Python 官方文档:入门教程 => 点击学习
No.1 一切皆对象 众所周知,Java中强调“一切皆对象”,但是python中的面向对象比Java更加彻底,因为Python中的类(class)也是对象,函数(function)也是对象,而且Python的代码和模块也都是对象。 Pyt
众所周知,Java中强调“一切皆对象”,但是python中的面向对象比Java更加彻底,因为Python中的类(class)也是对象,函数(function)也是对象,而且Python的代码和模块也都是对象。
# 首先创建一个函数和一个python3.x的新式类
class Demo(object):
def __init__(self):
print("Demo Class")# 定义一个函数
def function():
print("function")# 在Python无论是函数,还是类,都是对象,他们可以赋值给一个变量
class_value = Demo
func_value = function# 并且可以通过变量调用
class_value() # Demo Class
func_value() # function# 将函数和类添加到集合中
obj_list = []
obj_list.append(Demo)
obj_list.append(function)
# 遍历列表
for i in obj_list:
print(i)
# <class '__main__.Demo'>
# <function function at 0x0000020D681B3E18># 定义一个具体函数
def test_func(class_name, func_name):
class_name()
func_name()# 将类名和函数名传入形参列表
test_func(Demo, function)
# Demo Class
# function# 定义函数实现返回类和函数
def test_func2():
return Demo
def test_func3():
return function# 执行函数
test_func2()() # Demo Class
test_func3()() # function在Python中,object的实例是type,object是顶层类,没有基类;type的实例是type,type的基类是object。Python中的内置类型的基类是object,但是他们都是由type实例化而来,具体的值由内置类型实例化而来。在Python2.x的语法中用户自定义的类没有明确指定基类就默认是没有基类,在Python3.x的语法中,指定基类为object。
# object是谁实例化的?
print(type(object)) # <class 'type'>
# object继承自哪个类?
print(object.__bases__) # ()
# type是谁实例化的?
print(type(type)) # <class 'type'>
# type继承自哪个类?
print(type.__bases__) # (<class 'object'>,)
# 定义一个变量
value = 100
# 100由谁实例化?
print(type(value)) # <class 'int'>
# int由谁实例化?
print(type(int)) # <class 'type'>
# int继承自哪个类?
print(int.__bases__) # (<class 'object'>,)# Python 2.x的旧式类
class OldClass():
pass
# Python 3.x的新式类
class NewClass(object):
pass在Python中,对象有3个特征属性:
id()函数进行查看在Python解释器启动时,会创建一个None类型的None对象,并且None对象全局只有一个。
在Python中,迭代类型可以使用循环来进行遍历。
Python中的魔法函数使用双下划线开始,以双下划线结尾。关于详细介绍请看我的文章——《全面总结Python中的魔法函数》。
鸭子类型是程序设计中的推断风格,在鸭子类型中关注对象如何使用而不是类型本身。鸭子类型像多态一样工作但是没有继承。鸭子类型的概念来自于:“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”
# 定义狗类
class Dog(object):
def eat(self):
print("dog is eatting...")
# 定义猫类
class Cat(object):
def eat(self):
print("cat is eatting...")
# 定义鸭子类
class Duck(object):
def eat(self):
print("duck is eatting...")
# 以上Python中多态的体现
# 定义动物列表
an_li = []
# 将动物添加到列表
an_li.append(Dog)
an_li.append(Cat)
an_li.append(Duck)
# 依次调用每个动物的eat()方法
for i in an_li:
i().eat()
# dog is eatting...
# cat is eatting...
# duck is eatting...白鹅类型是指只要 cls 是抽象基类,即 cls 的元类是 abc.ABCMeta ,就可以使用 isinstance(obj, cls) 。
我们可以使用猴子补丁来实现协议,那么什么是猴子补丁呢?
猴子补丁就是在运行时修改模块或类,不去修改源代码,从而实现目标协议接口操作,这就是所谓的打猴子补丁。
Tips:猴子补丁的叫法起源于Zope框架,开发人员在修改Zope的Bug时,经常在程序后面追加更新的部分,这些
杂牌军补丁的英文名字叫做guerilla patch,后来写成Gorllia,接着就变成了monkey。
猴子补丁的主要作用是:
应用案例:假设写了一个很大的项目,处处使用了JSON模块来解析json文件,但是后来发现ujson比json性能更高,修改源代码是要修改很多处的,所以只需要在程序入口加入:
import json
# pip install ujson
import ujson
def monkey_patch_json():
json.__name__ = 'ujson'
json.dumps = ujson.dumps
json.loads = ujson.loads
monkey_patch_json()Python 的抽象基类有一个重要实用优势:可以使用 reGISter 类方法在终端用户的代码中把某个类 “声明” 为一个抽象基类的 “虚拟” 子 类(为此,被注册的类必腨满足抽象其类对方法名称和签名的要求,最重要的是要满足底 层语义契约;但是,开发那个类时不用了解抽象基类,更不用继承抽象基类 。有时,为了让抽象类识别子类,甚至不用注册。要抑制住创建抽象基类的冲动。滥用抽象基类会造成灾难性后果,表明语言太注重表面形式 。
抽象基类的定义与使用
import abc
# 定义缓存类
class Cache(metaclass=abc.ABCMeta):
@abc.abstractmethod
def get(self, key):
pass
@abc.abstractmethod
def set(self, key, value):
pass
# 定义Redis缓存类实现Cache类中的get()和set()方法
class RedisCache(Cache):
def set(self, key):
pass
def get(self, key, value):
pass
值得注意的是:Python 3.0-Python3.3之间,继承抽象基类的语法是class ClassName(metaclass=adc.ABCMeta),其他版本是:class ClassName(abc.ABC)。
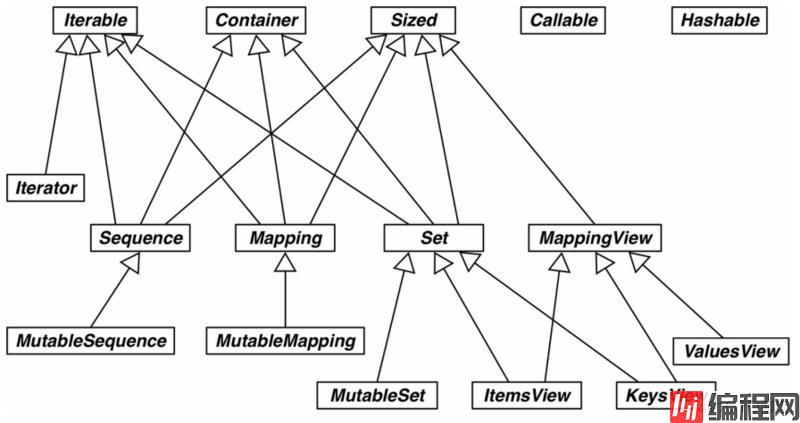
class A(object):
pass
class B(A):
pass
b = B()
print(isinstance(b, B))
print(isinstance(b, A))
print(type(b) is B)
print(type(b) is A)
# True
# True
# True
# False# 此处的类也是模板对象,Python中一切皆对象
class A(object):
#类变量
number = 12
def __init__(self):
# 实例变量
self.number_2 = 13
# 实例变量只能通过类的实例进行调用
print(A.number) # 12
print(A().number) # 12
print(A().number_2) # 13
# 修改模板对象创建的对象的属性,模板对象的属性不会改变
a = A()
a.number = 18
print(a.number) # 18
print(A().number) # 12
print(A.number) # 12
# 修改模板对象的属性,由模板对象创建的对象的属性会改变
A.number = 19
print(A.number) # 19
print(A().number) # 19
object,即使不显式继承也会默认继承自object假定存在以下继承关系:
class D(object):
def say_hello(self):
pass
class E(object):
pass
class B(D):
pass
class C(E):
pass
class A(B, C):
pass采用DFS(深度优先搜索算法)当调用了A的say_hello()方法的时候,系统会去B中查找如果B中也没有找到,那么去D中查找,很显然D中存在这个方法,但是DFS对于以下继承关系就会有缺陷:
class D(object):
