Python 官方文档:入门教程 => 点击学习
第1章 基本的图像操作和处理 1.1 PIL:python图像处理类库 1.1.1 转换图像格式——save()函数 1.1.2 创建缩略图 1.1.3 复制并粘贴图像区域 1.1.4 调整尺寸和旋转 1.2 Matpl
PIL(Python Imaging Library,图像处理库)提供了通用的图像处理功能,以及大量有用的基本图像操作。PIL库已经集成在Anaconda库中,推荐使用Anaconda,简单方便,常用库都已经集成。
PIL简明教程
from PIL import Image
from pylab import *
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
figure()
pil_im = Image.open('E:\python\Python Computer Vision\Image data\empire.jpg')
gray()
subplot(121)
title(u'原图',fontproperties=font)
axis('off')
imshow(pil_im)
pil_im = Image.open('E:\python\Python Computer Vision\Image data\empire.jpg').convert('L')
subplot(122)
title(u'灰度图',fontproperties=font)
axis('off')
imshow(pil_im)
show()
save()函数from PCV.tools.imtools import get_imlist #导入原书的PCV模块
from PIL import Image
import os
import pickle
filelist = get_imlist('E:/python/Python Computer Vision/test jpg/') #获取convert_images_fORMat_test文件夹下的图片文件名(包括后缀名)
imlist = open('E:/python/Python Computer Vision/test jpg/imlist.txt','wb+')
#将获取的图片文件列表保存到imlist.txt中
pickle.dump(filelist,imlist) #序列化
imlist.close()
for infile in filelist:
outfile = os.path.splitext(infile)[0] + ".png" #分离文件名与扩展名
if infile != outfile:
try:
Image.open(infile).save(outfile)
except IOError:
print ("cannot convert", infile)
其中,test jpg文件夹是作者自己建立的文件夹,存放测试的**.jpg图像,源代码证添加了部分代码以便将获取的图像文件名保存下来,同时将所有的图像转化为.png格式,运行程序后的结果如下:

PIL中的open()函数用于创建PIL图像对象,sace()方法用于保存如下到指定文件名的文件夹,上述过程将后缀变为.png,但文件名不变
利用PIL可以很容易的创建缩略图,设置缩略图的大小,并用元组保存起来,调用thumnail()方法即可生成缩略图。创建缩略图的代码见下面。
例如创建最长边为128像素的缩略图,可以使用:
pil_im.thumbnail((128,128))调用crop()方法即可从一幅图像中进行区域拷贝,拷贝出区域后,可以对区域进行旋转等变换。
box=(100,100,400,400)
region=pil_im.crop(box)目标区域由四元组来指定,坐标依次为(左,上,右,下),PIL中指定坐标系的左上角坐标为(0,0),可以旋转后利用paste()放回去,具体实现如下:
region=region.transpose(Image.ROTATE_180)
pil_im.paste(region,box)resize()方法,参数是一个元组,用来指定新图像的大小:out=pil_im.resize((128,128))rotate()方法,逆时针方式表示角度out=pil_im.rotate(45)上述操作的代码如下:
from PIL import Image
from pylab import *
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
figure()
# 显示原图
pil_im = Image.open('E:/python/Python Computer Vision/Image data/empire.jpg')
print(pil_im.mode, pil_im.size, pil_im.format)
subplot(231)
title(u'原图', fontproperties=font)
axis('off')
imshow(pil_im)
# 显示灰度图
pil_im = Image.open('E:/python/Python Computer Vision/Image data/empire.jpg').convert('L')
gray()
subplot(232)
title(u'灰度图', fontproperties=font)
