


学习PyQuery库
好了,又是学习的时光啦,今天学习pyquery 来进行网页解析
常规导入模块(PyQuery库中的pyquery类)
from pyquery import PyQuery as pq
通常使用url初始化
doc = pq(url='Http://www.baidu.com')
文件初始化
doc = pq(filename='demo.html')
基本CSS选择器的使用,以起点中文网的为例子
doc = pq(url='https://www.qidian.com/free/all')
下面来获取小说名字信息
1.打开浏览器,进入要分析的网页
2.F12开发人员调试工具

3.进行元素检查
4.定位到爬取节点指定位置
5.分析一下 我们自己写 CSS选择器方法
id 使用的是# class 使用的是英文句号 空格代表 层级关系
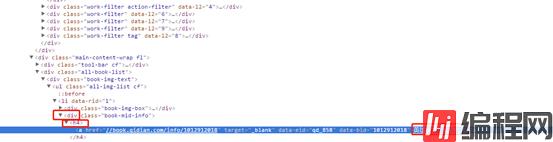
此时我们先使用语句来获取页面中的所有<h4>的元素
doc = pq(url='https://www.qidian.com/free/all')
a = doc('h4').items()
for i in a:
print(i)
迭代出所筛选出来的结果

但也会遇到上面的情况,共同是h4元素的,但筛选到我们不想要的数据。
这时我们可以采用往上级找,直到找到有区别的元素。

doc = pq(url='https://www.qidian.com/free/all')
a = doc('.book-mid-info h4').items()
for i in a:
print(i)得到了期待的数据!!!(要还是有那前两个,说明还定位不够准确,再往上一层走)

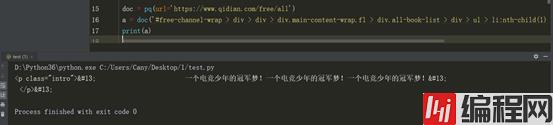
我们如果要获取简介内容,我们可以下图方式代码 获取子节点(记得find方法是子孙节点)
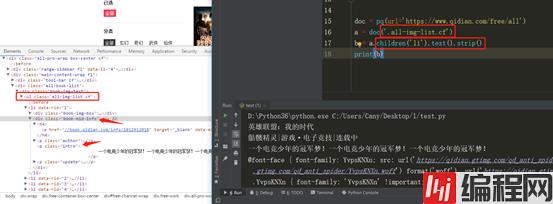
但上图也没抓取我们特别想要的信息呀,这时发现 我们所指定的解析底下有很多li标签 里标签底下又有很多内容,所以此时还得继续往下解析。
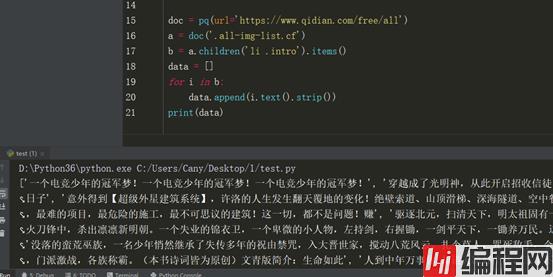
首先我们用children方法查找子节点,然后使用items方法来得到一个生成器,将数据遍历打印或者添加到列表中,方便数据存储和最终结果打印。
此时我们来获取一下小说的图片链接试试 利用attrs方法 来返回属性字典 进一步获取value值。
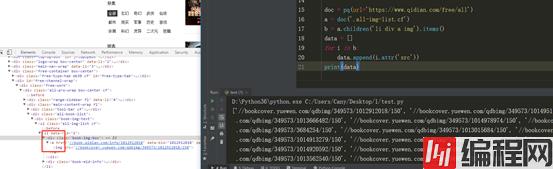
怎么来抓取解析节点 理清层级关系 利用好 F12来分析就好啦!!!
总结一下:
id 使用的是# class 使用的是英文句号 空格代表 层级关系
find()方法是遍历子孙节点
chlidren()方法是获取节点的子节点(看上面实例也支持往下继续选择节点)
parent()方法是获取节点的父节点
parents()方法是获取节点的所有父节点(下面实例从所有祖先节点中挑选出符合条件的节点)
parent = items.parents('.wrap')
print(parent)siblings()方法是获取兄弟节点(下面实例从所有兄弟节点中挑选出符合条件的节点)
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print(li.siblings('.active'))items()方法是用于遍历每一个节点结果
attr()方法是返回属性字典 进一步获取value值
text()方法是获取节点内部文本(Tips:当内容中前后出现\n 空格 可配合strip()来删除)
也可以百度学习下伪类选择器来获取节点数据,而且右键就能copy出表达式!!!


0