pass
class B(D):
pass
class C(D):
def say_hello(self):
pass
class A(B, C):
pass在A的实例对象中调用say_hello方法时,系统会先去B中查找,由于B类中没有该方法的定义,所以会去D中查找,D类中也没有,系统就会认为该方法没有定义,其实该方法在C中定义了。所以考虑使用BFS(广度优先搜索算法),那么问题回到第一个继承关系,假定C和D具备重名方法,在调用A的实例的方法时,应该先在B中查找,理应调用D中的方法,但是使用BFS的时候,C类中的方法会覆盖D类中的方法。在Python 2.3以后的版本中,使用C3算法:
# 获取解析顺序的方法
类名.mro()
类名.__mro__
inspect.getmro(类名)使用C3算法后的第二种继承顺序:
class D(object):
pass
class B(D):
pass
class C(D):
def say_hello(self):
pass
class A(B, C):
pass
print(A.mro()) # [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>]使用C3算法后的第一种继承顺序:
class D(object):
pass
class E(object):
pass
class B(D):
pass
class C(E):
pass
class A(B, C):
pass
print(A.mro())
# [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.D'>, <class '__main__.C'>, <class '__main__.E'>, <class 'object'>]在这里仅介绍了算法的作用和演变历史,关于深入详细解析,请看我的其他文章——《从Python继承谈起,到C3算法落笔》。
class Demo(object):
# 类方法
@claSSMethod
def class_method(cls, number):
pass
# 静态方法
@staticmethod
def static_method(number):
pass
# 对象方法/实例方法
def object_method(self, number):
pass实例方法只能通过类的实例来调用;静态方法是一个独立的、无状态的函数,紧紧依托于所在类的命名空间上;类方法在为了获取类中维护的数据,比如:
class Home(object):
# 房间中人数
__number = 0
@classmethod
def add_person_number(cls):
cls.__number += 1
@classmethod
def get_person_number(cls):
return cls.__number
def __new__(self):
Home.add_person_number()
# 重写__new__方法,调用object的__new__
return super().__new__(self)
class Person(Home):
def __init__(self):
# 房间人员姓名
self.name = 'name'
# 创建人员对象时调用Home的__new__()方法
tom = Person()
print(type(tom)) # <class '__main__.Person'>
alice = Person()
bob = Person()
test = Person()
print(Home.get_person_number())Python中使用双下划线+属性名称实现类似于静态语言中的private修饰来实现数据封装。
class User(object):
def __init__(self, number):
self.__number = number
self.__number_2 = 0
def set_number(self, number):
self.__number = number
def get_number(self):
return self.__number
def set_number_2(self, number2):
self.__number_2 = number2
# self.__number2 = number2
def get_number_2(self):
return self.__number_2
# return self.__number2
u = User(25)
print(u.get_number()) # 25
# 真的类似于Java的反射机制吗?
print(u._User__number) # 25
# 下面又是啥情况。。。想不明白了T_T
u.set_number_2(18)
print(u.get_number_2()) # 18
print(u._User__number_2)
# Anaconda 3.6.3 第一次是:u._User__number_2 第二次是:18
# Anaconda 3.6.5 结果都是 0
# 代码我改成了正确答案,感谢我大哥给我指正错误,我保留了错误痕迹
# 变量名称写错了,算是个写博客突发事故,这问题我找了一天,万分感谢我大哥,我太傻B了,犯了低级错误
# 留给和我一样的童鞋参考我的错我之处吧!
# 正确结果:
# 25 25 18 18自省(introspection)是一种自我检查行为。在计算机编程中,自省是指这种能力:检查某些事物以确定它是什么、它知道什么以及它能做什么。自省向程序员提供了极大的灵活性和控制力。
Python3.x 和 Python2.x 的一个区别是: Python 3 可以使用直接使用 super().xxx 代替 super(type[, object-or-type]).xxx 。
super()函数用来调用MRO(类方法解析顺序表)的下一个类的方法。
在设计上将Mixin类作为功能混入继承自Mixin的类。使用Mixin类实现多重继承应该注意:
class Cat(object):
def eat(self):
print("I can eat.")
def drink(self):
print("I can drink.")
class CatFlyMixin(object):
def fly(self):
print("I can fly.")
class CatJumpMixin(object):
def jump(self):
print("I can jump.")
class Tomcat(Cat, CatFlyMixin):
pass
class PersianCat(Cat, CatFlyMixin, CatJumpMixin):
pass
if __name__ == '__main__':
# 汤姆猫没有跳跃功能
tom = TomCat()
tom.fly()
tom.eat()
tom.drink()
# 波斯猫混入了跳跃功能
persian = PersianCat()
persian.drink()
persian.eat()
persian.fly()
persian.jump()普通的异常捕获机制:
try:
pass
except Exception as err:
pass
else:
pass
finally:
passwith简化了异常捕获写法:
class Demo(object):
def __enter__(self):
print("enter...")
return self
def __exit__(self, exc_type, exc_val, exc_tb):
print("exit...")
def echo_hello(self):
print("Hello, Hello...")
with Demo() as d:
d.echo_hello()
# enter...
# Hello, Hello...
# exit...import contextlib
# 使用装饰器
@contextlib.contextmanager
def file_open(file_name):
# 此处写__enter___函数中定义的代码
print("enter function code...")
yield {}
# 此处写__exit__函数中定义的代码
print("exit function code...")
with file_open("json.json") as f:
pass
# enter function code...
# exit function code...首先看测试用例:
# 创建一个序列类型的对象
my_list = [1, 2, 3]
# 将现有的序列合并到my_list
extend_my_list = my_list + [4, 5]
print(extend_my_list) # [1, 2, 3, 4, 5]
# 将一个元组合并到这个序列
extend_my_list = my_list + (6, 7)
# 抛出异常 TypeError: can only concatenate list (not "tuple") to list
print(extend_my_list)
# 使用另一种方式合并
extend_my_list += (6, 7)
print(extend_my_list) # [1, 2, 3, 4, 5, 6, 7]
# 使用extend()函数进行合并
extend_my_list.extend((7, 8))
print(extend_my_list) # [1, 2, 3, 4, 5, 6, 7, 7, 8]由源代码片段可知:
class MutableSequence(Sequence):
__slots__ = ()
"""All the operations on a read-write sequence.