axis('off')
imshow(pil_im)
# 复制并粘贴区域
pil_im = Image.open('E:/python/Python Computer Vision/Image data/empire.jpg')
box = (100, 100, 400, 400)
region = pil_im.crop(box)
region = region.transpose(Image.ROTATE_180)
pil_im.paste(region, box)
subplot(233)
title(u'复制粘贴区域', fontproperties=font)
axis('off')
imshow(pil_im)
# 缩略图
pil_im = Image.open('E:/python/Python Computer Vision/Image data/empire.jpg')
size = 128, 128
pil_im.thumbnail(size)
print(pil_im.size)
subplot(234)
title(u'缩略图', fontproperties=font)
axis('off')
imshow(pil_im)
pil_im.save('E:/python/Python Computer Vision/Image data/empire thumbnail.jpg')# 保存缩略图
#调整图像尺寸
pil_im=Image.open('E:/python/Python Computer Vision/Image data/empire thumbnail.jpg')
pil_im=pil_im.resize(size)
print(pil_im.size)
subplot(235)
title(u'调整尺寸后的图像',fontproperties=font)
axis('off')
imshow(pil_im)
#旋转图像45°
pil_im=Image.open('E:/python/Python Computer Vision/Image data/empire thumbnail.jpg')
pil_im=pil_im.rotate(45)
subplot(236)
title(u'旋转45°后的图像',fontproperties=font)
axis('off')
imshow(pil_im)
show()运行结果如下:

当在处理数学及绘图或在图像上描点、画直线、曲线时,Matplotlib是一个很好的绘图库,它比PIL库提供了更有力的特性。
matplotlib教程
from PIL import Image
from pylab import *
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
# 读取图像到数组中
im = array(Image.open('E:/python/Python Computer Vision/Image data/empire.jpg'))
figure()
# 绘制有坐标轴的
subplot(121)
imshow(im)
x = [100, 100, 400, 400]
y = [200, 500, 200, 500]
# 使用红色星状标记绘制点
plot(x, y, 'r*')
# 绘制连接两个点的线(默认为蓝色)
plot(x[:2], y[:2])
title(u'绘制empire.jpg', fontproperties=font)
# 不显示坐标轴的
subplot(122)
imshow(im)
x = [100, 100, 400, 400]
y = [200, 500, 200, 500]
plot(x, y, 'r*')
plot(x[:2], y[:2])
axis('off')
title(u'绘制empire.jpg', fontproperties=font)
show()
# show()命令首先打开图形用户界面(GUI),然后新建一个窗口,该图形用户界面会循环阻断脚本,然后暂停,
# 直到最后一个图像窗口关闭。每个脚本里,只能调用一次show()命令,通常相似脚本的结尾调用。

绘图时还有很多可选的颜色和样式,如表1-1,1-2,1-3所示,应用例程如下:
plot(x,y) #默认为蓝色实线
plot(x,y,'Go-') #带有圆圈标记的绿线
plot(x,y,'ks:') #带有正方形标记的黑色虚线| 符号 | 颜色 |
|---|---|
| ‘b’ | 蓝色 |
| ‘g’ | 绿色 |
| ‘r’ | 红色 |
| ‘c’ | 青色 |
| ‘m’ | 品红 |
| ‘y’ | 黄色 |
| ‘k’ | 黑色 |
| ‘w’ | 白色 |
| 符号 | 线型 |
|---|---|
| ‘-‘ | 实线 |
| ‘–’ | 虚线 |
| ‘:’ | 点线 |
| 符号 | 标记 |
|---|---|
| ‘.’ | 点 |
| ‘o’ | 圆圈 |
| ’s’ | 正方形 |
| ‘*’ | 星型 |
| ‘+’ | 加号 |
| ‘*’ | 叉号 |
from PIL import Image
from pylab import *
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
