


起因
为了督促自己更加积极地写博客,我希望有一个排名系统能让我看到自己的进步。但是博客园对用户的排名体系相对是比较少的,主要是推荐博客排行和积分排行;但它们人数少难度大,短期内难以进入排名。因此我决定自力更生,爬取一份博客园粉丝数排行榜。
为避免误(封)会(号),先做如下声明:
1、本排行榜非官方发布,是我通过爬虫得到的。
2、爬虫过程一直坚持网站友好原则:
(1)只查询网站公开内容(当然,非公开的我也不会)
(2)为避免对服务器造成压力,一直使用单线程发送请求,且每两个请求之间都设置了一定时间间隔
首先介绍一下爬虫的思路,不感兴趣的朋友可以直接拉到文章最后看结果,或者点击这里查看:博客园粉丝数排行榜(粉丝数不少于100)
思路基本分两步:1、初始化种子用户;2、迭代。
1、初始化种子用户
这一步的目标,是找到尽可能多的种子用户,种子用户最好发过文章,尤其是高质量文章,这样他们有较大概率有较多的粉丝。
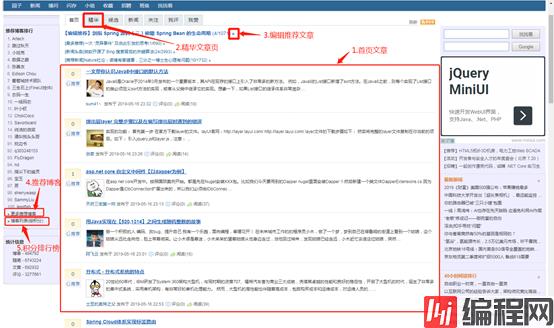
下面是我选取的种子用户来源,在博客园的对应位置在下图标出:
- 1、首页文章作者(200页):
- 2、精华文章作者(80+页)
- 3、编辑推荐文章作者(160+页)
- 4、推荐博客排行(100+人)
- 5、积分排行榜(3000人)
得到种子用户的用户名后,便可以在其个人页面获取昵称、粉丝数、园龄、文章首页等基本信息。例如,榜首(昵称:孤傲苍狼)的用户名是xdp-gacl,则他的个人页面是:https://home.cnblogs.com/u/xdp-gacl/
2、迭代
迭代的目的是从种子用户出发,找到其他粉丝数较多的用户;方法是获取种子用户“关注的人”——因为被关注的人有较大概率有更多的粉丝。用户关注的人在这里(还是以榜首孤傲苍狼为例):Https://home.cnblogs.com/u/xdp-gacl/followees/
因此一轮迭代的步骤是这样的:
(1)遍历当前用户列表,得到他们关注的用户;
(2)将这些关注的用户加入到当前用户列表。
如此循环往复,进行多轮迭代;直到不再有新的用户为止。
3、不足
有义务说明一下本排行榜的不足之处:
(1)爬取时间主要在5.10-5.19,排行榜不会反映在此期间及之后发生的变化(如用户粉丝数上涨)。
(2)通过这种方式,肯定无法爬取所有用户信息,但是粉丝数较多的用户被爬到的概率要大得多;因此为了尽可能保证准确性,排行榜只列出了粉丝数不少于100的用户。
(3)排行究竟漏掉了多少用户,仍是一个未知数,如果你认为有什么方法上的漏洞,或者有漏掉的用户,欢迎讨论。
本次爬虫使用的技术比较常规:语言使用python3,发送请求使用requests库,html解析使用BeautifulSoup,数据存储使用Redis;此外,爬虫过程中还会遇到动态加载页面、使用cookie进行身份校验等,都比较常见,不再赘述。
数据存储之所以选择Redis,主要是考虑到数据在内存中,访问快,且Redis提供了丰富的数据类型(如有序集合),使用起来比较方便;为了保证数据不丢失,一定要保证Redis开启了持久化,最好开启AOF持久化。
排行榜(粉丝数不小于100)可以点击链接查看:博客园粉丝数排行榜
前25名截图如下:
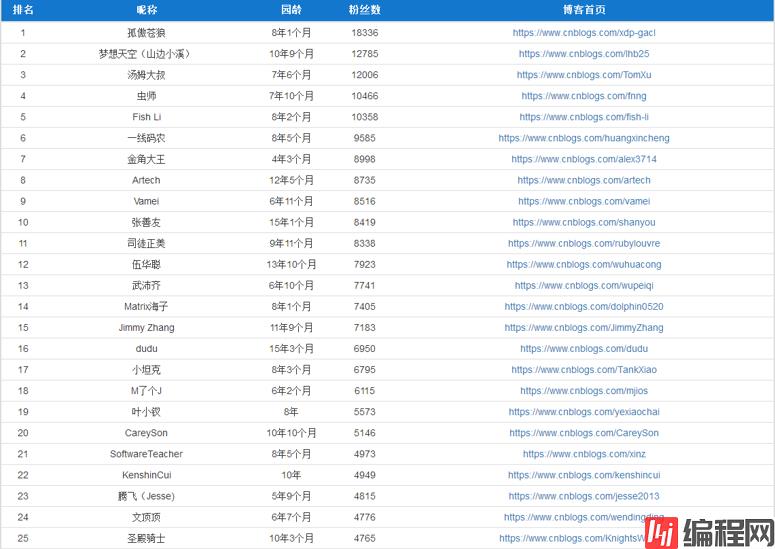
其中:
1、榜首是孤傲苍狼,有1.8w+粉丝,遥遥领先;在我爬虫这几天,涨了几十名粉丝,实在厉害。
2、粉丝数10000以上的,共有5位;粉丝数1000以上的,有286位;粉丝数100以上的,有3068位。
3、官方账号博客园团队有4644位粉丝,排第26位。
4、如果你的目标是进入前100名,至少需要2200+位粉丝;如果你的目标是进入前1000名,至少需要300+位粉丝。


0