Concrete subclasses must provide __new__ or __init__,
__getitem__, __setitem__, __delitem__, __len__, and insert().
"""
# extend()方法内部使用for循环来append()元素,它接收一个可迭代序列
def extend(self, values):
'S.extend(iterable) -- extend sequence by appending elements from the iterable'
for v in values:
self.append(v)
# 调用 += 运算的时候就是调用该函数,这个函数内部调用extend()方法
def __iadd__(self, values):
self.extend(values)
return selfimport bisect
my_list = []
bisect.insort(my_list, 2)
bisect.insort(my_list, 9)
bisect.insort(my_list, 5)
bisect.insort(my_list, 5)
bisect.insort(my_list, 1)
# insort()函数返回接收的元素应该插入到指定序列的索引位置
print(my_list) # [1, 2, 5, 5, 9]deque是Python中一个双端队列,能在队列两端以$O(1)$的效率插入数据,位于collections模块中。
from collections import deque
# 定义一个双端队列,长度为3
d = deque(maxlen=3)deque类的源码:
class deque(object):
"""
deque([iterable[, maxlen]]) --> deque object
一个类似列表的序列,用于对其端点附近的数据访问进行优化。
"""
def append(self, *args, **kwargs):
""" 在队列右端添加数据 """
pass
def appendleft(self, *args, **kwargs):
""" 在队列左端添加数据 """
pass
def clear(self, *args, **kwargs):
""" 清空所有元素 """
pass
def copy(self, *args, **kwargs):
""" 浅拷贝一个双端队列 """
pass
def count(self, value):
""" 统计指定value值的出现次数 """
return 0
def extend(self, *args, **kwargs):
""" 使用迭代的方式扩展deque的右端 """
pass
def extendleft(self, *args, **kwargs):
""" 使用迭代的方式扩展deque的左端 """
pass
def index(self, value, start=None, stop=None): __doc__
"""
返回第一个符合条件的索引的值
"""
return 0
def insert(self, index, p_object):
""" 在指定索引之前插入 """
pass
def pop(self, *args, **kwargs): # real signature unknown
""" 删除并返回右端的一个元素 """
pass
def popleft(self, *args, **kwargs): # real signature unknown
""" 删除并返回左端的一个元素 """
pass
def remove(self, value): # real signature unknown; restored from __doc__
""" 删除第一个与value相同的值 """
pass
def reverse(self): # real signature unknown; restored from __doc__
""" 翻转队列 """
pass
def rotate(self, *args, **kwargs): # real signature unknown
""" 向右旋转deque N步, 如果N是个负数,那么向左旋转N的绝对值步 """
pass
def __add__(self, *args, **kwargs): # real signature unknown
""" Return self+value. """
pass
def __bool__(self, *args, **kwargs): # real signature unknown
""" self != 0 """
pass
def __contains__(self, *args, **kwargs): # real signature unknown
""" Return key in self. """
pass
def __copy__(self, *args, **kwargs): # real signature unknown
""" Return a shallow copy of a deque. """
pass
def __delitem__(self, *args, **kwargs): # real signature unknown
""" Delete self[key]. """
pass
def __eq__(self, *args, **kwargs): # real signature unknown
""" Return self==value. """
pass
def __getattribute__(self, *args, **kwargs): # real signature unknown
""" Return getattr(self, name). """
pass
def __getitem__(self, *args, **kwargs): # real signature unknown
""" Return self[key]. """
pass
def __ge__(self, *args, **kwargs): # real signature unknown
""" Return self>=value. """
pass
def __gt__(self, *args, **kwargs): # real signature unknown
""" Return self>value. """
pass
def __iadd__(self, *args, **kwargs): # real signature unknown
""" Implement self+=value. """
pass
def __imul__(self, *args, **kwargs): # real signature unknown
""" Implement self*=value. """
pass
def __init__(self, iterable=(), maxlen=None): # known case of _collections.deque.__init__
"""
deque([iterable[, maxlen]]) --> deque object
A list-like sequence optimized for data accesses near its endpoints.
# (copied from class doc)
"""
pass
def __iter__(self, *args, **kwargs): # real signature unknown
""" Implement iter(self). """
pass
def __len__(self, *args, **kwargs): # real signature unknown
""" Return len(self). """
pass
def __le__(self, *args, **kwargs): # real signature unknown
""" Return self<=value. """
pass
def __lt__(self, *args, **kwargs): # real signature unknown
""" Return self<value. """
pass
def __mul__(self, *args, **kwargs): # real signature unknown
""" Return self*value.n """
pass
@staticmethod # known case of __new__
def __new__(*args, **kwargs): # real signature unknown
""" Create and return a new object. See help(type) for accurate signature. """
pass
def __ne__(self, *args, **kwargs): # real signature unknown
""" Return self!=value. """
pass
def __reduce__(self, *args, **kwargs): # real signature unknown
""" Return state infORMation for pickling. """
pass
def __repr__(self, *args, **kwargs): # real signature unknown
""" Return repr(self). """
pass
def __reversed__(self): # real signature unknown; restored from __doc__
""" D.__reversed__() -- return a reverse iterator over the deque """
pass
def __rmul__(self, *args, **kwargs): # real signature unknown
""" Return self*value. """
pass
def __setitem__(self, *args, **kwargs): # real signature unknown
""" Set self[key] to value. """
pass
def __sizeof__(self): # real signature unknown; restored from __doc__
""" D.__sizeof__() -- size of D in memory, in bytes """
pass
maxlen = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
"""maximum size of a deque or None if unbounded"""
__hash__ = None列表生成式要比操作列表效率高很多,但是列表生成式的滥用会导致代码可读性降低,并且列表生成式可以替换map()和reduce()函数。
# 构建列表
my_list = [x for x in range(9)]
print(my_list) # [0, 1, 2, 3, 4, 5, 6, 7, 8]
# 构建0-8中为偶数的列表
my_list = [x for x in range(9) if(x%2==0)]
print(my_list) # [0, 2, 4, 6, 8]
# 构建0-8为奇数的列表,并将每个数字做平方运算
def function(number):
return number * number
my_list = [function(x) for x in range(9) if x%2!=0]
print(my_list) # [1, 9, 25, 49]生成器表达式就是把列表表达式的中括号变成小括号。
# 构造一个生成器
gen = (i for i in range(9))
# 生成器可以被遍历
for i in gen:
print(i)生成器可以使用list()函数转换为列表:
# 将生成器转换为列表
li = list(gen)
print(li)d = {
'tom': 18,
'alice': 16,
'bob': 20,
}
dict = {key: value for key, value in d.items()}
print(dict) # {'tom': 18, 'alice': 16, 'bob': 20}my_set = {i for i in range(9)}
print(my_set) # {0, 1, 2, 3, 4, 5, 6, 7, 8}Set和Dict的背后实现都是Hash(哈希)表,有的书本上也较散列表。Hash表原理可以参考我的算法与数学博客栏目,下面给出几点总结:
__hash__()函数。defaultdict在dict的基础上添加了default_factroy方法,它的作用是当key不存在的时候自动生成相应类型的value,defalutdict参数可以指定成list、set、int等各种类型。
应用场景:
from collections import defaultdict
my_list = [
("Tom", 18),
("Tom", 20),
("Alice", 15),
("Bob", 21),
]
def_dict = defaultdict(list)
for key, val in my_list:
def_dict[key].append(val)
print(def_dict.items())
# dict_items([('Tom', [18, 20]), ('Alice', [15]), ('Bob', [21])])
# 如果不考虑重复元素可以使用如下方式
def_dict_2 = defaultdict(set)
for key, val in my_list:
def_dict_2[key].add(val)
print(def_dict_2.items())
# dict_items([('Tom', {18, 20}), ('Alice', {15}), ('Bob', {21})])源码:
class defaultdict(Dict[_KT, _VT], Generic[_KT, _VT]):
default_factory = ... # type: Callable[[], _VT]
@overload
def __init__(self, **kwargs: _VT) -> None: ...
@overload
def __init__(self, default_factory: Optional[Callable[[], _VT]]) -> None: ...
@overload
def __init__(self, default_factory: Optional[Callable[[], _VT]], **kwargs: _VT) -> None: ...
@overload
def __init__(self, default_factory: Optional[Callable[[], _VT]],
map: Mapping[_KT, _VT]) -> None: ...
@overload
def __init__(self, default_factory: Optional[Callable[[], _VT]],
map: Mapping[_KT, _VT], **kwargs: _VT) -> None: ...
@overload
def __init__(self, default_factory: Optional[Callable[[], _VT]],
iterable: Iterable[Tuple[_KT, _VT]]) -> None: ...
@overload
def __init__(self, default_factory: Optional[Callable[[], _VT]],
iterable: Iterable[Tuple[_KT, _VT]], **kwargs: _VT) -> None: ...
def __missing__(self, key: _KT) -> _VT: ...
