


三、Tornado进阶
3.1 Application
settings
debug,设置tornado是否工作在调试模式,默认为False即工作在生产模式。当设置debug=True 后,tornado会工作在调试/开发模式,在此种模式下,tornado为方便我们开发而提供了几种特性:
-
自动重启,tornado应用会监控我们的源代码文件,当有改动保存后便会重启程序,这可以减少我们手动重启程序的次数。需要注意的是,一旦我们保存的更改有错误,自动重启会导致程序报错而退出,从而需要我们保存修正错误后手动启动程序。这一特性也可单独通过autoreload=True设置;
-
取消缓存编译的模板,可以单独通过compiled_template_cache=False来设置;
-
取消缓存静态文件hash值,可以单独通过static_hash_cache=False来设置;
-
提供追踪信息,当RequestHandler或者其子类抛出一个异常而未被捕获后,会生成一个包含追踪信息的页面,可以单独通过serve_traceback=True来设置。
使用debug参数的方法:
路由映射
先前我们在构建路由映射列表的时候,使用的是二元元组,如:
[(r'/index', IndexHandle)]对于这个映射列表中的路由,实际上还可以传入多个信息,如:
对于路由中的字典,会传入到对应的RequestHandler的initialize()方法中:


from tornado.web import RequestHandler
class TestHandler(RequestHandler):
def initialize(self, subject):
self.subject = subject
def get(self):
self.write(self.subject)对于路由中的name字段,注意此时不能再使用元组,而应使用tornado.web.url来构建。name是给该路由起一个名字,可以通过调用RequestHandler.reverse_url(name)来获取该名子对应的url。
import tornado.web
import tornado.httpserver
import tornado.ioloop
import tornado.options
from tornado.options import options, define
from tornado.web import url, RequestHandler
define("port", default=8000, type=int, help="run server on the given port.")
class IndexHandle(RequestHandler):
"""主路由处理类"""
def get(self):
python_url = self.reverse_url("python_url")
self.write('<a href="%s">index</a>' %
python_url)
class TestHandle(RequestHandler):
"""主路由处理类"""
def initialize(self, subject):
self.subject = subject
def get(self):
"""对应Http的get请求"""
self.write(self.subject)
if __name__ == '__main__':
tornado.options.parse_command_line() # 输出多值选项
# print(tornado.options.options.test)
app = tornado.web.Application([
(r"/index", IndexHandle),
url(r"/python", TestHandle, {"subject":"python"}, name="python_url")
],
debug=True
)
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(tornado.options.options.port)
tornado.ioloop.IOLoop.current().start()
3.2 输入
1. 获取查询字符串参数
get_query_argument(name, default=_ARG_DEFAULT, strip=True)
从请求的查询字符串中返回指定参数name的值,如果出现多个同名参数,则返回最后一个的值。
default为设值未传name参数时返回的默认值,如若default也未设置,则会抛出tornado.web.MissingArgumentError异常。
strip表示是否过滤掉左右两边的空白字符,默认为过滤。
get_query_arguments(name, strip=True)
从请求的查询字符串中返回指定参数name的值,注意返回的是list列表(即使对应name参数只有一个值)。若未找到name参数,则返回空列表[]。
strip同前。
2. 获取请求体参数
get_body_argument(name, default=_ARG_DEFAULT, strip=True)
从请求体中返回指定参数name的值,如果出现多个同名参数,则返回最后一个的值。
default与strip同前。
get_body_arguments(name, strip=True)
从请求体中返回指定参数name的值,注意返回的是list列表(即使对应name参数只有一个值)。若未找到name参数,则返回空列表[]。
strip同前,不再赘述。
说明
对于请求体中的数据要求为字符串,且格式为表单编码格式(与url中的请求字符串格式相同),即key1=value1&key2=value2,HTTP报文头Header中的"Content-Type"为application/x-www-fORM-urlencoded 或 multipart/form-data。对于请求体数据为JSON或xml的,无法通过这两个方法获取。
3. 前两类方法的整合
get_argument(name, default=_ARG_DEFAULT, strip=True)
从请求体和查询字符串中返回指定参数name的值,如果出现多个同名参数,则返回最后一个的值。
default与strip同前。
get_arguments(name, strip=True)
从请求体和查询字符串中返回指定参数name的值,注意返回的是list列表(即使对应name参数只有一个值)。若未找到name参数,则返回空列表[]。
strip同前。
说明
对于请求体中数据的要求同前。 这两个方法最常用。
用代码来看上述六中方法的使用:
import tornado.web
import tornado.httpserver
import tornado.ioloop
import tornado.options
from tornado.options import options, define
from tornado.web import url, RequestHandler
define("port", default=8000, type=int, help="run server on the given port.")
