Python 官方文档:入门教程 => 点击学习
ORM 全称 Object Relational Mapping, 翻译过来叫对象关系映射。简单的说,ORM 将数据库中的表与面向对象语言中的类建立了一种对应关系。这样,我们要操作数据库,数据库中的表或者表中的一条记录就可以直接通过操作类
ORM 全称 Object Relational Mapping, 翻译过来叫对象关系映射。简单的说,ORM 将数据库中的表与面向对象语言中的类建立了一种对应关系。这样,我们要操作数据库,数据库中的表或者表中的一条记录就可以直接通过操作类或者类实例来完成。
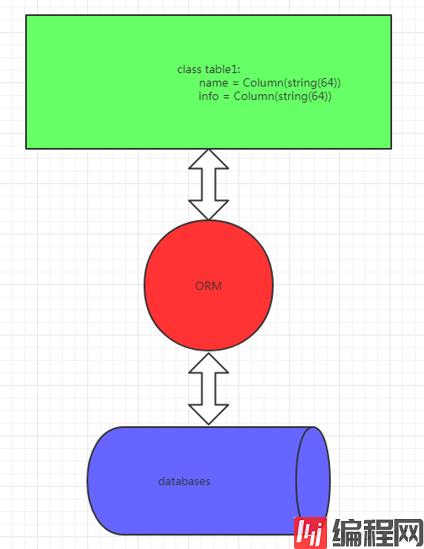
sqlAlchemy 是python 社区最知名的 ORM 工具之一,为高效和高性能的数据库访问设计,实现了完整的企业级持久模型。
安装SQLAlchemy:
cq@ubuntu:~$ sudo pip3 install sqlalchemy
The directory '/home/cq/.cache/pip/Http' or its parent directory is not owned by the current user and the cache has been disabled. Please check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag.
The directory '/home/cq/.cache/pip' or its parent directory is not owned by the current user and caching wheels has been disabled. check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag.
Collecting sqlalchemy
Downloading SQLAlchemy-1.2.2.tar.gz (5.5MB)
100% |████████████████████████████████| 5.5MB 115kB/s
Installing collected packages: sqlalchemy
Running setup.py install for sqlalchemy ... done
Successfully installed sqlalchemy-1.2.2另外,需要安装一个 Python 与 Mysql 之间的驱动程序:
apt-get install python-mysqldb
pip3 install mysqlclient连接数据库
创建py文件写入下面的内容:
#coding=utf-8
from sqlalchemy import create_engine
engine = create_engine('mysql+mysqldb://root:@localhost:3306/blog')
engine.execute('select * from user').fetchall()
print(engine)在上面的程序中,我们连接了默认运行在 3306 端口的 MySQL 中的 blog 数据库。
首先导入了 create_engine, 该方法用于创建 Engine 实例,传递给 create_engine 的参数定义了 MySQL 服务器的访问地址,其格式为 mysql://<user>:<passWord>@<host>/<db_name>。接着通过 engine.execute 方法执行了一条 SQL 语句,查询了 user 表中的所有用户。
要使用 ORM, 我们需要将数据表的结构用 ORM 的语言描述出来。SQLAlchmey 提供了一套 Declarative 系统来完成这个任务。我们以创建一个 users 表为例,看看它是怎么用 SQLAlchemy 的语言来描述的:
#coding=utf-8
from sqlalchemy import create_engine,Column,String,Text,Integer
from sqlalchemy.ext.declarative import declarative_base
engine = create_engine('mysql+mysqldb://root:@localhost:3306/blog')
Base = declarative_base()
class User(Base):
__table__ = 'user'
id = Column(Integer,primary_key=True)
username = Column(String(64),nullable=False,index=True)
password = Column(String(64),nullable=False)
email = Column(String(64),nullable=False,index=True)
def __repr__(self):
return '%s(%r)' % (self.__class__.__name__,self.username)
Base.metadata.create_all(engine)如果想使 Python 类映射到数据库表中,需要基于 SQLAlchemy 的 declarative base class,也就是宣言基类创建类。当基于此基类,创建 Python 类时,就会自动映射到相应的数据库表上。创建宣言基类,可以通过declarative_base 方法进行
from sqlalchemy.ext.declarative import declarative_base
engine = create_engine('mysql+mysqldb://root:@localhost:3306/blog')
Base = declarative_base()在 User 类中,用 tablename 指定在 MySQL 中表的名字。我们创建了三个基本字段,类中的每一个 Column 代表数据库中的一列,在 Colunm 中,指定该列的一些配置。第一个字段代表类的数据类型,上面我们使用 String, Integer 俩个最常用的类型,其他常用的包括:
In [1]: from sql import User
In [2]: User.__table__