# TODO __reversed__
def copy(self: _DefaultDictT) -> _DefaultDictT: ...OrderDict最大的特点就是元素位置有序,它是dict的子类。OrderDict在内部维护一个字典元素的有序列表。
应用场景:
from collections import OrderedDict
my_dict = {
"Bob": 20,
"Tim": 20,
"Amy": 18,
}
# 通过key来排序
order_dict = OrderedDict(sorted(my_dict.items(), key=lambda li: li[1]))
print(order_dict) # OrderedDict([('Amy', 18), ('Bob', 20), ('Tim', 20)])源码:
class OrderedDict(dict):
'Dictionary that remembers insertion order'
# An inherited dict maps keys to values.
# The inherited dict provides __getitem__, __len__, __contains__, and get.
# The remaining methods are order-aware.
# Big-O running times for all methods are the same as regular dictionaries.
# The internal self.__map dict maps keys to links in a doubly linked list.
# The circular doubly linked list starts and ends with a sentinel element.
# The sentinel element never gets deleted (this simplifies the algorithm).
# The sentinel is in self.__hardroot with a weakref proxy in self.__root.
# The prev links are weakref proxies (to prevent circular references).
# Individual links are kept alive by the hard reference in self.__map.
# Those hard references disappear when a key is deleted from an OrderedDict.
def __init__(*args, **kwds):
'''Initialize an ordered dictionary. The signature is the same as
regular dictionaries. KeyWord argument order is preserved.
'''
if not args:
raise TypeError("descriptor '__init__' of 'OrderedDict' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
try:
self.__root
except AttributeError:
self.__hardroot = _Link()
self.__root = root = _proxy(self.__hardroot)
root.prev = root.next = root
self.__map = {}
self.__update(*args, **kwds)
def __setitem__(self, key, value,
dict_setitem=dict.__setitem__, proxy=_proxy, Link=_Link):
'od.__setitem__(i, y) <==> od[i]=y'
# Setting a new item creates a new link at the end of the linked list,
# and the inherited dictionary is updated with the new key/value pair.
if key not in self:
self.__map[key] = link = Link()
root = self.__root
last = root.prev
link.prev, link.next, link.key = last, root, key
last.next = link
root.prev = proxy(link)
dict_setitem(self, key, value)
def __delitem__(self, key, dict_delitem=dict.__delitem__):
'od.__delitem__(y) <==> del od[y]'
# Deleting an existing item uses self.__map to find the link which gets
# removed by updating the links in the predecessor and successor nodes.
dict_delitem(self, key)
link = self.__map.pop(key)
link_prev = link.prev
link_next = link.next
link_prev.next = link_next
link_next.prev = link_prev
link.prev = None
link.next = None
def __iter__(self):
'od.__iter__() <==> iter(od)'
# Traverse the linked list in order.
root = self.__root
curr = root.next
while curr is not root:
yield curr.key
curr = curr.next
def __reversed__(self):
'od.__reversed__() <==> reversed(od)'
# Traverse the linked list in reverse order.
root = self.__root
curr = root.prev
while curr is not root:
yield curr.key
curr = curr.prev
def clear(self):
'od.clear() -> None. Remove all items from od.'
root = self.__root
root.prev = root.next = root
self.__map.clear()
dict.clear(self)
def popitem(self, last=True):
'''Remove and return a (key, value) pair from the dictionary.
Pairs are returned in LIFO order if last is true or FIFO order if false.
'''
if not self:
raise KeyError('dictionary is empty')
root = self.__root
if last:
link = root.prev
link_prev = link.prev
link_prev.next = root
root.prev = link_prev
else:
link = root.next
link_next = link.next
root.next = link_next
link_next.prev = root
key = link.key
del self.__map[key]
value = dict.pop(self, key)
return key, value
def move_to_end(self, key, last=True):
'''Move an existing element to the end (or beginning if last==False).
Raises KeyError if the element does not exist.
When last=True, acts like a fast version of self[key]=self.pop(key).
'''
link = self.__map[key]
link_prev = link.prev
link_next = link.next
soft_link = link_next.prev
link_prev.next = link_next
link_next.prev = link_prev
root = self.__root
if last:
last = root.prev
link.prev = last
link.next = root
root.prev = soft_link
last.next = link
else:
first = root.next
link.prev = root
link.next = first
first.prev = soft_link
root.next = link
def __sizeof__(self):
sizeof = _sys.getsizeof
n = len(self) + 1 # number of links including root
size = sizeof(self.__dict__) # instance dictionary
size += sizeof(self.__map) * 2 # internal dict and inherited dict
size += sizeof(self.__hardroot) * n # link objects
size += sizeof(self.__root) * n # proxy objects
return size
update = __update = MutableMapping.update
def keys(self):
"D.keys() -> a set-like object providing a view on D's keys"
return _OrderedDicTKEysView(self)
def items(self):
"D.items() -> a set-like object providing a view on D's items"
return _OrderedDictItemsView(self)
def values(self):
"D.values() -> an object providing a view on D's values"
return _OrderedDictValuesView(self)
__ne__ = MutableMapping.__ne__
__marker = object()
def pop(self, key, default=__marker):
'''od.pop(k[,d]) -> v, remove specified key and return the corresponding
value. If key is not found, d is returned if given, otherwise KeyError
is raised.
'''
if key in self:
result = self[key]
del self[key]
return result
if default is self.__marker:
raise KeyError(key)
return default
def setdefault(self, key, default=None):
'od.setdefault(k[,d]) -> od.get(k,d), also set od[k]=d if k not in od'
if key in self:
return self[key]
self[key] = default
return default
@_recursive_repr()
def __repr__(self):
'od.__repr__() <==> repr(od)'
if not self:
return '%s()' % (self.__class__.__name__,)
return '%s(%r)' % (self.__class__.__name__, list(self.items()))
def __reduce__(self):
'Return state information for pickling'
inst_dict = vars(self).copy()
for k in vars(OrderedDict()):
inst_dict.pop(k, None)
return self.__class__, (), inst_dict or None, None, iter(self.items())
def copy(self):
'od.copy() -> a shallow copy of od'
return self.__class__(self)
@classmethod
def fromkeys(cls, iterable, value=None):
'''OD.fromkeys(S[, v]) -> New ordered dictionary with keys from S.
If not specified, the value defaults to None.
'''
self = cls()
for key in iterable:
self[key] = value
return self
def __eq__(self, other):
'''od.__eq__(y) <==> od==y. Comparison to another OD is order-sensitive
while comparison to a regular mapping is order-insensitive.
'''
if isinstance(other, OrderedDict):
return dict.__eq__(self, other) and all(map(_eq, self, other))
return dict.__eq__(self, other)list存储数据的时候,内部实现是数组,数组的查找速度是很快的,但是插入和删除数据的速度堪忧。deque双端列表内部实现是双端队列。deuque适用队列和栈,并且是线程安全的。
deque提供append()和pop()函数实现在deque尾部添加和弹出数据,提供appendleft()和popleft()函数实现在deque头部添加和弹出元素。这4个函数的时间复杂度都是$O(1)$的,但是list的时间复杂度高达$O(n)$。
创建deque队列
from collections import deque
# 创建一个队列长度为20的deque
dQ = deque(range(10), maxlen=20)
print(dQ)
# deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=20)源码
class deque(object):
"""
deque([iterable[, maxlen]]) --> deque object
A list-like sequence optimized for data accesses near its endpoints.
"""
def append(self, *args, **kwargs): # real signature unknown
""" Add an element to the right side of the deque. """
pass
def appendleft(self, *args, **kwargs): # real signature unknown
""" Add an element to the left side of the deque. """
pass
def clear(self, *args, **kwargs): # real signature unknown
""" Remove all elements from the deque. """
pass
def copy(self, *args, **kwargs): # real signature unknown
""" Return a shallow copy of a deque. """
pass
def count(self, value): # real signature unknown; restored from __doc__
""" D.count(value) -> integer -- return number of occurrences of value """
return 0
def extend(self, *args, **kwargs): # real signature unknown
""" Extend the right side of the deque with elements from the iterable """
pass
def extendleft(self, *args, **kwargs): # real signature unknown
""" Extend the left side of the deque with elements from the iterable """
pass
def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__
"""
D.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present.
