Python 官方文档:入门教程 => 点击学习
偶然在图书馆看到《基于R语言的自动数据收集:网络抓取和文本挖掘实用指南》,被第一章概述所吸引,迫不及待地借回来,下载代码在RStuido里进行实验。然后断断续续,囫囵吞枣式地翻了一遍,增长了知识,但没有如预期提升技能。决定换一种方式,照着
偶然在图书馆看到《基于R语言的自动数据收集:网络抓取和文本挖掘实用指南》,被第一章概述所吸引,迫不及待地借回来,下载代码在RStuido里进行实验。然后断断续续,囫囵吞枣式地翻了一遍,增长了知识,但没有如预期提升技能。决定换一种方式,照着书里的内容,用python实现一遍,作为读书笔记。 结果第一章就遇到困难了,要实现第一章的例子需安装basemap、geos等一系列包,还要实现对表格数据的提取。那就从第二章开始吧,直到第八章,然后再回过头来完成第一章的例子。
1. html
1) HTML一个纯文本文件。
2) HTML的标记能够定义文档的某些部分为标题、某些部分为链接、某些部分为表格,还有其它多种形式。
3) 标记定义依赖于预先定义好的字符序列(即标签,如<html> 、<head>等)来封装文本部分。
4) 用浏览器打开一个html文件,看到的是浏览器对这个hrml文件的解释和展现。
5) 起始标签(如<title>)、内容和终止标签(如</title>)组合起来称为元素。
<title>First HTML</title>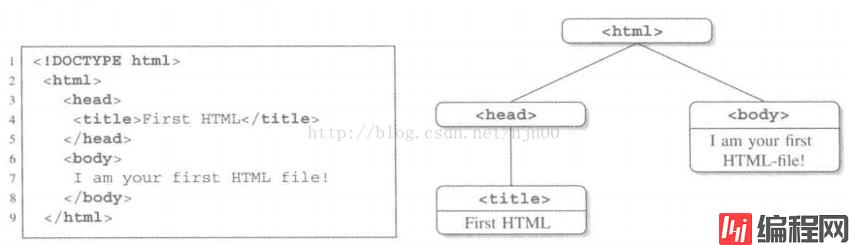
2. HTMLParser
HTMLParser是Python 自带的一个解析html的类,通过重载它的方法,解析出所需要的数据。查看帮助文档:https://docs.python.org/2/library/htmlparser.html
直接拷贝帮助文档的例子稍作修改,就可以用作提取数据。
1)常用的属性属性:lasttag
2) 常用的可重载的方法:
handle_starttag(self, tag, attrs):
handle_endtag(self, tag):
handle_data(self, data):
handle_comment(self, data):
3)实例
从 Http://www.r-datacollection.com/materials/html/fortunes.html 网页中提取用<i>标签标记的内容
只要了解了urllib2和HTMLParser的使用,实现很简单,在MyHTMLParser类中定义了一个属性 data存放读取到的数据。源码如下:
# -*- coding:utf-8 -*-
import urllib2
from HTMLParser import HTMLParser
class MyHTMLParser(HTMLParser):
def __init__(self):
HTMLParser.__init__(self)
self.data = []
def get_data(self):
return self.data
def handle_data(self, data):
if self.lasttag == 'i':
if data != None and len(data.strip()) > 0:
s = data.strip("'")
self.data.append(s)
def get_html(url = 'http://www.r-datacollection.com/materials/html/fortunes.html'):
request = urllib2.Request(url)
response = urllib2.urlopen(request)
page = response.read()
parser = MyHTMLParser()
parser.feed(page)
parser.close()
for line in parser.get_data():
print line
if __name__ == '__main__':
get_html()--结束END--
本文标题: Python 网络抓取和文本挖掘-1 H
本文链接: https://lsjlt.com/news/184960.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0