Out[2]: Table('users', MetaData(bind=None), Column('id', Integer(), table=<users>, primary_key=True, nullable=False), Column('username', String(length=64), table=<users>, nullable=False), Column('password', String(length=64), table=<users>, nullable=False), Column('email', String(length=64), table=<users>, nullable=False), schema=None)一对多关系
对于一个普通的博客应用来说,用户和文章显然是一个一对多的关系,一篇文章属于一个用户,一个用户可以写很多篇文章,那么他们之间的关系可以这样定义:
from sqlalchemy import ForeignKey
from sqlalchemy.orm import relationship
from sqlalchemy import Column, String, Integer, Text
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
username = Column(String(64), nullable=False, index=True)
password = Column(String(64), nullable=False)
email = Column(String(64), nullable=False, index=True)
articles = relationship('Article')
def __repr__(self):
return '%s(%r)' % (self.__class__.__name__, self.username)
class Article(Base):
__tablename__ = 'articles'
id = Column(Integer, primary_key=True)
title = Column(String(255), nullable=False, index=True)
content = Column(Text)
user_id = Column(Integer, ForeignKey('users.id'))
author = relationship('User')
def __repr__(self):
return '%s(%r)' % (self.__class__.__name__, self.title)每篇文章有一个外键指向 users 表中的主键 id, 而在 User 中使用 SQLAlchemy 提供的 relationship 描述 关系。而用户与文章的之间的这个关系是双向的,所以我们看到上面的两张表中都定义了 relationship。
创建的 articles 表有外键 userid, 在 SQLAlchemy 中可以使用 ForeignKey 设置外键。设置外键后,如果能够直接从 articles 的实例上访问到相应的 users 表中的记录会非常方便,而这可以通过 relationship 实现。上面的代码通过 relationship 定义了 author 属性,这样就可以直接通过 articles.author 获取相应的用户记录。
SQLAlchemy 提供了 backref 让我们可以只需要定义一个关系:articles = relationship('Article', backref='author')
添加了这个就可以不用再在 Article 中定义 relationship 了!
一对一关系
在 User 中我们只定义了几个必须的字段, 但通常用户还有很多其他信息,但这些信息可能不是必须填写的,我们可以把它们放到另一张 UserInfo 表中,这样 User 和 UserInfo 就形成了一对一的关系。你可能会奇怪一对一关系为什么不在一对多关系前面?那是因为一对一关系是基于一对多定义的:
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
username = Column(String(64), nullable=False, index=True)
password = Column(String(64), nullable=False)
email = Column(String(64), nullable=False, index=True)
articles = relationship('Article', backref='author')
userinfo = relationship('UserInfo', backref='user', uselist=False)
def __repr__(self):
return '%s(%r)' % (self.__class__.__name__, self.username)
class UserInfo(Base):
__tablename__ = 'userinfos'
id = Column(Integer, primary_key=True)
name = Column(String(64))
qq = Column(String(11))
phone = Column(String(11))
link = Column(String(64))
user_id = Column(Integer, ForeignKey('users.id'))定义方法和一对多相同,只是需要添加 uselist=False 。
需要注意的地方是定义 users 属性时,使用了 relationship 的 backref 参数,该参数使得可以在 UserInfo 实例中,通过 userinfos.user 访问关联的所有用户信息。
多对多关系
一遍博客通常有一个分类,好几个标签。标签与博客之间就是一个多对多的关系。多对多关系不能直接定义,需要分解成俩个一对多的关系,为此,需要一张额外的表来协助完成,通常对于这种多对多关系的辅助表不会再去创建一个类,而是使用 sqlalchemy 的 Table 类:
# 在原来代码的基础上导入
from sqlalchemy import Table
article_tag = Table(
# 第一个参数为表名称,第二个参数是 metadata,这俩个是必须的,Base.metadata 是 sqlalchemy.schema.MetaData 对象,表示所有 Table 对象集合, create_all() 会触发 CREATE TABLE 语句创建所有的表。
'article_tag', Base.metadata,