# 打开图像,并转成灰度图像
im = array(Image.open('E:/python/Python Computer Vision/Image data/empire.jpg').convert('L'))
# 新建一个图像
figure()
subplot(121)
# 不使用颜色信息
gray()
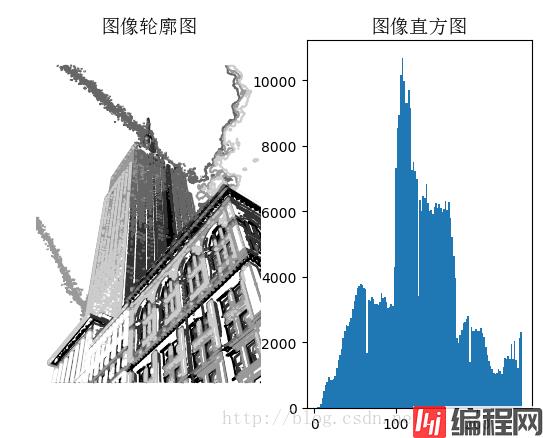
# 在原点的左上角显示轮廓图像
contour(im, origin='image')
axis('equal')
axis('off')
title(u'图像轮廓图', fontproperties=font)
subplot(122)
# 利用hist来绘制直方图
# 第一个参数为一个一维数组
# 因为hist只接受一维数组作为输入,所以要用flatten()方法将任意数组按照行优先准则转化成一个一维数组
# 第二个参数指定bin的个数
hist(im.flatten(), 128)
title(u'图像直方图', fontproperties=font)
# plt.xlim([0,250])
# plt.ylim([0,12000])
show()
有时候用户需要和应用进行交互,比如在图像中用点做标识,或者在一些训练数据中进行注释,PyLab提供了一个很简介好用的函数gitput()来实现交互式标注。
from PIL import Image
from pylab import *
im = array(Image.open('E:/python/Python Computer Vision/Image data/empire.jpg'))
imshow(im)
print('Please click 3 points')
x = ginput(3)
print('you clicked:', x)
show()
输出:
you clicked:
[(118.4632306896458, 177.58271393177051),
(118.4632306896458, 177.58271393177051),
(118.4632306896458, 177.58271393177051)]
上面代码先读取empire.jpg图像,显示读取的图像,然后用ginput()交互注释,这里设置的交互注释数据点设置为3个,用户在注释后,会将注释点的坐标打印出来。
NumPy在线文档
NumPy是Python一个流行的用于科学计算包。它包含了很多诸如矢量、矩阵、图像等其他非常有用的对象和线性代数函数。
在前面图像的示例中,我们将图像用array()函数转为NumPy数组对象,但是并没有提到它表示的含义。数组就像列表一样,只不过它规定了数组中的所有元素必须是相同的类型,除非指定以外,否则数据类型灰按照数据类型自动确定。
举例如下:
from PIL import Image
from pylab import *
im = array(Image.open('E:/python/Python Computer Vision/Image data/empire.jpg'))
print (im.shape, im.dtype)
im = array(Image.open('E:/python/Python Computer Vision/Image data/empire.jpg').convert('L'),'f')
print (im.shape, im.dtype)输出:
(800, 569, 3) uint8
(800, 569) float32解释:
第一个元组表示图像数组大小(行、列、颜色通道)
第二个字符串表示数组元素的数据类型,因为图像通常被编码为8位无符号整型;
1. uint8:默认类型
2. float32:对图像进行灰度化,并添加了'f'参数,所以变为浮点型value=im[i,j,k]im[i,:] = im[j,:] #将第j行的数值赋值给第i行
im[:,j] = 100 #将第i列所有数值设为100
im[:100,:50].sum() #计算前100行、前50列所有数值的和
im[50:100,50:100] #50~100行,50~100列,不包含第100行和100列
im[i].mean() #第i行所有数值的平均值
im[:,-1] #最后一列
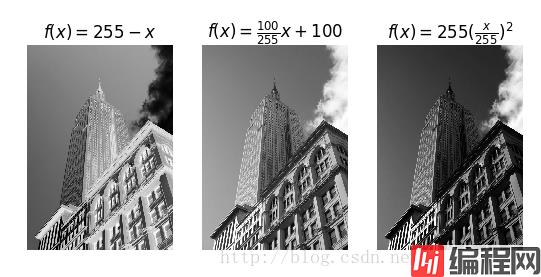
im[-2,:]/im[-2] #倒数第二行将图像读入NumPy数组对象后,我们可以对它们执行任意数学操作,一个简单的例子就是图像的灰度变换,考虑任意函数,它将0~255映射到自身,也就是输出区间和输入区间相同。
举例如下:
from PIL import Image
from numpy import *
from pylab import *
im=array(Image.open('E:/python/Python Computer Vision/Image data/empire.jpg').convert('L'))
print(int(im.min()),int(im.max()))
im2=255-im #对图像进行反向处理
print(int(im2.min()),int(im2.max())) #查看最大/最小元素
im3=(100.0/255)*im+100 #将图像像素值变换到100...200区间
print(int(im3.min()),int(im3.max()))