"""
return 0
def insert(self, index, p_object): # real signature unknown; restored from __doc__
""" D.insert(index, object) -- insert object before index """
pass
def pop(self, *args, **kwargs): # real signature unknown
""" Remove and return the rightmost element. """
pass
def popleft(self, *args, **kwargs): # real signature unknown
""" Remove and return the leftmost element. """
pass
def remove(self, value): # real signature unknown; restored from __doc__
""" D.remove(value) -- remove first occurrence of value. """
pass
def reverse(self): # real signature unknown; restored from __doc__
""" D.reverse() -- reverse *IN PLACE* """
pass
def rotate(self, *args, **kwargs): # real signature unknown
""" Rotate the deque n steps to the right (default n=1). If n is negative, rotates left. """
pass
def __add__(self, *args, **kwargs): # real signature unknown
""" Return self+value. """
pass
def __bool__(self, *args, **kwargs): # real signature unknown
""" self != 0 """
pass
def __contains__(self, *args, **kwargs): # real signature unknown
""" Return key in self. """
pass
def __copy__(self, *args, **kwargs): # real signature unknown
""" Return a shallow copy of a deque. """
pass
def __delitem__(self, *args, **kwargs): # real signature unknown
""" Delete self[key]. """
pass
def __eq__(self, *args, **kwargs): # real signature unknown
""" Return self==value. """
pass
def __getattribute__(self, *args, **kwargs): # real signature unknown
""" Return getattr(self, name). """
pass
def __getitem__(self, *args, **kwargs): # real signature unknown
""" Return self[key]. """
pass
def __ge__(self, *args, **kwargs): # real signature unknown
""" Return self>=value. """
pass
def __gt__(self, *args, **kwargs): # real signature unknown
""" Return self>value. """
pass
def __iadd__(self, *args, **kwargs): # real signature unknown
""" Implement self+=value. """
pass
def __imul__(self, *args, **kwargs): # real signature unknown
""" Implement self*=value. """
pass
def __init__(self, iterable=(), maxlen=None): # known case of _collections.deque.__init__
"""
deque([iterable[, maxlen]]) --> deque object
A list-like sequence optimized for data accesses near its endpoints.
# (copied from class doc)
"""
pass
def __iter__(self, *args, **kwargs): # real signature unknown
""" Implement iter(self). """
pass
def __len__(self, *args, **kwargs): # real signature unknown
""" Return len(self). """
pass
def __le__(self, *args, **kwargs): # real signature unknown
""" Return self<=value. """
pass
def __lt__(self, *args, **kwargs): # real signature unknown
""" Return self<value. """
pass
def __mul__(self, *args, **kwargs): # real signature unknown
""" Return self*value.n """
pass
@staticmethod # known case of __new__
def __new__(*args, **kwargs): # real signature unknown
""" Create and return a new object. See help(type) for accurate signature. """
pass
def __ne__(self, *args, **kwargs): # real signature unknown
""" Return self!=value. """
pass
def __reduce__(self, *args, **kwargs): # real signature unknown
""" Return state information for pickling. """
pass
def __repr__(self, *args, **kwargs): # real signature unknown
""" Return repr(self). """
pass
def __reversed__(self): # real signature unknown; restored from __doc__
""" D.__reversed__() -- return a reverse iterator over the deque """
pass
def __rmul__(self, *args, **kwargs): # real signature unknown
""" Return self*value. """
pass
def __setitem__(self, *args, **kwargs): # real signature unknown
""" Set self[key] to value. """
pass
def __sizeof__(self): # real signature unknown; restored from __doc__
""" D.__sizeof__() -- size of D in memory, in bytes """
pass
maxlen = property(lambda self: object(), lambda self, v: None, lambda self: None) # default
"""maximum size of a deque or None if unbounded"""
__hash__ = None用来统计元素出现的次数。
应用场景

源码
class Counter(dict):
'''Dict subclass for counting hashable items. Sometimes called a bag
or multiset. Elements are stored as dictionary keys and their counts
are stored as dictionary values.
>>> c = Counter('abcdeabcdabcaba') # count elements from a string
>>> c.most_common(3) # three most common elements
[('a', 5), ('b', 4), ('c', 3)]
>>> sorted(c) # list all unique elements
['a', 'b', 'c', 'd', 'e']
>>> ''.join(sorted(c.elements())) # list elements with repetitions
'aaaaabbbbcccdde'
>>> sum(c.values()) # total of all counts
15
>>> c['a'] # count of letter 'a'
5
>>> for elem in 'shazam': # update counts from an iterable
... c[elem] += 1 # by adding 1 to each element's count
>>> c['a'] # now there are seven 'a'
7
>>> del c['b'] # remove all 'b'
>>> c['b'] # now there are zero 'b'
0
>>> d = Counter('simsalabim') # make another counter
>>> c.update(d) # add in the second counter
>>> c['a'] # now there are nine 'a'
9
>>> c.clear() # empty the counter
>>> c
Counter()
Note: If a count is set to zero or reduced to zero, it will remain
in the counter until the entry is deleted or the counter is cleared:
>>> c = Counter('aaabbc')
>>> c['b'] -= 2 # reduce the count of 'b' by two
>>> c.most_common() # 'b' is still in, but its count is zero
[('a', 3), ('c', 1), ('b', 0)]
'''
# References:
# Http://en.wikipedia.org/wiki/Multiset
# http://www.gnu.org/software/smalltalk/manual-base/html_node/Bag.html
# http://www.demo2s.com/Tutorial/Cpp/0380__set-multiset/Catalog0380__set-multiset.htm
# http://code.activestate.com/recipes/259174/
# Knuth, TAOCP Vol. II section 4.6.3
def __init__(*args, **kwds):
'''Create a new, empty Counter object. And if given, count elements
from an input iterable. Or, initialize the count from another mapping
of elements to their counts.
>>> c = Counter() # a new, empty counter
>>> c = Counter('gallahad') # a new counter from an iterable
>>> c = Counter({'a': 4, 'b': 2}) # a new counter from a mapping
>>> c = Counter(a=4, b=2) # a new counter from keyword args
'''
if not args:
raise TypeError("descriptor '__init__' of 'Counter' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
super(Counter, self).__init__()
self.update(*args, **kwds)
def __missing__(self, key):
'The count of elements not in the Counter is zero.'
# Needed so that self[missing_item] does not raise KeyError
return 0
def most_common(self, n=None):
'''List the n most common elements and their counts from the most
common to the least. If n is None, then list all element counts.
>>> Counter('abcdeabcdabcaba').most_common(3)
[('a', 5), ('b', 4), ('c', 3)]
'''
# Emulate Bag.sortedByCount from Smalltalk
if n is None:
return sorted(self.items(), key=_itemgetter(1), reverse=True)
return _heapq.nlargest(n, self.items(), key=_itemgetter(1))
def elements(self):
'''Iterator over elements repeating each as many times as its count.
>>> c = Counter('ABCABC')
>>> sorted(c.elements())
['A', 'A', 'B', 'B', 'C', 'C']
# Knuth's example for prime factors of 1836: 2**2 * 3**3 * 17**1
>>> prime_factors = Counter({2: 2, 3: 3, 17: 1})
>>> product = 1
>>> for factor in prime_factors.elements(): # loop over factors
... product *= factor # and multiply them
>>> product
1836
Note, if an element's count has been set to zero or is a negative
number, elements() will ignore it.
'''
# Emulate Bag.do from Smalltalk and Multiset.begin from c++.
return _chain.from_iterable(_starmap(_repeat, self.items()))
# Override dict methods where necessary
@classmethod
def fromkeys(cls, iterable, v=None):
# There is no equivalent method for counters because setting v=1
# means that no element can have a count greater than one.
raise NotImplementedError(
'Counter.fromkeys() is undefined. Use Counter(iterable) instead.')
def update(*args, **kwds):
'''Like dict.update() but add counts instead of replacing them.
Source can be an iterable, a dictionary, or another Counter instance.
