Python 官方文档:入门教程 => 点击学习
python大数据应用简介 简介:目前业界主流存储与分析平台以hadoop为主的开源生态圈,mapReduce作为Hadoop的数据集的并行运算模型,除了提供Java编写MapReduce任务外,还兼容了Streaming方式,可以使用任意
简介:目前业界主流存储与分析平台以hadoop为主的开源生态圈,mapReduce作为Hadoop的数据集的并行运算模型,除了提供Java编写MapReduce任务外,还兼容了Streaming方式,可以使用任意脚本语言来编写MapReduce任务,优点是开发简单且灵活。
yum安装方式:yum install -y java-1.6.0-openjdk*
配置Java环境变量:vi /etc/profile
JAVA_HOME=/usr/lib/JVM/java-1.6.0-openjdk-1.6.0.41.x86_64
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=::$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
使配置文件生效:source /etc/profile export JAVA_HOME=/usr/lib/jvm/java-1.6.0-openjdk-1.6.0.41.x86_64<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/data/tmp/hadoop-${user.name}</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.1:9000</value>
</property>
</configuration><configuration>
<property>
<name>dfs.name.dir</name>
<value>/data/tmp/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/data/hdfs/data</value>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>4096</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration><configuration>
<property>
<name>mapred.job.tracker</name>
<value>192.168.1.1:9001</value>
</property>
</configuration>masters文件
192.168.1.1slaves文件
192.168.1.1
192.168.1.2
192.168.1.3master主机
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50030 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50070 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 9000 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 90001 -j ACCEPTSlave主机
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50075 -j ACCEPT
iptables -I INPUT -s 192.168.1.0/24 -p tcp --dport 50060 -j ACCEPT
iptables -I INPUT -s 192.168.1.1 -p tcp --dport 50010 -j ACCEPT./bin/start-all.sh所示结果如下,表示启动成功
./bin/hadoop jar hadoop-examples-1.2.1.jar pi 10 100所示结果如下,表示配置成功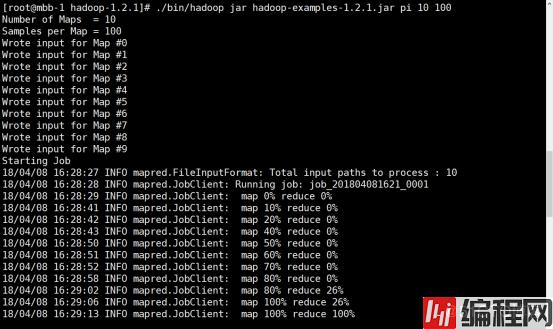
Map/Reduce管理地址:192.168.1.1:50030
HDFS管理地址:192.168.1.1:50070
--结束END--
本文标题: 1、Python大数据应用——部署Had
本文链接: https://lsjlt.com/news/189729.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0