im4=255.0*(im/255.0)**2 #对像素值求平方后得到的图像
print(int(im4.min()),int(im4.max()))
figure()
gray()
subplot(131)
imshow(im2)
axis('off')
title(r'$f(x)=255-x$')
subplot(132)
imshow(im3)
axis('off')
title(r'$f(x)=\frac{100}{255}x+100$')
subplot(133)
imshow(im4)
axis('off')
title(r'$f(x)=255(\frac{x}{255})^2$')
show()输出:
3 255
0 252
101 200
0 255
pil_im=Image.fromarray(im)pil_im=Image.fromarray(uint8(im))NumPy数组将成为我们对图像及数据进行处理的最主要工具,但是调整矩阵大小并没有一种简单的方法。我们可以用PIL图像对象转换写一个简单的图像尺寸调整函数:
def imresize(im,sz):
""" Resize an image array using PIL. """
pil_im = Image.fromarray(uint8(im))
return array(pil_im.resize(sz))上面定义的调整函数,在imtools.py中你可以找到它。
直方图均衡化指将一幅图像的灰度直方图变平,使得变换后的图像中每个灰度值的分布概率都相同,该方法是对灰度值归一化的很好的方法,并且可以增强图像的对比度。
下面的函数是直方图均衡化的具体实现:
def histeq(im,nbr_bins=256):
""" 对一幅灰度图像进行直方图均衡化"""
# 计算图像的直方图
imhist,bins = histogram(im.flatten(),nbr_bins,normed=True)
cdf = imhist.cumsum() # 累积分布函数
cdf = 255 * cdf / cdf[-1] # 归一化
# 此处使用到累积分布函数cdf的最后一个元素(下标为-1),其目的是将其归一化到0~1范围
# 使用累积分布函数的线性插值,计算新的像素值
im2 = interp(im.flatten(),bins[:-1],cdf)
return im2.reshape(im.shape), cdf解释:
该函数有两个参数
函数返回值
程序实现:
from PIL import Image
from pylab import *
from PCV.tools import imtools
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
im = array(Image.open('E:/python/Python Computer Vision/Image data/empire.jpg').convert('L'))
# 打开图像,并转成灰度图像
#im = array(Image.open('../data/AquaTermi_lowcontrast.JPG').convert('L'))
im2, cdf = imtools.histeq(im)
figure()
subplot(2, 2, 1)
axis('off')
gray()
title(u'原始图像', fontproperties=font)
imshow(im)
subplot(2, 2, 2)
axis('off')
title(u'直方图均衡化后的图像', fontproperties=font)
imshow(im2)
subplot(2, 2, 3)
axis('off')
title(u'原始直方图', fontproperties=font)
#hist(im.flatten(), 128, cumulative=True, normed=True)
hist(im.flatten(), 128, normed=True)
subplot(2, 2, 4)
axis('off')
title(u'均衡化后的直方图', fontproperties=font)
#hist(im2.flatten(), 128, cumulative=True, normed=True)
hist(im2.flatten(), 128, normed=True)
show()结果:
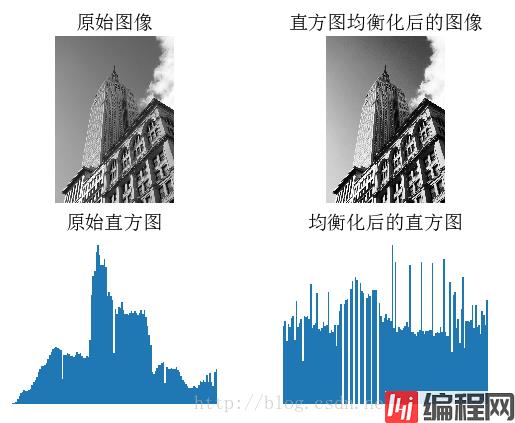
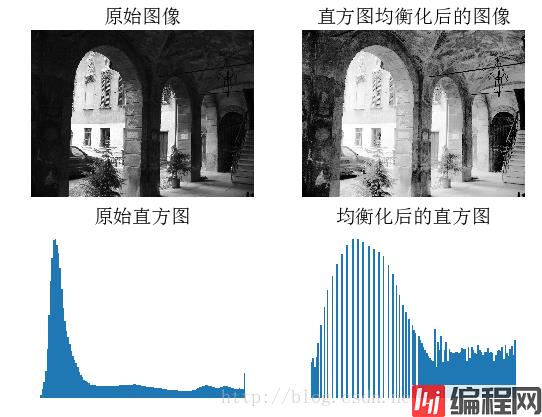
对图像取平均是一种图像降噪的简单方法,经常用于产生艺术效果。假设所有的图像具有相同的尺寸,我们可以对图像相同位置的像素相加取平均,下面是一个演示对图像取平均的例子:
def compute_average(imlist):
""" 计算图像列表的平均图像"""
# 打开第一幅图像,将其存储在浮点型数组中
averageim = array(Image.open(imlist[0]), 'f')
for imname in imlist[1:]:
try:
averageim += array(Image.open(imname))
except:
print imname + '...skipped'
averageim /= len(imlist)