>>> c = Counter('which')
>>> c.update('witch') # add elements from another iterable
>>> d = Counter('watch')
>>> c.update(d) # add elements from another counter
>>> c['h'] # four 'h' in which, witch, and watch
4
'''
# The regular dict.update() operation makes no sense here because the
# replace behavior results in the some of original untouched counts
# being mixed-in with all of the other counts for a mismash that
# doesn't have a straight-forward interpretation in most counting
# contexts. Instead, we implement straight-addition. Both the inputs
# and outputs are allowed to contain zero and negative counts.
if not args:
raise TypeError("descriptor 'update' of 'Counter' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
iterable = args[0] if args else None
if iterable is not None:
if isinstance(iterable, Mapping):
if self:
self_get = self.get
for elem, count in iterable.items():
self[elem] = count + self_get(elem, 0)
else:
super(Counter, self).update(iterable) # fast path when counter is empty
else:
_count_elements(self, iterable)
if kwds:
self.update(kwds)
def subtract(*args, **kwds):
'''Like dict.update() but subtracts counts instead of replacing them.
Counts can be reduced below zero. Both the inputs and outputs are
allowed to contain zero and negative counts.
Source can be an iterable, a dictionary, or another Counter instance.
>>> c = Counter('which')
>>> c.subtract('witch') # subtract elements from another iterable
>>> c.subtract(Counter('watch')) # subtract elements from another counter
>>> c['h'] # 2 in which, minus 1 in witch, minus 1 in watch
0
>>> c['w'] # 1 in which, minus 1 in witch, minus 1 in watch
-1
'''
if not args:
raise TypeError("descriptor 'subtract' of 'Counter' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
iterable = args[0] if args else None
if iterable is not None:
self_get = self.get
if isinstance(iterable, Mapping):
for elem, count in iterable.items():
self[elem] = self_get(elem, 0) - count
else:
for elem in iterable:
self[elem] = self_get(elem, 0) - 1
if kwds:
self.subtract(kwds)
def copy(self):
'Return a shallow copy.'
return self.__class__(self)
def __reduce__(self):
return self.__class__, (dict(self),)
def __delitem__(self, elem):
'Like dict.__delitem__() but does not raise KeyError for missing values.'
if elem in self:
super().__delitem__(elem)
def __repr__(self):
if not self:
return '%s()' % self.__class__.__name__
try:
items = ', '.join(map('%r: %r'.__mod__, self.most_common()))
return '%s({%s})' % (self.__class__.__name__, items)
except TypeError:
# handle case where values are not orderable
return '{0}({1!r})'.format(self.__class__.__name__, dict(self))
# Multiset-style mathematical operations discussed in:
# Knuth TAOCP Volume II section 4.6.3 exercise 19
# and at http://en.wikipedia.org/wiki/Multiset
#
# Outputs guaranteed to only include positive counts.
#
# To strip negative and zero counts, add-in an empty counter:
# c += Counter()
def __add__(self, other):
'''Add counts from two counters.
>>> Counter('abbb') + Counter('bcc')
Counter({'b': 4, 'c': 2, 'a': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
newcount = count + other[elem]
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count > 0:
result[elem] = count
return result
def __sub__(self, other):
''' Subtract count, but keep only results with positive counts.
>>> Counter('abbbc') - Counter('bccd')
Counter({'b': 2, 'a': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
newcount = count - other[elem]
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count < 0:
result[elem] = 0 - count
return result
def __or__(self, other):
'''UNIOn is the maximum of value in either of the input counters.
>>> Counter('abbb') | Counter('bcc')
Counter({'b': 3, 'c': 2, 'a': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
other_count = other[elem]
newcount = other_count if count < other_count else count
if newcount > 0:
result[elem] = newcount
for elem, count in other.items():
if elem not in self and count > 0:
result[elem] = count
return result
def __and__(self, other):
''' Intersection is the minimum of corresponding counts.
>>> Counter('abbb') & Counter('bcc')
Counter({'b': 1})
'''
if not isinstance(other, Counter):
return NotImplemented
result = Counter()
for elem, count in self.items():
other_count = other[elem]
newcount = count if count < other_count else other_count
if newcount > 0:
result[elem] = newcount
return result
def __pos__(self):
'Adds an empty counter, effectively stripping negative and zero counts'
result = Counter()
for elem, count in self.items():
if count > 0:
result[elem] = count
return result
def __neg__(self):
'''Subtracts from an empty counter. Strips positive and zero counts,
and flips the sign on negative counts.
'''
result = Counter()
for elem, count in self.items():
if count < 0:
result[elem] = 0 - count
return result
def _keep_positive(self):
'''Internal method to strip elements with a negative or zero count'''
nonpositive = [elem for elem, count in self.items() if not count > 0]
for elem in nonpositive:
del self[elem]
return self
def __iadd__(self, other):
'''Inplace add from another counter, keeping only positive counts.
>>> c = Counter('abbb')
>>> c += Counter('bcc')
>>> c
Counter({'b': 4, 'c': 2, 'a': 1})
'''
for elem, count in other.items():
self[elem] += count
return self._keep_positive()
def __isub__(self, other):
'''Inplace subtract counter, but keep only results with positive counts.
>>> c = Counter('abbbc')
>>> c -= Counter('bccd')
>>> c
Counter({'b': 2, 'a': 1})
'''
for elem, count in other.items():
self[elem] -= count
return self._keep_positive()
def __ior__(self, other):
'''Inplace union is the maximum of value from either counter.
>>> c = Counter('abbb')
>>> c |= Counter('bcc')
>>> c
Counter({'b': 3, 'c': 2, 'a': 1})
'''
for elem, other_count in other.items():
count = self[elem]
if other_count > count:
self[elem] = other_count
return self._keep_positive()
def __iand__(self, other):
'''Inplace intersection is the minimum of corresponding counts.
>>> c = Counter('abbb')
>>> c &= Counter('bcc')
>>> c
Counter({'b': 1})
'''
for elem, count in self.items():
other_count = other[elem]
if other_count < count:
self[elem] = other_count
return self._keep_positive()命名tuple中的元素来使程序更具可读性 。
应用案例
from collections import namedtuple
City = namedtuple('City', 'name title popu coor')
tokyo = City('Tokyo', '下辈子让我做系守的姑娘吧!下辈子让我做东京的帅哥吧!', 36.933, (35.689722, 139.691667))
print(tokyo)
# City(name='Tokyo', title='下辈子让我做系守的姑娘吧!下辈子让我做东京的帅哥吧!', popu=36.933, coor=(35.689722, 139.691667))def namedtuple(typename, field_names, *, verbose=False, rename=False, module=None):
"""Returns a new subclass of tuple with named fields.
>>> Point = namedtuple('Point', ['x', 'y'])
>>> Point.__doc__ # docstring for the new class
'Point(x, y)'
>>> p = Point(11, y=22) # instantiate with positional args or keywords
>>> p[0] + p[1] # indexable like a plain tuple
33
>>> x, y = p # unpack like a regular tuple
>>> x, y
(11, 22)
>>> p.x + p.y # fields also accessible by name
33
>>> d = p._asdict() # convert to a dictionary
>>> d['x']
11
>>> Point(**d) # convert from a dictionary
Point(x=11, y=22)
>>> p._replace(x=100) # _replace() is like str.replace() but targets named fields
Point(x=100, y=22)
"""
