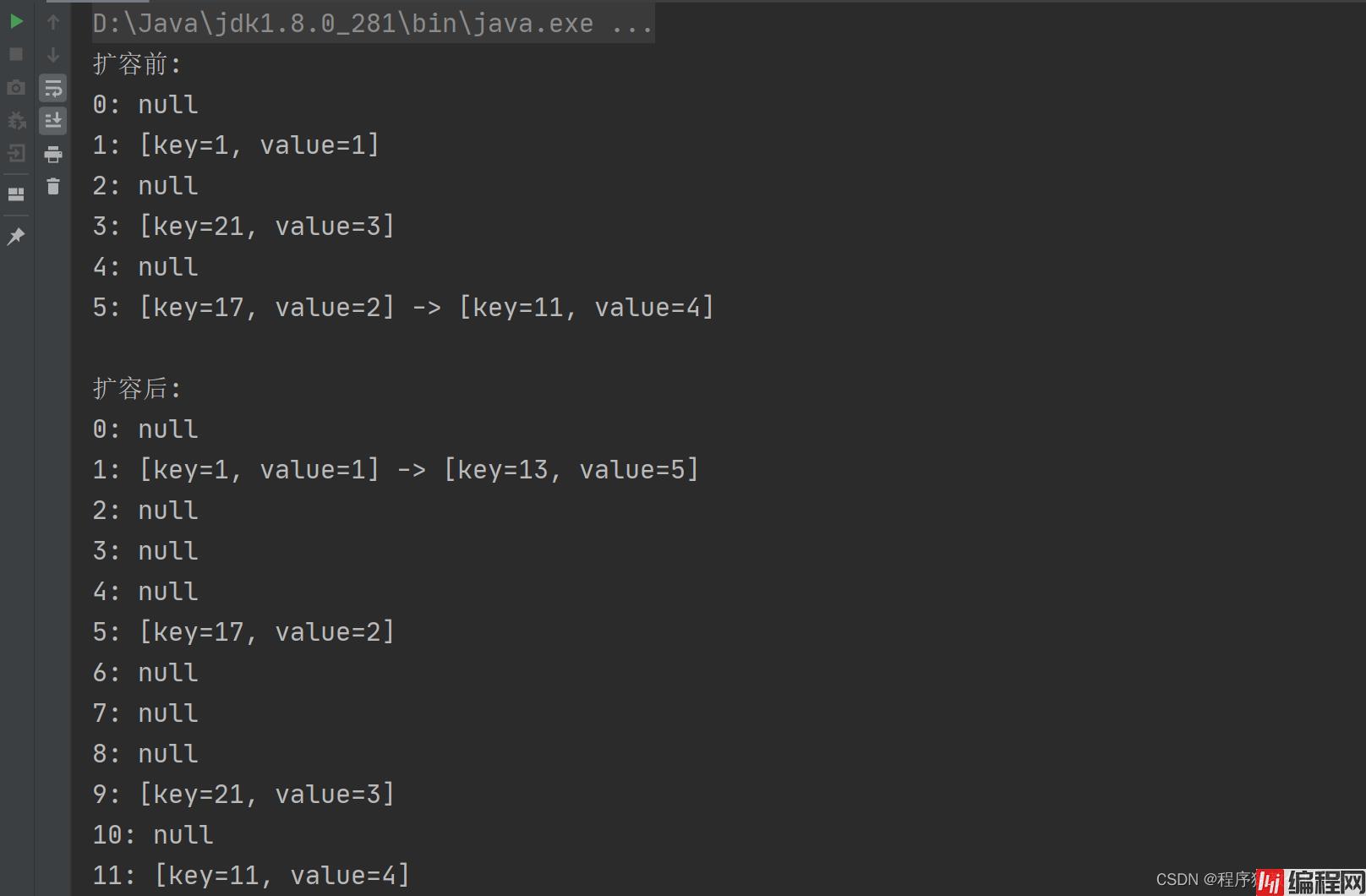
由于默认数组大小是 6,当插入完第五个元素后,则会达到阈值,就需要扩容了,这里我重写了 toString 方法,能看到打印结果就是模拟出数组加链表结构的打印,很明显能看到,扩容前,5 下标位置有 key=17 和 key=11 两个元素,而扩容后 5 下标只剩下 key = 17 一个元素了,而 key=11 则被重新 hash 到了 11 位置下。
这个方法就比较简单了,通过传过来的 key 返回对应 key 的 value值,利用传过来 key 通过 hash 函数获取 index 位置,这个位置可能没有元素,可能是一条链表,但链表中也可能不存在key,也可能存在 key,如果 index 位置没有元素,或者遍历 index 位置都没找到 key,那么就返回 null,找到了即返回 key 对应的 value 值即可。代码如下:
public V get(K key) {
// 通过 hash 获取当前 key 所在的位置
int index = hash(key);
// 通过 index 位置找到 key 对应的 value
Entry<K, V> cur = table[index];
while (cur != null) {
if (cur.key.equals(key)) {
return cur.value;
}
cur = cur.next;
}
return null;
}这次模拟实现 HashMap 相较于源码我们还是简单了很多,主要是练习数组加链表这样的一个结构,和练习重新hash 的一个问题。那么 Java 实现数据结构初阶的内容到此就告一段落了
到此这篇关于Java模拟实现HashMap算法流程详解的文章就介绍到这了,更多相关Java HashMap内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Java模拟实现HashMap算法流程详解
本文链接: https://lsjlt.com/news/195240.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0