Python 官方文档:入门教程 => 点击学习
import requestsimport reimport timeclass get_Address():def get_Dy(self,pages):for n in[1,pages]:#print(n)a_url="Http://w
import requests
import re
import time
class get_Address():
def get_Dy(self,pages):
for n in[1,pages]:
#print(n)
a_url="Http://www.ygdy8.net/html/gndy/dyzz/list_23_"+str(n)+".html"
html_1=requests.get(a_url)
#制定网页编码格式
html_1.encoding='gb2312'
#print(html_1.text)
#正则匹配()里的内容 用.*?匹配
detil_list=re.findall('<a href="(.*?)" class="ulink">' ,html_1.text)
#print(detil_list)
for m in detil_list:
b_url="http://www.ygdy8.net/"+m
#print(b_url)
#睡眠一秒
time.sleep(1)
html_2=requests.get(b_url)
#制定网页编码格式
html_2.encoding='gb2312'
# print(html_2.text)
# break
ftp=re.findall('<a href="(.*?)">.*?</a></td>',html_2.text)
#print(ftp)
#写入本地
with open(r'E:\personal\vscode\1.txt','a',encoding='utf-8') as ff: # 打开本地文件前面加上r或者用双反斜杠,a是追加的意思,编码格式为utf-8
ff.write(ftp[0]+'\n')#类实例化
tm = get_Address()
tm.get_Dy(5)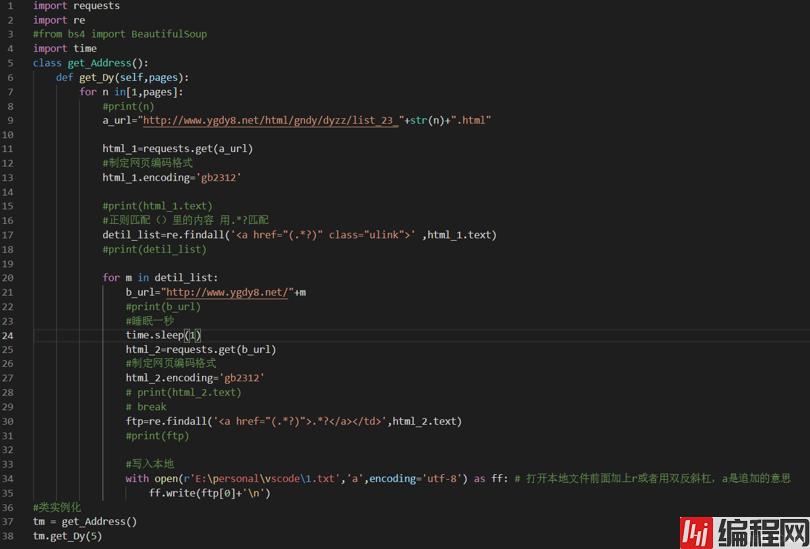
运行一下,会看到电影ftp的下载地址写入到了本地文件中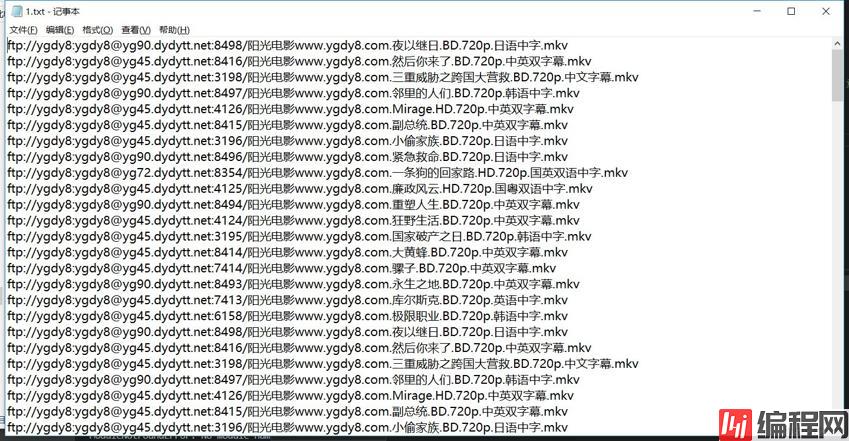
--结束END--
本文标题: python收集电影下载地址
本文链接: https://lsjlt.com/news/183668.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0