# Validate the field names. At the user's option, either generate an error
# message or automatically replace the field name with a valid name.
if isinstance(field_names, str):
field_names = field_names.replace(',', ' ').split()
field_names = list(map(str, field_names))
typename = str(typename)
if rename:
seen = set()
for index, name in enumerate(field_names):
if (not name.isidentifier()
or _iskeyword(name)
or name.startswith('_')
or name in seen):
field_names[index] = '_%d' % index
seen.add(name)
for name in [typename] + field_names:
if type(name) is not str:
raise TypeError('Type names and field names must be strings')
if not name.isidentifier():
raise ValueError('Type names and field names must be valid '
'identifiers: %r' % name)
if _iskeyword(name):
raise ValueError('Type names and field names cannot be a '
'keyword: %r' % name)
seen = set()
for name in field_names:
if name.startswith('_') and not rename:
raise ValueError('Field names cannot start with an underscore: '
'%r' % name)
if name in seen:
raise ValueError('Encountered duplicate field name: %r' % name)
seen.add(name)
# Fill-in the class template
class_definition = _class_template.format(
typename = typename,
field_names = tuple(field_names),
num_fields = len(field_names),
arg_list = repr(tuple(field_names)).replace("'", "")[1:-1],
repr_fmt = ', '.join(_repr_template.format(name=name)
for name in field_names),
field_defs = '\n'.join(_field_template.format(index=index, name=name)
for index, name in enumerate(field_names))
)
# Execute the template string in a temporary namespace and support
# tracing utilities by setting a value for frame.f_globals['__name__']
namespace = dict(__name__='namedtuple_%s' % typename)
exec(class_definition, namespace)
result = namespace[typename]
result._source = class_definition
if verbose:
print(result._source)
# For pickling to work, the __module__ variable needs to be set to the frame
# where the named tuple is created. Bypass this step in environments where
# sys._getframe is not defined (Jython for example) or sys._getframe is not
# defined for arguments greater than 0 (IronPython), or where the user has
# specified a particular module.
if module is None:
try:
module = _sys._getframe(1).f_globals.get('__name__', '__main__')
except (AttributeError, ValueError):
pass
if module is not None:
result.__module__ = module
return result用来合并多个字典。
应用案例
from collections import ChainMap
cm = ChainMap(
{"Apple": 18},
{"Orange": 20},
{"Mango": 22},
{"pineapple": 24},
)
print(cm)
# ChainMap({'Apple': 18}, {'Orange': 20}, {'Mango': 22}, {'pineapple': 24})源码
class ChainMap(MutableMapping):
''' A ChainMap groups multiple dicts (or other mappings) together
to create a single, updateable view.
The underlying mappings are stored in a list. That list is public and can
be accessed or updated using the *maps* attribute. There is no other
state.
Lookups search the underlying mappings successively until a key is found.
In contrast, writes, updates, and deletions only operate on the first
mapping.
'''
def __init__(self, *maps):
'''Initialize a ChainMap by setting *maps* to the given mappings.
If no mappings are provided, a single empty dictionary is used.
'''
self.maps = list(maps) or [{}] # always at least one map
def __missing__(self, key):
raise KeyError(key)
def __getitem__(self, key):
for mapping in self.maps:
try:
return mapping[key] # can't use 'key in mapping' with defaultdict
except KeyError:
pass
return self.__missing__(key) # support subclasses that define __missing__
def get(self, key, default=None):
return self[key] if key in self else default
def __len__(self):
return len(set().union(*self.maps)) # reuses stored hash values if possible
def __iter__(self):
return iter(set().union(*self.maps))
def __contains__(self, key):
return any(key in m for m in self.maps)
def __bool__(self):
return any(self.maps)
@_recursive_repr()
def __repr__(self):
return '{0.__class__.__name__}({1})'.format(
self, ', '.join(map(repr, self.maps)))
@classmethod
def fromkeys(cls, iterable, *args):
'Create a ChainMap with a single dict created from the iterable.'
return cls(dict.fromkeys(iterable, *args))
def copy(self):
'New ChainMap or subclass with a new copy of maps[0] and refs to maps[1:]'
return self.__class__(self.maps[0].copy(), *self.maps[1:])
__copy__ = copy
def new_child(self, m=None): # like Django's Context.push()
'''New ChainMap with a new map followed by all previous maps.
If no map is provided, an empty dict is used.
'''
if m is None:
m = {}
return self.__class__(m, *self.maps)
@property
def parents(self): # like Django's Context.pop()
'New ChainMap from maps[1:].'
return self.__class__(*self.maps[1:])
def __setitem__(self, key, value):
self.maps[0][key] = value
def __delitem__(self, key):
try:
del self.maps[0][key]
except KeyError:
raise KeyError('Key not found in the first mapping: {!r}'.format(key))
def popitem(self):
'Remove and return an item pair from maps[0]. Raise KeyError is maps[0] is empty.'
try:
return self.maps[0].popitem()
except KeyError:
raise KeyError('No keys found in the first mapping.')
def pop(self, key, *args):
'Remove *key* from maps[0] and return its value. Raise KeyError if *key* not in maps[0].'
try:
return self.maps[0].pop(key, *args)
except KeyError:
raise KeyError('Key not found in the first mapping: {!r}'.format(key))
def clear(self):
'Clear maps[0], leaving maps[1:] intact.'
self.maps[0].clear()UserDict是MutableMapping和Mapping的子类,它继承了MutableMapping.update和Mapping.get两个重要的方法 。
应用案例
from collections import UserDict
class DictKeyToStr(UserDict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key):
return str(key) in self.data
def __setitem__(self, key, item):
self.data[str(key)] = item
# 该函数可以不实现
'''
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
'''源码
class UserDict(MutableMapping):
# Start by filling-out the abstract methods
def __init__(*args, **kwargs):
if not args:
raise TypeError("descriptor '__init__' of 'UserDict' object "
"needs an argument")
self, *args = args
if len(args) > 1:
raise TypeError('expected at most 1 arguments, got %d' % len(args))
if args:
dict = args[0]
elif 'dict' in kwargs:
dict = kwargs.pop('dict')
import warnings
warnings.warn("Passing 'dict' as keyword argument is deprecated",
DeprecationWarning, stacklevel=2)
else:
dict = None
self.data = {}
if dict is not None:
self.update(dict)
if len(kwargs):
self.update(kwargs)
def __len__(self): return len(self.data)
def __getitem__(self, key):
if key in self.data:
return self.data[key]
if hasattr(self.__class__, "__missing__"):
return self.__class__.__missing__(self, key)
raise KeyError(key)
def __setitem__(self, key, item): self.data[key] = item
def __delitem__(self, key): del self.data[key]
def __iter__(self):
return iter(self.data)
# Modify __contains__ to work correctly when __missing__ is present
def __contains__(self, key):
return key in self.data
# Now, add the methods in dicts but not in MutableMapping
def __repr__(self): return repr(self.data)
def copy(self):
if self.__class__ is UserDict:
return UserDict(self.data.copy())
import copy
data = self.data
try:
self.data = {}
c = copy.copy(self)
finally:
self.data = data
c.update(self)
return c
@classmethod
def fromkeys(cls, iterable, value=None):
d = cls()
for key in iterable:
d[key] = value
return dPython与Java的变量本质上不一样,Python的变量本事是个指针。当Python解释器执行number=1的时候,实际上先在内存中创建一个int对象,然后将number指向这个int对象的内存地址,也就是将number“贴”在int对象上,测试用例如下:
number = [1, 2, 3]
demo = number
demo.append(4)
print(number)
# [1, 2, 3, 4]==和is的区别就是前者判断的值是否相等,后者判断的是对象id值是否相等。
class Person(object):
pass
p_0 = Person()
p_1 = Person()
print(p_0 is p_1) # False
print(p_0 == p_1) # False
print(id(p_0)) # 2972754016464
print(id(p_1)) # 2972754016408
li_a = [1, 2, 3, 4]
li_b = [1, 2, 3, 4]
print(li_a is li_b) # False
print(li_a == li_b) # True
print(id(li_a)) # 2972770077064
print(id(li_b)) # 2972769996680
a = 1
b = 1
print(a is b) # True
print(a == b) # True
print(id(a)) # 1842179136
print(id(b)) # 1842179136Python有一个优化机制叫intern,像这种经常使用的小整数、小字符串,在运行时就会创建,并且全局唯一。
Python中的del语句并不等同于C++中的delete,Python中的del是将这个对象的指向删除,当这个对象没有任何指向的时候,Python虚拟机才会删除这个对象。
class Home(object):
def __init__(self, age):
self.__age = age
@property
def age(self):
return self.__age
if __name__ == '__main__':
home = Home(21)
print(home.age) # 21在Python中,为函数添加@property装饰器可以使得函数像变量一样访问。
__getattr__在查找属性的时候,找不到该属性就会调用这个函数。
class Demo(object):
def __init__(self, user, passwd):
self.user = user
self.password = passwd
def __getattr__(self, item):
return 'Not find Attr.'