# 对于辅助表,一般存储要关联的俩个表的 id,并设置为外键
#course_tag 是双主键,双主键的目的就是为了约束避免出现重复的一对主键记录,大部分情况都是应用在这种多对多的中间表中。
Column('article_id', Integer, ForeignKey('articles.id'), primary_key=True),
Column('tag_id', Integer, ForeignKey('tags.id'), primary_key=True)
)
class Tag(Base):
__tablename__ = 'tags'
id = Column(Integer, primary_key=True)
name = Column(String(64), nullable=False, index=True)
articles = relationship('Articles',
secondary=article_tag,
backref='tages')
#secondary 指的是中间表,backref 指向自己的这个表
def __repr__(self):
return '%s(%r)' % (self.__class__.__name__, self.name)映射到数据
表已经描述好了,在文件末尾使用下面的命令在我们连接的数据库中创建对应的表:
if __name__ == '__main__':
Base.metadata.create_all(engine)查看mysql:
mysql> show tables;
+----------------+
| Tables_in_blog |
+----------------+
| article_tag |
| articles |
| tags |
| userinfos |
| users |
+----------------+
5 rows in set (0.00 sec)session 内部的实现都是调用 engine 的各种接口,相当于 session 是 engine 的一个封装,比如 session.commit 的时候会先调用 engine.connect() 去连接数据库,再调用执行 sql 相关的接口。
当你想打电话给朋友时,你是否得用手机拨通他的号码才能建立起一个会话?同样的,你想和 MySQL 交谈也得先通过 SQLAlchemy 建立一个会话:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()你可以把 sessionmaker 想象成一个手机,engine 当做 MySQL 的号码,拨通这个“号码”我们就创建了一个 Session 类,下面就可以通过这个类的实例与 MySQL 愉快的交谈了!
Create
如果你玩过LOL, 我想你一定知道Faker。而在 Python的世界中,Faker 是用来生成虚假数据的库。 安装它:
$ sudo pip install faker
# 导入 faker 工厂对象
from faker import Factory
# 创建一个 faker 工厂对象
faker = Factory.create()
Session = sessionmaker(bind=engine)
session = Session()
faker_users = [User(
# 使用 faker 生成一个人名
username=faker.name(),
# 使用 faker 生成一个单词
password=faker.word(),
# 使用 faker 生成一个邮箱
email=faker.email(),
) for i in range(10)]
# add_all 一次性添加多个对象
session.add_all(faker_users)
# 生成 5 个分类
faker_cateGories = [Category(name=faker.word()) for i in range(5)]
session.add_all(faker_categories)
# 生成 20 个标签
faker_tags= [Tag(name=faker.word()) for i in range(20)]
session.add_all(faker_tags)
# 生成 100 篇文章
for i in range(100):
article = Article(
# sentence() 生成一句话作为标题
title=faker.sentence(),
# 文章内容为随机生成的 10-20句话
content=' '.join(faker.sentences(nb=random.randint(10, 20))),
# 从生成的用户中随机取一个作为作者
author=random.choice(faker_users),
# 从生成的分类中随机取一个作为分类
category=random.choice(faker_categories)
)
# 从生成的标签中随机取 2-5 个作为分类,注意 sample() 函数的用法
for tag in random.sample(faker_tags, random.randint(2, 5)):
article.tags.append(tag)
session.add(article)
session.commit()在上面的代码中我们创建了10个用户,5个分类,20个标签,100篇文章,并且为每篇文章随机选择了2~5个标签。
使用 SQLAlchemy 往数据库中添加数据,我们只需要创建相关类的实例,调用 session.add() 添加一个,或者 session.add_all() 一次添加多个, 最后 session.commit() 就可以了。
Retrieve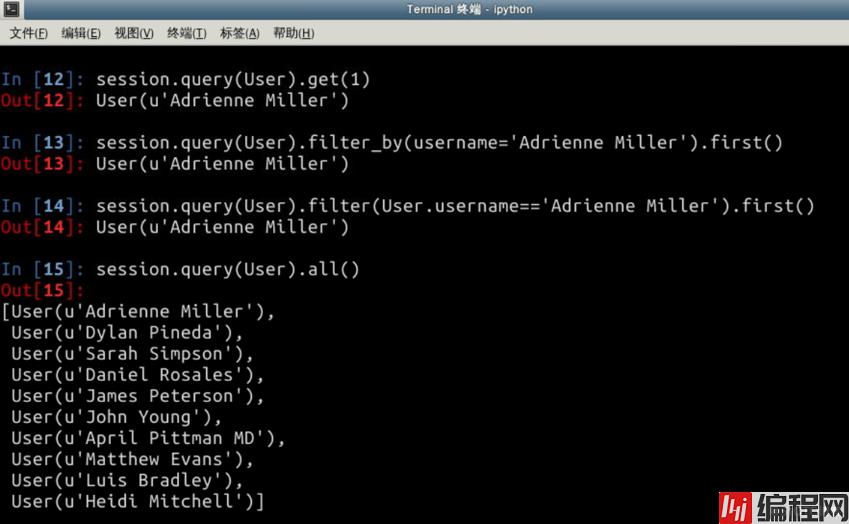
如果我们知道用户 id,就可以用 get 方法, filter_by 用于按某一个字段过滤,而 filter 可以让我们按多个字段过滤,all 则是获取所有。
获取某一字段值可以直接类的属性获取: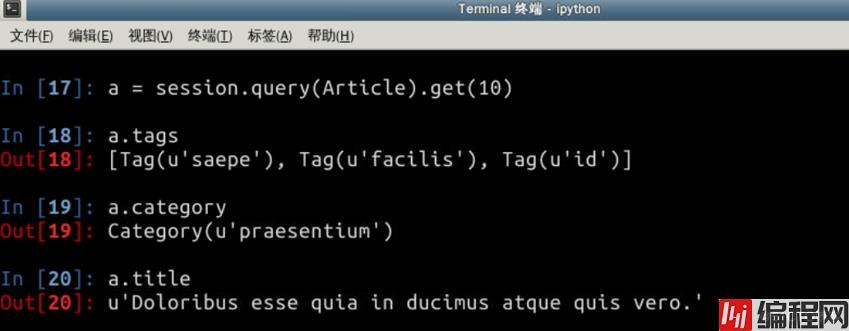
Update
更新一个字段:
>>> a = session.query(Article).get(10)
>>> a.title = 'My test blog post'
>>> session.add(a)
>>> session.commit()添加一个标签:
>>> a = session.query(Article).get(10)
>>> a.tags.append(Tag(name='python'))
>>> session.add(a)
>>> session.commit()Delete
>>> a = session.query(Article).get(10)
>>> session.delete(a)
>>> session.commit()删除直接调用 delete 删除获取到的对象,提交 session 即可。
完整代码
# coding: utf-8
import random
from faker import Factory
from sqlalchemy import create_engine, Table
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import ForeignKey
from sqlalchemy import Column, String, Integer, Text
from sqlalchemy.orm import sessionmaker, relationship
engine = create_engine('mysql+mysqldb://root@localhost:3306/blog?charset=utf8')
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
username = Column(String(64), nullable=False, index=True)
password = Column(String(64), nullable=False)
email = Column(String(64), nullable=False, index=True)
articles = relationship('Article', backref='author')
userinfo = relationship('UserInfo', backref='user', uselist=False)
def __repr__(self):
return '%s(%r)' % (self.__class__.__name__, self.username)
class UserInfo(Base):
__tablename__ = 'userinfos'
id = Column(Integer, primary_key=True)
name = Column(String(64))
qq = Column(String(11))
phone = Column(String(11))
link = Column(String(64))
user_id = Column(Integer, ForeignKey('users.id'))
class Article(Base):
__tablename__ = 'articles'
id = Column(Integer, primary_key=True)
title = Column(String(255), nullable=False, index=True)
content = Column(Text)
user_id = Column(Integer, ForeignKey('users.id'))
cate_id = Column(Integer, ForeignKey('categories.id'))
tags = relationship('Tag', secondary='article_tag', backref='articles')
def __repr__(self):
return '%s(%r)' % (self.__class__.__name__, self.title)
class Category(Base):
__tablename__ = 'categories'
id = Column(Integer, primary_key=True)
name = Column(String(64), nullable=False, index=True)
articles = relationship('Article', backref='category')
def __repr__(self):
return '%s(%r)' % (self.__class__.__name__, self.name)
article_tag = Table(
'article_tag', Base.metadata,
Column('article_id', Integer, ForeignKey('articles.id')),
Column('tag_id', Integer, ForeignKey('tags.id'))
)
class Tag(Base):
__tablename__ = 'tags'
id = Column(Integer, primary_key=True)
name = Column(String(64), nullable=False, index=True)
def __repr__(self):
return '%s(%r)' % (self.__class__.__name__, self.name)
if __name__ == '__main__':
Base.metadata.create_all(engine)
faker = Factory.create()
Session = sessionmaker(bind=engine)
session = Session()
faker_users = [User(
username=faker.name(),
password=faker.word(),
email=faker.email(),
) for i in range(10)]
session.add_all(faker_users)
faker_categories = [Category(name=faker.word()) for i in range(5)]
session.add_all(faker_categories)
faker_tags= [Tag(name=faker.word()) for i in range(20)]
session.add_all(faker_tags)
for i in range(100):
article = Article(
title=faker.sentence(),