# 返回uint8 类型的平均图像
return array(averageim, 'uint8')
注意:有可能因为某些图像打不开而导致平均的结果只是某一幅自身或某两幅图像的平均
PCA(Principal Component Analysis,主成分分析)是一个非常有用的降维技巧。它可以在使用尽可能少维数的前提下,尽量多地保持训练数据的信息,在此意义上是一个最佳技巧。即使是一幅 100×100 像素的小灰度图像,也有 10 000 维,可以看成 10 000 维空间中的一个点。一兆像素的图像具有百万维。由于图像具有很高的维数,在许多计算机视觉应用中,我们经常使用降维操作。PCA 产生的投影矩阵可以被视为将原始坐标变换到现有的坐标系,坐标系中的各个坐标按照重要性递减排列。
为了对图像数据进行 PCA 变换,图像需要转换成一维向量表示。我们可以使用 NumPy 类库中的flatten() 方法进行变换。
将变平的图像堆积起来,我们可以得到一个矩阵,矩阵的一行表示一幅图像。在计算主方向之前,所有的行图像按照平均图像进行了中心化。我们通常使用 SVD(Singular Value Decomposition,奇异值分解)方法来计算主成分;但当矩阵的维数很大时,SVD 的计算非常慢,所以此时通常不使用 SVD 分解。
下面就是 PCA 操作的代码:
from PIL import Image
from numpy import *
def pca(X):
""" 主成分分析:
输入:矩阵X ,其中该矩阵中存储训练数据,每一行为一条训练数据
返回:投影矩阵(按照维度的重要性排序)、方差和均值"""
# 获取维数
num_data,dim = X.shape
# 数据中心化
mean_X = X.mean(axis=0)
X = X - mean_X
if dim>num_data:
# PCA- 使用紧致技巧
M = dot(X,X.T) # 协方差矩阵
e,EV = linalg.eigh(M) # 特征值和特征向量
tmp = dot(X.T,EV).T # 这就是紧致技巧
V = tmp[::-1] # 由于最后的特征向量是我们所需要的,所以需要将其逆转
S = sqrt(e)[::-1] # 由于特征值是按照递增顺序排列的,所以需要将其逆转
for i in range(V.shape[1]):
V[:,i] /= S
else:
# PCA- 使用SVD 方法
U,S,V = linalg.svd(X)
V = V[:num_data] # 仅仅返回前nun_data 维的数据才合理
# 返回投影矩阵、方差和均值
return V,S,mean_X该函数首先通过减去每一维的均值将数据中心化,然后计算协方差矩阵对应最大特征值的特征向量,此时可以使用简明的技巧或者 SVD 分解。这里我们使用了 range() 函数,该函数的输入参数为一个整数 n,函数返回整数 0…(n-1) 的一个列表。你也可以使用 arange() 函数来返回一个数组,或者使用 xrange() 函数返回一个产生器(可能会提升速度)。我们在本书中贯穿使用range() 函数。
如果数据个数小于向量的维数,我们不用 SVD 分解,而是计算维数更小的协方差矩阵 XXT 的特征向量。通过仅计算对应前 k(k 是降维后的维数)最大特征值的特征向量,可以使上面的 PCA 操作更快。由于篇幅所限,有兴趣的读者可以自行探索。矩阵 V 的每行向量都是正交的,并且包含了训练数据方差依次减少的坐标方向。
我们接下来对字体图像进行 PCA 变换。fontimages.zip 文件包含采用不同字体的字符 a 的缩略图。所有的 2359 种字体可以免费下载 2。假定这些图像的名称保存在列表 imlist 中,跟之前的代码一起保存传在 pca.py 文件中,我们可以使用下面的脚本计算图像的主成分:
import pickle
from PIL import Image
from numpy import *
from pylab import *
from PCV.tools import imtools,pca
# Uses sparse pca codepath
# 获取图像列表和尺寸
imlist=imtools.get_imlist('E:/python/Python Computer Vision/Image data/fontimages/a_thumbs')
# open ont image to get the size
im=array(Image.open(imlist[0]))
# get the size of the images
m,n=im.shape[:2]
# get the number of images
imnbr=len(imlist)
print("The number of images is %d" % imnbr)
# create matrix to store all flattened images
immatrix = array([array(Image.open(imname)).flatten() for imname in imlist],'f')
# PCA降维
V,S,immean=pca.pca(immatrix)
# 保存均值和主成分
#f = open('../ch01/font_pca_modes.pkl', 'wb')
#pickle.dump(immean,f)
#pickle.dump(V,f)
#f.close()