if __name__ == '__main__':
d = Demo('Bob', '123456')
print(d.User)__getattribute__在调用属性之前会调用该方法。
class Demo(object):
def __init__(self, user, passwd):
self.user = user
self.password = passwd
def __getattr__(self, item):
return 'Not find Attr.'
def __getattribute__(self, item):
print('Hello.')
if __name__ == '__main__':
d = Demo('Bob', '123456')
print(d.User)
# Hello.
# None在一个类中实现__get__()、__set__()和__delete__()都是属性描述符。
数据属性描述符
import numbers
class IntField(object):
def __init__(self):
self.v = 0
def __get__(self, instance, owner):
return self.v
def __set__(self, instance, value):
if(not isinstance(value, numbers.Integral)):
raise ValueError("Int value need.")
self.v = value
def __delete__(self, instance):
pass非数据属性描述符
在Python的新式类中,对象属性的访问都会调用__getattribute__()方法,它允许我们在访问对象时自定义访问行为,值得注意的是小心无限递归的发生。__getattriubte__()是所有方法和属性查找的入口,当调用该方法之后会根据一定规则在__dict__中查找相应的属性值或者是对象,如果没有找到就会调用__getattr__()方法,与之对应的__setattr__()和__delattr__()方法分别用来自定义某个属性的赋值行为和用于处理删除属性的行为。描述符的概念在Python 2.2中引进,__get__()、__set__()、__delete__()分别定义取出、设置、删除描述符的值的行为。
__get__()方法的叫做非数据描述符,只有在初始化之后才能被读取。__get__()和__set__()方法的叫做数据描述符,属性是可读写的。对象的属性一般是在__dict__中存储,在Python中,__getattribute__()实现了属性访问的相关规则。
假定存在实例obj,属性number在obj中的查找过程是这样的:
type(b).__mro__,直到找到该属性,并赋值给descr。descr的类型,如果是数据描述符则调用descr.__get__(b, type(b)),并将结果返回。obj的实例属性,也就是obj.__dict__。obj.__dict__没有找到相关属性,就会重新回到descr的判断上。descr类型为非数据描述符,就会调用descr.__get__(b, type(b)),并将结果返回,结束执行。descr是普通属性,直接就返回结果。AttributeError异常,并且结束查找。用流程图表示:
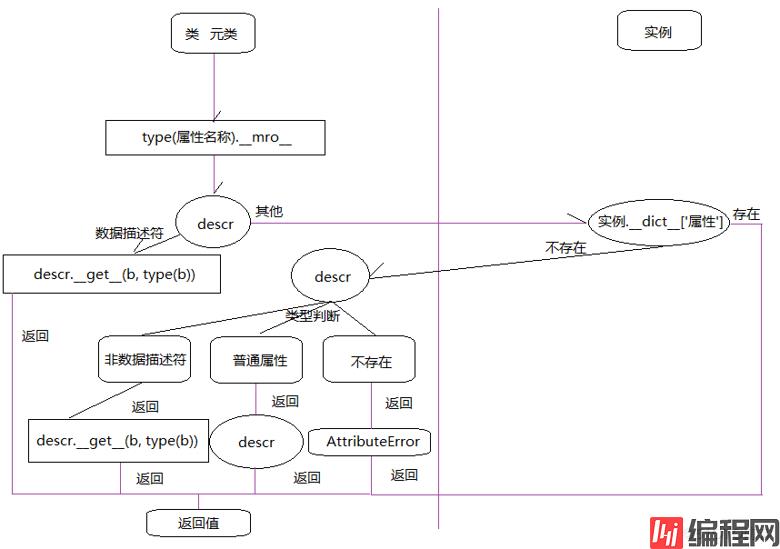
__new__()和__init__()的区别__new__()函数用来控制对象的生成过程,在对象上生成之前调用。__init__()函数用来对对象进行完善,在对象生成之后调用。__new__()函数不返回对象,就不会调用__init__()函数。在Python中一切皆对象,类用来描述如何生成对象,在Python中类也是对象,原因是它具备创建对象的能力。当Python解释器执行到class语句的时候,就会创建这个所谓类的对象。既然类是个对象,那么就可以动态的创建类。这里我们用到type()函数,下面是此函数的构造函数源码:
def __init__(cls, what, bases=None, dict=None): # known special case of type.__init__
"""
type(object_or_name, bases, dict)
type(object) -> the object's type
type(name, bases, dict) -> a new type
# (copied from class doc)
"""
pass由此可知,type()接收一个类的额描述返回一个类。
def bar():
print("Hello...")
user = type('User', (object, ), {
'name': 'Bob',
'age': 20,
'bar': bar,
})
user.bar() # Hello...
print(user.name, user.age) # Bob 20元类用来创建类,因为累也是对象。type()之所以可以创建类是由于tyep()就是个元类,Python中所有的类都由它创建。在Python中,我们可以通过一个对象的__class__属性来确定这个对象由哪个类产生,当Python创建一个类的对象的时候,Python将在这个类中查找其__metaclass__属性。如果找到了,就用它创建对象,如果没有找到,就去父类中查找,如果还是没有,就去模块中查找,一路下来还没有找到的话,就用type()创建。创建元类可以使用下面的写法:
class MetaClass(type):
def __new__(cls, *args, **kwargs):
return super().__new__(cls, *args, **kwargs)
class User(metaclass=MetaClass):
pass元类的主要用途就是创建API,比如Python中的ORM框架。
Python领袖 Tim Peters :
“元类就是深度的魔法,99%的用户应该根本不必为此操心。如果你想搞清楚究竟是否需要用到元类,那么你就不需要它。那些实际用到元类的人都非常清楚地知道他们需要做什么,而且根本不需要解释为什么要用元类。”
当容器中的元素很多的时候,不可能全部读取到内存,那么就需要一种算法来推算下一个元素,这样就不必创建很大的容器,生成器就是这个作用。
Python中的生成器使用yield返回值,每次调用yield会暂停,因此生成器不会一下子全部执行完成,是当需要结果时才进行计算,当函数执行到yield的时候,会返回值并且保存当前的执行状态,也就是函数被挂起了。我们可以使用next()函数和send()函数恢复生成器,将列表推导式的[]换成()就会变成一个生成器:
my_iter = (x for x in range(10))
for i in my_iter:
print(i)值得注意的是,我们一般不会使用next()方法来获取元素,而是使用for循环。当使用while循环时,需要捕获StopIteration异常的产生。
Python虚拟机中有一个栈帧的调用栈,栈帧保存了指定的代码的信息和上下文,每一个栈帧都有自己的数据栈和块栈,由于这些栈帧保存在堆内存中,使得解释器有中断和恢复栈帧的能力:
import inspect
frame = None
def foo():
global frame
frame = inspect.currentframe()
def bar():
foo()
bar()
print(frame.f_code.co_name) # foo
print(frame.f_back.f_code.co_name) # bar这也是生成器存在的基础。只要我们在任何地方获取生成器对象,都可以开始或暂停生成器,因为栈帧是独立于调用者而存在的,这也是协程的理论基础。
迭代器是一种不同于for循环的访问集合内元素的一种方式,一般用来遍历数据,迭代器提供了一种惰性访问数据的方式。
可以使用for循环的有以下几种类型:
yield的生成器函数这些可以直接被for循环调用的对象叫做可迭代对象,可以使用isinstance()判断一个对象是否为可Iterable对象。集合数据类型如list、dict、str等是Iterable但不是Iterator,可以通过iter()函数获得一个Iterator对象。send()和next()的区别就在于send()可传递参数给yield()表达式,这时候传递的参数就会作为yield表达式的值,而yield的参数是返回给调用者的值,也就是说send可以强行修改上一个yield表达式值。
--结束END--
本文标题: 35个高级Python知识点总结
本文链接: https://lsjlt.com/news/188785.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0