class IndexHandle(RequestHandler):
"""主路由处理类"""
def post(self):
query_arg = self.get_query_argument("a")
query_args = self.get_query_arguments("a")
body_arg = self.get_body_argument("a")
body_args = self.get_body_arguments("a", strip=False)
arg = self.get_argument("a")
args = self.get_arguments("a")
# self.write(query_arg)
self.write(str(query_args))
if __name__ == '__main__':
tornado.options.parse_command_line() # 输出多值选项
# print(tornado.options.options.test)
app = tornado.web.Application([
(r"/index", IndexHandle)
],
debug=True
)
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(tornado.options.options.port)
tornado.ioloop.IOLoop.current().start()4. 关于请求的其他信息
RequestHandler.request 对象存储了关于请求的相关信息,具体属性有:
-
method HTTP的请求方式,如GET或POST;
-
host 被请求的主机名;
-
uri 请求的完整资源标示,包括路径和查询字符串;
-
path 请求的路径部分;
-
query 请求的查询字符串部分;
-
version 使用的HTTP版本;
-
headers 请求的协议头,是类字典型的对象,支持关键字索引的方式获取特定协议头信息,例如:request.headers["Content-Type"]
-
body 请求体数据; (获取json数据:request.body)
-
remote_ip 客户端的IP地址;
-
files 用户上传的文件,为字典类型,型如:
{ "form_filename1":[<tornado.httputil.HTTPFile>, <tornado.httputil.HTTPFile>], "form_filename2":[<tornado.httputil.HTTPFile>,], ... }tornado.httputil.HTTPFile是接收到的文件对象,它有三个属性:
-
filename 文件的实际名字,与form_filename1不同,字典中的键名代表的是表单对应项的名字;
-
body 文件的数据实体;
-
content_type 文件的类型。
-
这三个对象属性可以像字典一样支持关键字索引,如request.files["form_filename1"][0]["body"]。
-
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options
from tornado.options import options, define
from tornado.web import RequestHandler
define("port", default=8000, type=int, help="run server on the given port.")
class IndexHandler(RequestHandler):
def get(self):
self.write("hello tornado.")
class UploadHandler(RequestHandler):
def post(self):
files = self.request.files
img_files = files.get('img')
if img_files:
img_file = img_files[0]["body"]
file = open("./test", 'w+')
file.write(img_file)
file.close()
self.write("OK")
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application([
(r"/", IndexHandler),
(r"/upload", UploadHandler),
])
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.current().start()5. 正则提取uri
tornado中对于路由映射也支持正则提取uri,提取出来的参数会作为RequestHandler中对应请求方式的成员方法参数。若在正则表达式中定义了名字,则参数按名传递;若未定义名字,则参数按顺序传递。提取出来的参数会作为对应请求方式的成员方法的参数。
import tornado.web
import tornado.ioloop
import tornado.httpserver
import tornado.options
from tornado.options import options, define
from tornado.web import RequestHandler
define("port", default=8000, type=int, help="run server on the given port.")
class IndexHandler(RequestHandler):
def get(self):
self.write("hello tornado.")