# Show the images (mean and 7 first modes)
# This gives figure 1-8 (p15) in the book.
figure()
gray()
subplot(241)
axis('off')
imshow(immean.reshape(m,n))
for i in range(7):
subplot(2,4,i+2)
imshow(V[i].reshape(m,n))
axis('off')
show()
注意,这些图像在拉成一维表示后,必须用reshape()函数将它重新转换回来。运行上面代码,可得原书P15 Figure1-8中的结果,即:

如果想要保存一些结果或者数据以方便后续使用,Python 中的 pickle 模块非常有用。pickle模块可以接受几乎所有的 Python 对象,并且将其转换成字符串表示,该过程叫做封装(pickling)。从字符串表示中重构该对象,称为拆封(unpickling)。这些字符串表示可以方便地存储和传输。
我们来看一个例子。假设想要保存上一节字体图像的平均图像和主成分,可以这样来完成:
# 保存均值和主成分数据
f = open('font_pca_modes.pkl','wb')
pickle.dump(immean,f)
pickle.dump(V,f)
f.close()在上述例子中,许多对象可以保存到同一个文件中。pickle 模块中有很多不同的协议可以生成 .pkl 文件;如果不确定的话,最好以二进制文件的形式读取和写入。在其他 Python 会话中载入数据,只需要如下使用 load() 方法:
# 载入均值和主成分数据
f = open('font_pca_modes.pkl','rb')
immean = pickle.load(f)
V = pickle.load(f)
f.close()注意,载入对象的顺序必须和先前保存的一样。Python 中有个用 C 语言写的优化版本,叫做cpickle 模块,该模块和标准 pickle 模块完全兼容。关于 pickle 模块的更多内容,参见pickle 模块文档页 Http://docs.python.org/library/pickle.html。
在本书接下来的章节中,我们将使用 with 语句处理文件的读写操作。这是 Python 2.5 引入的思想,可以自动打开和关闭文件(即使在文件打开时发生错误)。下面的例子使用 with() 来实现保存和载入操作:
# 打开文件并保存
with open('font_pca_modes.pkl', 'wb') as f:
pickle.dump(immean,f)
pickle.dump(V,f)和
# 打开文件并载入
with open('font_pca_modes.pkl', 'rb') as f:
immean = pickle.load(f)
V = pickle.load(f)上面的例子乍看起来可能很奇怪,但 with() 确实是个很有用的思想。如果你不喜欢它,可以使用之前的 open 和 close 函数。
作为 pickle 的一种替代方式,NumPy 具有读写文本文件的简单函数。如果数据中不包含复杂的数据结构,比如在一幅图像上点击的点列表,NumPy 的读写函数会很有用。保存一个数组 x 到文件中,可以使用:
savetxt('test.txt',x,'%i')最后一个参数表示应该使用整数格式。类似地,读取可以使用:
x = loadtxt('test.txt')可以从在线文档了解更多
最后,NumPy 有专门用于保存和载入数组的函数,在线文档中可以查看关于 save()和 load() 的更多内容。
SciPy(http://scipy.org/) 是建立在 NumPy 基础上,用于数值运算的开源工具包。SciPy 提供很多高效的操作,可以实现数值积分、优化、统计、信号处理,以及对我们来说最重要的图像处理功能。
图像的高斯模糊是非常经典的图像卷积例子。本质上,图像模糊就是将(灰度)图像 和一个高斯核进行卷积操作:
其中,*表示卷积,表示标准差为的卷积核
scipy.ndimage.filters该模块可以使用快速一维分离的方式来计算卷积,使用方式如下:
from PIL import Image
from numpy import *
from pylab import *
from scipy.ndimage import filters
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font=FontProperties(fname=r"c:\windows\fonts\SimSun.ttc",size=14)
im=array(Image.open('E:/python/Python Computer Vision/Image data/empire.jpg').convert('L'))
figure()
gray()
axis('off')
subplot(141)
axis('off')
title(u'原图',fontproperties=font)
imshow(im)
for bi,blur in enumerate([2,5,10]):
im2=zeros(im.shape)
im2=filters.gaussian_filter(im,blur)
im2=np.uint8(im2)
imNum=str(blur)
subplot(1,4,2+bi)
axis('off')
title(u'标准差为'+imNum,fontproperties=font)
imshow(im2)
#如果是彩色图像,则分别对三个通道进行模糊
#for bi, blur in enumerate([2, 5, 10]):
# im2 = zeros(im.shape)
# for i in range(3):
# im2[:, :, i] = filters.gaussian_filter(im[:, :, i], blur)
# im2 = np.uint8(im2)
# subplot(1, 4, 2 + bi)
# axis('off')
# imshow(im2)
show()
上面第一幅图为待模糊图像,第二幅用高斯标准差为2进行模糊,第三幅用高斯标准差为5进行模糊,最后一幅用高斯标准差为10进行模糊。关于该模块的使用以及参数选择的更多细节,可以参阅SciPy scipy.ndimage文档
在很多应用中图像强度的变化情况是非常重要的信息。强度的变化可以用灰度图像 (对于彩色图像,通常对每个颜色通道分别计算导数)的 和 方向导数 和 进行描述。
NumPy中的arctan2()函数返回弧度表示的有符号角度,角度的变化区间为
我们可以用离散近似的方式来计算图像的导数。图像导数大多数可以通过卷积简单地实现:
,
对于,通常选择prewitt滤波器或sobel滤波器
这些导数滤波器可以使用scipy.ndimage.filters模块的标准卷积操作来简单实现
from PIL import Image
from pylab import *
from scipy.ndimage import filters
import numpy
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font=FontProperties(fname=r"c:\windows\fonts\SimSun.ttc",size=14)
im=array(Image.open('E:/python/Python Computer Vision/Image data/empire.jpg').convert('L'))
