


本人是第一次写博客,有写得不好的地方欢迎值出来,大家一起进步!
scrapy-splash的介绍
scrapy-splash模块主要使用了Splash. 所谓的Splash, 就是一个javascript渲染服务。它是一个实现了Http api的轻量级浏览器,Splash是用python实现的,同时使用Twisted和Qt。Twisted(QT)用来让服务具有异步处理能力,以发挥WEBkit的并发能力。Splash的特点如下:
- 并行处理多个网页
- 得到html结果以及(或者)渲染成图片
- 关掉加载图片或使用 Adblock Plus规则使得渲染速度更快
- 使用JavaScript处理网页内容
- 使用lua脚本
- 能在Splash-Jupyter Notebooks中开发Splash Lua scripts
- 能够获得具体的HAR格式的渲染信息
参考文档:https://www.cnblogs.com/jclian91/p/8590617.html
准备配置
页面分析
首先进入https://search.jd.com/ 网站搜索想要的书籍, 这里以 python3.7 书籍为例子。

点击搜索后发现京东是通过 js 来加载书籍数据的, 通过下来鼠标可以发现加载了更多的书籍数据(数据也可以通过京东的api来获取)
首先是模拟搜索,通过检查可得:

然后是模拟下拉,这里选择页面底部的这个元素作为模拟元素:

开始爬取
模拟点击的lua脚本并获取页数:


1 function main(splash, args)
2 splash.images_enabled = false
3 splash:set_user_agent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36')
4 assert(splash:Go(args.url))
5 splash:wait(0.5)
6 local input = splash:select("#keyWord")
7 input:send_text('Python3.7')
8 splash:wait(0.5)
9 local fORM = splash:select('.input_submit')
10 form:click()
11 splash:wait(2)
12 splash:runjs("document.getElementsByClassName('bottom-search')[0].scrollIntoView(true)")
13 splash:wait(6)
14 return splash:html()
15 end
同上有模拟下拉的代码:
1 function main(splash, args)
2 splash.images_enabled = false
3 splash:set_user_agent('Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36')
4 assert(splash:go(args.url))
5 splash:wait(2)
6 splash:runjs("document.getElementsByClassName('bottom-search')[0].scrollIntoView(true)")
7 splash:wait(6)
8 return splash:html()
9 end
选择你想要获取的元素,通过检查获得。附上源码:
1 # -*- coding: utf-8 -*-
2 import scrapy
3 from scrapy import Request
4 from scrapy_splash import SplashRequest
5 from ..items import JdsplashItem
6
7
8
9 lua_script = '''
10 function main(splash, args)
11 splash.images_enabled = false
12 splash:set_user_agent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36')
13 assert(splash:go(args.url))
14 splash:wait(0.5)
15 local input = splash:select("#keyword")
16 input:send_text('python3.7')
17 splash:wait(0.5)
18 local form = splash:select('.input_submit')
19 form:click()
20 splash:wait(2)
21 splash:runjs("document.getElementsByClassName('bottom-search')[0].scrollIntoView(true)")
22 splash:wait(6)
23 return splash:html()
24 end
25 '''
26
27 lua_script2 = '''
28 function main(splash, args)
29 splash.images_enabled = false
30 splash:set_user_agent('Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/36.0.1985.67 Safari/537.36')
31 assert(splash:go(args.url))
32 splash:wait(2)
33 splash:runjs("document.getElementsByClassName('bottom-search')[0].scrollIntoView(true)")
34 splash:wait(6)
35 return splash:html()
36 end
37 '''
38
39 class JdBookSpider(scrapy.Spider):
40 name = 'jd'
41 allowed_domains = ['search.jd.com']
42 start_urls = ['https://search.jd.com']
43
44 def start_requests(self):
45 #进入搜索页进行搜索
46 for each in self.start_urls:
47 yield SplashRequest(each,callback=self.parse,endpoint='execute',
48 args={'lua_source': lua_script})
49
50 def parse(self, response):
51 item = JdsplashItem()
52 price = response.CSS('div.gl-i-wrap div.p-price i::text').getall()
53 page_num = response.xpath("//span[@class= 'p-num']/a[last()-1]/text()").get()
54 #这里使用了 xpath 函数 fn:string(arg):返回参数的字符串值。参数可以是数字、逻辑值或节点集。
55 #可能这就是 xpath 比 css 更精致的地方吧
56 name = response.css('div.gl-i-wrap div.p-name').xpath('string(.//em)').getall()
57 #comment = response.css('div.gl-i-wrap div.p-commit').xpath('string(.//strong)').getall()
58 comment = response.css('div.gl-i-wrap div.p-commit strong a::text').getall()
59 publishstore = response.css('div.gl-i-wrap div.p-shopnum a::attr(title)').getall()
60 href = [response.urljoin(i) for i in response.css('div.gl-i-wrap div.p-img a::attr(href)').getall()]
61 for each in zip(name, price, comment, publishstore,href):
62 item['name'] = each[0]
63 item['price'] = each[1]
64 item['comment'] = each[2]
65 item['p_store'] = each[3]
66 item['href'] = each[4]
67 yield item
68 #这里从第二页开始
69 url = 'https://search.jd.com/Search?keyword=python3.7&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&page=%d&s=%d&click=0'
70 for each_page in range(1,int(page_num)):
71 yield SplashRequest(url%(each_page*2+1,each_page*60),callback=self.s_parse,endpoint='execute',
72 args={'lua_source': lua_script2})
73
74 def s_parse(self, response):
75 item = JdsplashItem()
76 price = response.css('div.gl-i-wrap div.p-price i::text').getall()
77 name = response.css('div.gl-i-wrap div.p-name').xpath('string(.//em)').getall()
78 comment = response.css('div.gl-i-wrap div.p-commit strong a::text').getall()
79 publishstore = response.css('div.gl-i-wrap div.p-shopnum a::attr(title)').getall()
80 href = [response.urljoin(i) for i in response.css('div.gl-i-wrap div.p-img a::attr(href)').getall()]
81 for each in zip(name, price, comment, publishstore, href):
82 item['name'] = each[0]
83 item['price'] = each[1]
84 item['comment'] = each[2]
85 item['p_store'] = each[3]
86 item['href'] = each[4]
87 yield item
各个文件的配置:
items.py :
1 import scrapy
2
3
4 class JdsplashItem(scrapy.Item):
5 # define the fields for your item here like:
6 # name = scrapy.Field()
7 name = scrapy.Field()
8 price = scrapy.Field()
9 p_store = scrapy.Field()
10 comment = scrapy.Field()
11 href = scrapy.Field()
12 passsettings.py:
1 import scrapy_splash
2 # Splash服务器地址
3 SPLASH_URL = 'http://192.168.99.100:8050'
4 # 开启Splash的两个下载中间件并调整HttpCompressionMiddleware的次序
5 DOWNLOADER_MIDDLEWARES = {
6 'scrapy_splash.SplashCookiesMiddleware': 723,
7 'scrapy_splash.SplashMiddleware': 725,
8 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
9 }
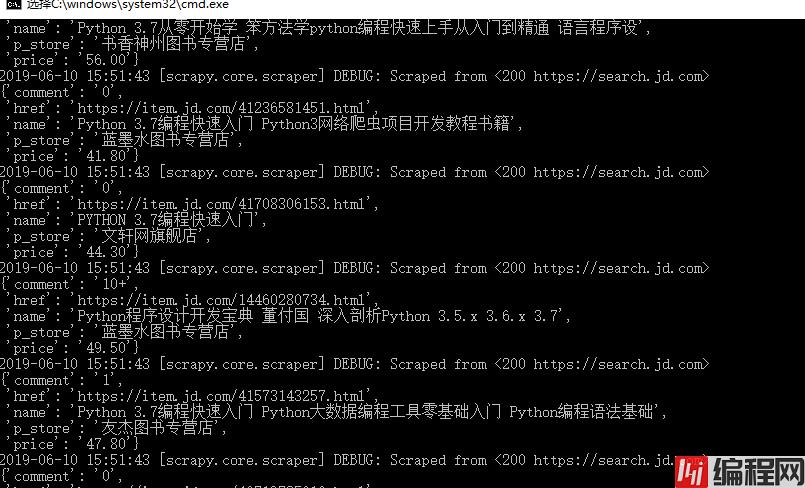
最后运行代码,可以看到书籍数据已经被爬取了:


0