class SubjectCityHandler(RequestHandler):
def get(self, subject, city):
self.write(("Subject: %s<br/>City: %s" % (subject, city)))
class SubjectDateHandler(RequestHandler):
def get(self, date, subject):
self.write(("Date: %s<br/>Subject: %s" % (date, subject)))
if __name__ == "__main__":
tornado.options.parse_command_line()
app = tornado.web.Application([
(r"/", IndexHandler),
(r"/sub-city/(.+)/([a-z]+)", SubjectCityHandler), # 无名方式
(r"/sub-date/(?P<subject>.+)/(?P<date>\d+)", SubjectDateHandler), # 命名方式
])
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(options.port)
tornado.ioloop.IOLoop.current().start()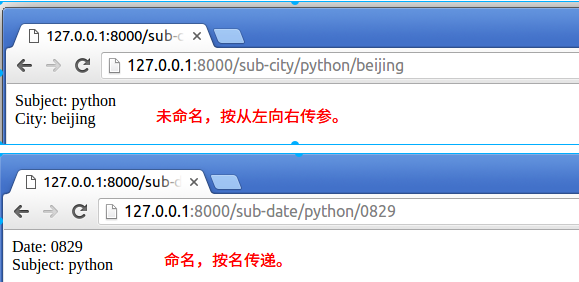
3.3 输出
1. write(chunk)
将chunk数据写到输出缓冲区。如我们在之前的示例代码中写的:
class IndexHandle(RequestHandler):
"""主路由处理类"""
def get(self):
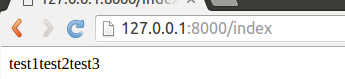
self.write("test1")在同一个处理方法中多次使用write方法
class IndexHandle(RequestHandler):
def get(self):
self.write("test1")
self.write("test2")
self.write("test3")write方法是写到缓冲区的,我们可以像写文件一样多次使用write方法不断追加响应内容,最终所有写到缓冲区的内容一起作为本次请求的响应输出。
利用write方法写json数据
class IndexHandle(RequestHandler):
"""主路由处理类"""
def get(self):
data = {
"name":"zhangsan",
"age":24,
"gender":1,
}
data_str = json.dumps(data)
self.write(data_str)实际上,我们可以不用自己手动去做json序列化,当write方法检测到我们传入的chunk参数是字典类型后,会自动帮我们转换为json字符串。
class IndexHandle(RequestHandler):
def get(self):
data = {
"name":"zhangsan",
"age":24,
"gender":1,
}
# data_str = json.dumps(data)
self.write(data)两种方式有什么差异?
对比一下两种方式的响应头header中Content-Type字段,自己手动序列化时为Content-Type:text/html; charset=UTF-8,而采用write方法时为Content-Type:application/json; charset=UTF-8。
write方法除了帮我们将字典转换为json字符串之外,还帮我们将Content-Type设置为application/json; charset=UTF-8。
2. set_header(name, value)
利用set_header(name, value)方法,可以手动设置一个名为name、值为value的响应头header字段。
用set_header方法来完成上面write所做的工作。
class IndexHandle(RequestHandler):
def get(self):
data = {
"name":"zhangsan",
"age":24,
"gender":1,
}
data_str = json.dumps(data)
self.write(data)
self.set_header("Content-Type", "application/json; charset=UTF-8")3. set_default_headers()
该方法会在进入HTTP处理方法前先被调用,可以重写此方法来预先设置默认的headers。注意:在HTTP处理方法中使用set_header()方法会覆盖掉在set_default_headers()方法中设置的同名header。
import tornado.web
import tornado.httpserver
import tornado.ioloop
import tornado.options
from tornado.options import options, define
from tornado.web import url, RequestHandler
import json
define("port", default=8000, type=int, help="run server on the given port.")