gray()
subplot(141)
axis('off')
title(u'(a)原图',fontproperties=font)
imshow(im)
# sobel derivative filters
imx=zeros(im.shape)
filters.sobel(im,1,imx)
subplot(142)
axis('off')
title(u'(b)x方向差分',fontproperties=font)
imshow(imx)
imy=zeros(im.shape)
filters.sobel(im,0,imy)
subplot(143)
axis('off')
title(u'(c)y方向差分',fontproperties=font)
imshow(imy)
mag=255-numpy.sqrt(imx**2+imy**2)
subplot(144)
title(u'(d)梯度幅值',fontproperties=font)
axis('off')
imshow(mag)
show()

高斯差分:
from PIL import Image
from pylab import *
from scipy.ndimage import filters
import numpy
# 添加中文字体支持
#from matplotlib.font_manager import FontProperties
#font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
def imx(im, sigma):
imgx = zeros(im.shape)
filters.gaussian_filter(im, sigma, (0, 1), imgx)
return imgx
def imy(im, sigma):
imgy = zeros(im.shape)
filters.gaussian_filter(im, sigma, (1, 0), imgy)
return imgy
def mag(im, sigma):
# there's also gaussian_gradient_magnitude()
#mag = numpy.sqrt(imgx**2 + imgy**2)
imgmag = 255 - numpy.sqrt(imgx ** 2 + imgy ** 2)
return imgmag
im = array(Image.open('E:/python/Python Computer Vision/Image data/empire.jpg').convert('L'))
figure()
gray()
sigma = [2, 5, 10]
for i in sigma:
subplot(3, 4, 4*(sigma.index(i))+1)
axis('off')
imshow(im)
imgx=imx(im, i)
subplot(3, 4, 4*(sigma.index(i))+2)
axis('off')
imshow(imgx)
imgy=imy(im, i)
subplot(3, 4, 4*(sigma.index(i))+3)
axis('off')
imshow(imgy)
imgmag=mag(im, i)
subplot(3, 4, 4*(sigma.index(i))+4)
axis('off')
imshow(imgmag)
show()
形态学(或数学形态学)是度量和分析基本形状的图像处理方法的基本框架与集合。形态学通常用于处理二值图像,但是也能够用于灰度图像。二值图像是指图像的每个像素只能取两个值,通常是 0 和 1。二值图像通常是,在计算物体的数目,或者度量其大小时,对一幅图像进行阈值化后的结果。可以从 http://en.wikipedia.org/wiki/Mathematical_morphology 大体了解形态学及其处理图像的方式。
scipy.ndimage 中的 morphology 模块可以实现形态学操作
scipy.ndimage 中的measurements 模块来实现二值图像的计数和度量功能
下面通过一个简单的例子介绍如何使用它们:
from scipy.ndimage import measurements,morphology
# 载入图像,然后使用阈值化操作,以保证处理的图像为二值图像
im = array(Image.open('houses.png').convert('L'))
im = 1*(im<128)
labels, nbr_objects = measurements.label(im)
print "Number of objects:", nbr_objects# 形态学开操作更好地分离各个对象
im_open = morphology.binary_opening(im,ones((9,5)),iterations=2)
labels_open, nbr_objects_open = measurements.label(im_open)
print "Number of objects:", nbr_objects_openbinary_opening() 函数的第二个参数指定一个数组结构元素。
binary_closing() 函数实现相反的操作。
from PIL import Image
from numpy import *
from scipy.ndimage import measurements, morphology
from pylab import *
""" This is the morphology counting objects example in Section 1.4. """
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
# load image and threshold to make sure it is binary
figure()
gray()
im = array(Image.open('E:/python/Python Computer Vision/Image data/houses.png').convert('L'))
subplot(221)
imshow(im)
axis('off')
title(u'原图', fontproperties=font)
im = (im < 128)
labels, nbr_objects = measurements.label(im)
print ("Number of objects:", nbr_objects)
subplot(222)
imshow(labels)
axis('off')
title(u'标记后的图', fontproperties=font)
# morphology - opening to separate objects better
im_open = morphology.binary_opening(im, ones((9, 5)), iterations=2)
subplot(223)
imshow(im_open)
axis('off')
title(u'开运算后的图像', fontproperties=font)
labels_open, nbr_objects_open = measurements.label(im_open)
print ("Number of objects:", nbr_objects_open)
subplot(224)