content=' '.join(faker.sentences(nb=random.randint(10, 20))),
author=random.choice(faker_users),
category=random.choice(faker_categories)
)
for tag in random.sample(faker_tags, random.randint(2, 5)):
article.tags.append(tag)
session.add(article)
session.commit()flask-SQLAlchemy 使用起来非常有趣,对于基本应用十分容易使用,并且对于大型项目易于扩展。有关完整的指南,请参阅 SQLAlchemy 的 api 文档。
一个最小应用
常见情况下对于只有一个 Flask 应用,所有您需要做的事情就是创建 Flask 应用,选择加载配置接着创建 SQLAlchemy 对象时候把 Flask 应用传递给它作为参数。
一旦创建,这个对象就包含 sqlalchemy 和 sqlalchemy.orm 中的所有函数和助手。此外它还提供一个名为 Model 的类,用于作为声明模型时的 delarative 基类:
from flask import Flask
from flask.ext.sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////tmp/test.db'
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
username = db.Column(db.String(80), unique=True)
email = db.Column(db.String(120), unique=True)
def __init__(self, username, email):
self.username = username
self.email = email
def __repr__(self):
return '<User %r>' % self.username为了创建初始数据库,只需要从交互式 Python shell 中导入 db 对象并且调用 SQLAlchemy.create_all() 方法来创建表和数据库:
>>> from yourapplication import db
>>> db.create_all()Boom, 您的数据库已经生成。现在来创建一些用户:
>>> from yourapplication import User
>>> admin = User('admin', 'admin@example.com')
>>> guest = User('guest', 'guest@example.com')但是它们还没有真正地写入到数据库中,因此让我们来确保它们已经写入到数据库中:
>>> db.session.add(admin)
>>> db.session.add(guest)
>>> db.session.commit()访问数据库中的数据也是十分简单的:
>>> users = User.query.all()
[<User u'admin'>, <User u'guest'>]
>>> admin = User.query.filter_by(username='admin').first()
<User u'admin'>简单的关系
SQLAlchemy 连接到关系型数据库,关系型数据最擅长的东西就是关系。因此,我们将创建一个使用两张相互关联的表的应用作为例子:
from datetime import datetime
class Post(db.Model):
id = db.Column(db.Integer, primary_key=True)
title = db.Column(db.String(80))
body = db.Column(db.Text)
pub_date = db.Column(db.DateTime)
category_id = db.Column(db.Integer, db.ForeignKey('category.id'))
category = db.relationship('Category',
backref=db.backref('posts', lazy='dynamic'))
def __init__(self, title, body, category, pub_date=None):
self.title = title
self.body = body
if pub_date is None:
pub_date = datetime.utcnow()
self.pub_date = pub_date
self.category = category
def __repr__(self):
return '<Post %r>' % self.title
class Category(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
def __init__(self, name):
self.name = name
def __repr__(self):
return '<Category %r>' % self.name首先让我们创建一些对象:
>>> py = Category('Python')
>>> p = Post('Hello Python!', 'Python is pretty cool', py)
>>> db.session.add(py)
>>> db.session.add(p)现在因为我们在 backref 中声明了 posts 作为动态关系,查询显示为:
>>> py.posts
<sqlalchemy.orm.dynamic.AppenderBaseQuery object at 0x1027d37d0>它的行为像一个普通的查询对象,因此我们可以查询与我们测试的 “Python” 分类相关的所有文章(posts):
>>> py.posts.all()
[<Post 'Hello Python!'>]启蒙之路
您仅需要知道与普通的 SQLAlchemy 不同之处:
--结束END--
本文标题: python学习笔记SQLAlchemy
本文链接: https://lsjlt.com/news/188357.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0