class IndexHandle(RequestHandler):
def set_default_headers(self):
print("执行了set_default_headers()")
# 设置get与post方式的默认响应体格式为json
self.set_header("Content-Type", "application/json; charset=UTF-8")
# 设置一个名为itcast、值为python的header
self.set_header("book", "python")
def get(self):
data = {
"name":"zhangsan",
"age":24,
"gender":1,
}
data_str = json.dumps(data)
self.write(data)
self.set_header("name", "test")
def post(self):
print("执行了post()")
data = {
"name":"zhangsan",
"age":24,
"gender":1,
}
data_json = json.dumps(data)
self.write(data_json)
if __name__ == '__main__':
tornado.options.parse_command_line() # 输出多值选项
# print(tornado.options.options.test)
app = tornado.web.Application([
(r"/index", IndexHandle)
],
debug=True
)
http_server = tornado.httpserver.HTTPServer(app)
http_server.listen(tornado.options.options.port)
tornado.ioloop.IOLoop.current().start()

4. set_status(status_code, reason=None)
为响应设置状态码。
参数说明:
-
status_code int类型,状态码,若reason为None,则状态码必须为下表中的。
-
reason string类型,描述状态码的词组,若为None,则会被自动填充为下表中的内容。
| Code | Enum Name | Details |
|---|---|---|
| 100 | CONTINUE | HTTP/1.1 RFC 7231, Section 6.2.1 |
| 101 | SWITCHING_PROTOCOLS | HTTP/1.1 RFC 7231, Section 6.2.2 |
| 102 | PROCESSING | WebDAV RFC 2518, Section 10.1 |
| 200 | OK | HTTP/1.1 RFC 7231, Section 6.3.1 |
| 201 | CREATED | HTTP/1.1 RFC 7231, Section 6.3.2 |
| 202 | ACCEPTED | HTTP/1.1 RFC 7231, Section 6.3.3 |
| 203 | NON_AUTHORITATIVE_INFORMATION | HTTP/1.1 RFC 7231, Section 6.3.4 |
| 204 | NO_CONTENT | HTTP/1.1 RFC 7231, Section 6.3.5 |
| 205 | RESET_CONTENT | HTTP/1.1 RFC 7231, Section 6.3.6 |
| 206 | PARTIAL_CONTENT | HTTP/1.1 RFC 7233, Section 4.1 |
| 207 | MULTI_STATUS | WebDAV RFC 4918, Section 11.1 |
| 208 | ALREADY_REPORTED | WebDAV Binding Extensions RFC 5842, Section 7.1 (Experimental) |
| 226 | IM_USED | Delta Encoding in HTTP RFC 3229, Section 10.4.1 |
| 300 | MULTIPLE_CHOICES | HTTP/1.1 RFC 7231, Section 6.4.1 |
| 301 | MOVED_PERMANENTLY | HTTP/1.1 RFC 7231, Section 6.4.2 |
| 302 | FOUND | HTTP/1.1 RFC 7231, Section 6.4.3 |
| 303 | SEE_OTHER | HTTP/1.1 RFC 7231, Section 6.4.4 |
| 304 | NOT_MODIFIED | HTTP/1.1 RFC 7232, Section 4.1 |
| 305 | USE_PROXY | HTTP/1.1 RFC 7231, Section 6.4.5 |
| 307 | TEMPORARY_REDIRECT | HTTP/1.1 RFC 7231, Section 6.4.7 |
| 308 | PERMANENT_REDIRECT | Permanent Redirect RFC 7238, Section 3 (Experimental) |
| 400 | BAD_REQUEST | HTTP/1.1 RFC 7231, Section 6.5.1 |
| 401 | UNAUTHORIZED | HTTP/1.1 Authentication RFC 7235, Section 3.1 |
| 402 | PAYMENT_REQUIRED | HTTP/1.1 RFC 7231, Section 6.5.2 |
| 403 | FORBIDDEN | HTTP/1.1 RFC 7231, Section 6.5.3 |
| 404 | NOT_FOUND | HTTP/1.1 RFC 7231, Section 6.5.4 |
| 405 | METHOD_NOT_ALLOWED | HTTP/1.1 RFC 7231, Section 6.5.5 |
| 406 | NOT_ACCEPTABLE | HTTP/1.1 RFC 7231, Section 6.5.6 |
| 407 | PROXY_AUTHENTICATION_REQUIRED | HTTP/1.1 Authentication RFC 7235, Section 3.2 |
| 408 | REQUEST_TIMEOUT | HTTP/1.1 RFC 7231, Section 6.5.7 |
| 409 | CONFLICT | HTTP/1.1 RFC 7231, Section 6.5.8 |