imshow(labels_open)
axis('off')
title(u'开运算后进行标记后的图像', fontproperties=font)
show()输出:
Number of objects: 45
Number of objects: 48
SciPy 中包含一些用于输入和输出的实用模块。下面介绍其中两个模块:io 和 misc
1.读写.mat文件
如果你有一些数据,或者在网上下载到一些有趣的数据集,这些数据以 Matlab 的 .mat 文件格式存储,那么可以使用 scipy.io 模块进行读取。
data = scipy.io.loadmat('test.mat')上面代码中,data 对象包含一个字典,字典中的键对应于保存在原始 .mat 文件中的变量名。由于这些变量是数组格式的,因此可以很方便地保存到 .mat 文件中。你仅需创建一个字典(其中要包含你想要保存的所有变量),然后使用 savemat() 函数:
data = {}
data['x'] = x
scipy.io.savemat('test.mat',data)因为上面的脚本保存的是数组 x,所以当读入到 Matlab 中时,变量的名字仍为 x。关于scipy.io 模块的更多内容,请参见在线文档。
2.以图像形式保存数组
因为我们需要对图像进行操作,并且需要使用数组对象来做运算,所以将数组直接保存为图像文件 4 非常有用。本书中的很多图像都是这样的创建的。
imsave() 函数:从 scipy.misc 模块中载入。要将数组 im 保存到文件中,可以使用下面的命令:
from scipy.misc import imsave
imsave('test.jpg',im)scipy.misc 模块同样包含了著名的 Lena 测试图像:
lena = scipy.misc.lena()该脚本返回一个 512×512 的灰度图像数组
所有 Pylab 图均可保存为多种图像格式,方法是点击图像窗口中的“保存”按钮。
我们通过一个非常实用的例子——图像的去噪——来结束本章。图像去噪是在去除图像噪声的同时,尽可能地保留图像细节和结构的处理技术。我们这里使用 ROF(Rudin-Osher-Fatemi)去噪模型。该模型最早出现在文献 [28] 中。图像去噪对于很多应用来说都非常重要;这些应用范围很广,小到让你的假期照片看起来更漂亮,大到提高卫星图像的质量。ROF 模型具有很好的性质:使处理后的图像更平滑,同时保持图像边缘和结构信息。
ROF 模型的数学基础和处理技巧非常高深,不在本书讲述范围之内。在讲述如何基于 Chambolle 提出的算法 [5] 实现 ROF 求解器之前,本书首先简要介绍一下 ROF 模型。
降噪综合示例:
from pylab import *
from numpy import *
from numpy import random
from scipy.ndimage import filters
from scipy.misc import imsave
from PCV.tools import rof
""" This is the de-noising example using ROF in Section 1.5. """
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
# create synthetic image with noise
im = zeros((500,500))
im[100:400,100:400] = 128
im[200:300,200:300] = 255
im = im + 30*random.standard_normal((500,500))
U,T = rof.denoise(im,im)
G = filters.gaussian_filter(im,10)
# save the result
#imsave('synth_original.pdf',im)
#imsave('synth_rof.pdf',U)
#imsave('synth_gaussian.pdf',G)
# plot
figure()
gray()
subplot(1,3,1)
imshow(im)
#axis('equal')
axis('off')
title(u'原噪声图像', fontproperties=font)
subplot(1,3,2)
imshow(G)
#axis('equal')
axis('off')
title(u'高斯模糊后的图像', fontproperties=font)
subplot(1,3,3)
imshow(U)
#axis('equal')
axis('off')
title(u'ROF降噪后的图像', fontproperties=font)
show()
其中第一幅图示原噪声图像,中间一幅图示用标准差为10进行高斯模糊后的结果,最右边一幅图是用ROF降噪后的图像。上面原噪声图像是模拟出来的图像,现在我们在真实的图像上进行测试:
from PIL import Image
from pylab import *
from numpy import *
from numpy import random
from scipy.ndimage import filters
from scipy.misc import imsave
from PCV.tools import rof
""" This is the de-noising example using ROF in Section 1.5. """
# 添加中文字体支持
from matplotlib.font_manager import FontProperties
font = FontProperties(fname=r"c:\windows\fonts\SimSun.ttc", size=14)
im = array(Image.open('E:/python/Python Computer Vision/Image data/empire.jpg').convert('L'))
U,T = rof.denoise(im,im)
G = filters.gaussian_filter(im,10)
# save the result
#imsave('synth_original.pdf',im)
#imsave('synth_rof.pdf',U)
#imsave('synth_gaussian.pdf',G)
# plot
figure()
gray()
subplot(1,3,1)
imshow(im)
#axis('equal')
axis('off')
title(u'原噪声图像', fontproperties=font)
subplot(1,3,2)
imshow(G)
#axis('equal')
axis('off')
title(u'高斯模糊后的图像', fontproperties=font)
subplot(1,3,3)
imshow(U)
#axis('equal')
axis('off')
title(u'ROF降噪后的图像', fontproperties=font)
show()
ROF降噪能够保持边缘和图像结构
Number of objects: 45
Number of objects: 48
--结束END--
本文标题: python计算机视觉编程——第一章(基
本文链接: https://lsjlt.com/news/191337.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0