| 410 | GoNE | HTTP/1.1 RFC 7231, Section 6.5.9 |
| 411 | LENGTH_REQUIRED | HTTP/1.1 RFC 7231, Section 6.5.10 |
| 412 | PRECONDITION_FAILED | HTTP/1.1 RFC 7232, Section 4.2 |
| 413 | REQUEST_ENTITY_TOO_LARGE | HTTP/1.1 RFC 7231, Section 6.5.11 |
| 414 | REQUEST_URI_TOO_LONG | HTTP/1.1 RFC 7231, Section 6.5.12 |
| 415 | UNSUPPORTED_MEDIA_TYPE | HTTP/1.1 RFC 7231, Section 6.5.13 |
| 416 | REQUEST_RANGE_NOT_SATISFIABLE | HTTP/1.1 Range Requests RFC 7233, Section 4.4 |
| 417 | EXPECTATION_FAILED | HTTP/1.1 RFC 7231, Section 6.5.14 |
| 422 | UNPROCESSABLE_ENTITY | WebDAV RFC 4918, Section 11.2 |
| 423 | LOCKED | WebDAV RFC 4918, Section 11.3 |
| 424 | FAILED_DEPENDENCY | WebDAV RFC 4918, Section 11.4 |
| 426 | UPGRADE_REQUIRED | HTTP/1.1 RFC 7231, Section 6.5.15 |
| 428 | PRECONDITION_REQUIRED | Additional HTTP Status Codes RFC 6585 |
| 429 | TOO_MANY_REQUESTS | Additional HTTP Status Codes RFC 6585 |
| 431 | REQUEST_HEADER_FIELDS_TOO_LARGE Additional | HTTP Status Codes RFC 6585 |
| 500 | INTERNAL_SERVER_ERROR | HTTP/1.1 RFC 7231, Section 6.6.1 |
| 501 | NOT_IMPLEMENTED | HTTP/1.1 RFC 7231, Section 6.6.2 |
| 502 | BAD_GATEWAY | HTTP/1.1 RFC 7231, Section 6.6.3 |
| 503 | SERVICE_UNAVAILABLE | HTTP/1.1 RFC 7231, Section 6.6.4 |
| 504 | GATEWAY_TIMEOUT | HTTP/1.1 RFC 7231, Section 6.6.5 |
| 505 | HTTP_VERSION_NOT_SUPPORTED | HTTP/1.1 RFC 7231, Section 6.6.6 |
| 506 | VARIANT_ALSO_NEGOTIATES | Transparent Content Negotiation in HTTP RFC 2295, Section 8.1 (Experimental) |
| 507 | INSUFFICIENT_STORAGE | WebDAV RFC 4918, Section 11.5 |
| 508 | LOOP_DETECTED | WebDAV Binding Extensions RFC 5842, Section 7.2 (Experimental) |
| 510 | NOT_EXTENDED | An HTTP Extension Framework RFC 2774, Section 7 (Experimental) |
| 511 | NETWORK_AUTHENTICATION_REQUIRED | Additional HTTP Status Codes RFC 6585, Section 6 |
def get(self):
data = {
"name":"zhangsan",
"age":24,
"gender":1,
}
data_str = json.dumps(data)
self.write(data)
# self.set_header("name", "test")
# self.set_status(404) # 标准状态码,不用设置reason
# self.set_status(555,"666") # 非标准状态码,设置了reason
self.set_status(211) # 非标准状态码,未设置reason,错误5. redirect(url)
告知浏览器跳转到url。
class IndexHandler(RequestHandler):
"""对应/"""
def get(self):
self.write("主页")
class LoginHandler(RequestHandler):
"""对应/login"""
def get(self):
self.write('<form method="post"><input type="submit" value="登陆"></form>')
def post(self):
self.redirect("/")6. send_error(status_code=500, **kwargs)
抛出HTTP错误状态码status_code,默认为500,kwargs为可变命名参数。使用send_error抛出错误后tornado会调用write_error()方法进行处理,并返回给浏览器处理后的错误页面。
class IndexHandler(RequestHandler):
def get(self):
self.write("主页")
self.send_error(404, content="出现404错误")注意:默认的write\_error()方法不会处理send\_error抛出的kwargs参数,即上面的代码中content="出现404错误"是没有意义的。
尝试下面的代码会出现什么问题?
class IndexHandler(RequestHandler):
def get(self):
self.write("主页")
self.send_error(404, content="出现404错误")
self.write("结束") # 我们在send_error再次向输出缓冲区写内容
注意:使用send_error()方法后就不要再向输出缓冲区写内容了!
7. write_error(status_code, **kwargs)
用来处理send_error抛出的错误信息并返回给浏览器错误信息页面。可以重写此方法来定制自己的错误显示页面。
def write_error(self, status_code, **kwargs):
self.write("<h1>出错了!</h1>")
self.write("<p>错误名:%s</p>" % kwargs.get("title",""))
self.write("<p>错误详情:%s</p>" % kwargs.get("content",""))
def get(self):
err_title = "not found"
err_content = "未找到资源"
self.send_error(404, title=err_title, content=err_content)
3.4 接口与调用顺序
下面的接口方法是由tornado框架进行调用的,我们可以选择性的重写这些方法。
1. initialize()
对应每个请求的处理类Handler在构造一个实例后首先执行initialize()方法。在讲输入时提到,路由映射中的第三个字典型参数会作为该方法的命名参数传递,如:
class ProfileHandler(RequestHandler):
def initialize(self, database):
self.database = database
def get(self):
...
app = Application([
(r'/user/(.*)', ProfileHandler, dict(database=database)),
])此方法通常用来初始化参数(对象属性),很少使用。
2. prepare()
预处理,即在执行对应请求方式的HTTP方法(如get、post等)前先执行,注意:不论以何种HTTP方式请求,都会执行prepare()方法。
以预处理请求体中的json数据为例:
import json
class IndexHandler(RequestHandler):
def prepare(self):
if self.request.headers.get("Content-Type").startswith("application/json"):
self.json_dict = json.loads(self.request.body)
else:
self.json_dict = None
def post(self):
if self.json_dict:
for key, value in self.json_dict.items():
self.write("<h3>%s</h3><p>%s</p>" % (key, value))
def put(self):
if self.json_dict:
for key, value in self.json_dict.items():
self.write("<h3>%s</h3><p>%s</p>" % (key, value))3. HTTP方法
| 方法 | 描述 |
|---|---|
| get | 请求指定的页面信息,并返回实体主体。 |
| head | 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| post | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 |
| delete | 请求服务器删除指定的内容。 |
| patch | 请求修改局部数据。 |
| put | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| options | 返回给定URL支持的所有HTTP方法。 |
4. on_finish()
在请求处理结束后调用,即在调用HTTP方法后调用。通常该方法用来进行资源清理释放或处理日志等。注意:请尽量不要在此方法中进行响应输出。
5. set_default_headers()
6. write_error()
7. 调用顺序
我们通过一段程序来看上面这些接口的调用顺序。
class IndexHandler(RequestHandler):
def initialize(self):
print "调用了initialize()"
def prepare(self):
print "调用了prepare()"
def set_default_headers(self):
print "调用了set_default_headers()"
def write_error(self, status_code, **kwargs):
print "调用了write_error()"
def get(self):
print "调用了get()"
def post(self):
print "调用了post()"
self.send_error(200) # 注意此出抛出了错误
def on_finish(self):
print "调用了on_finish()"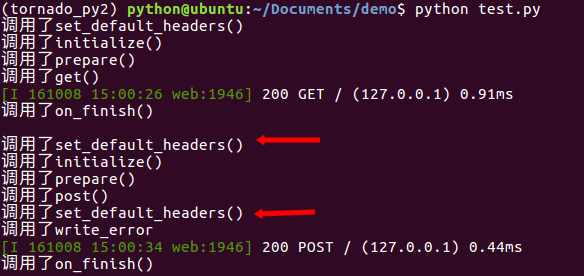
在正常情况未抛出错误时,调用顺序为:
- set_defautl_headers()
- initialize()
- prepare()
- HTTP方法
- on_finish()
在有错误抛出时,调用顺序为:
- set_default_headers()
- initialize()
- prepare()
- HTTP方法
- set_default_headers()
- write_error()
- on_finish()


0