


系列文章地址
ndarray 对象的内部机理
在前面的内容中,我们已经详细讲述了 ndarray 的使用,在本章的开始部分,我们来聊一聊 ndarray 的内部机理,以便更好的理解后续的内容。
1、ndarray 的组成
ndarray 与数组不同,它不仅仅包含数据信息,还包括其他描述信息。ndarray 内部由以下内容组成:
- 数据指针:一个指向实际数据的指针。
- 数据类型(dtype):描述了每个元素所占字节数。
- 维度(shape):一个表示数组形状的元组。
- 跨度(strides):一个表示从当前维度前进道下一维度的当前位置所需要“跨过”的字节数。
NumPy 中,数据存储在一个均匀连续的内存块中,可以这么理解,NumPy 将多维数组在内部以一维数组的方式存储,我们只要知道了每个元素所占的字节数(dtype)以及每个维度中元素的个数(shape),就可以快速定位到任意维度的任意一个元素。
dtype 及 shape 前文中已经有详细描述,这里我们来讲下 strides。
示例
ls = [[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]],
[[13, 14, 15, 16], [17, 18, 19, 20], [21, 22, 23, 24]]]
a = np.array(ls, dtype=int)
print(a)
print(a.strides)
输出:
[[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[[13 14 15 16]
[17 18 19 20]
[21 22 23 24]]]
(48, 16, 4)
上例中,我们定义了一个三维数组,dtype 为 int,int 占 4个字节。
第一维度,从元素 1 到元素 13,间隔 12 个元素,总字节数为 48;
第二维度,从元素 1 到元素 5,间隔 4 个元素,总字节数为 16;
第三维度,从元素 1 到元素 2,间隔 1 个元素,总字节数为 4。
所以跨度为(48, 16, 4)。
普通迭代
ndarray 的普通迭代跟 python 及其他语言中的迭代方式无异,N 维数组,就要用 N 层的 for 循环。
示例:
import numpy as np
ls = [[1, 2], [3, 4], [5, 6]]
a = np.array(ls, dtype=int)
for row in a:
for cell in row:
print(cell)
输出:
1
2
3
4
5
6
上例中,row 的数据类型依然是 numpy.ndarray,而 cell 的数据类型是 numpy.int32。
nditer 多维迭代器
NumPy 提供了一个高效的多维迭代器对象:nditer 用于迭代数组。在普通方式的迭代中,N 维数组,就要用 N 层的 for 循环。但是使用 nditer 迭代器,一个 for 循环就能遍历整个数组。(因为 ndarray 在内存中是连续的,连续内存不就相当于是一维数组吗?遍历一维数组当然只需要一个 for 循环就行了。)
1、基本示例
例一:
ls = [[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]],
[[13, 14, 15, 16], [17, 18, 19, 20], [21, 22, 23, 24]]]
a = np.array(ls, dtype=int)
for x in np.nditer(a):
print(x, end=", ")
输出:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24,
2、order 参数:指定访问元素的顺序
创建 ndarray 数组时,可以通过 order 参数指定元素的顺序,按行还是按列,这是什么意思呢?来看下面的示例:
例二:
ls = [[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]],
[[13, 14, 15, 16], [17, 18, 19, 20], [21, 22, 23, 24]]]
a = np.array(ls, dtype=int, order='F')
for x in np.nditer(a):
print(x, end=", ")
输出:
1, 13, 5, 17, 9, 21, 2, 14, 6, 18, 10, 22, 3, 15, 7, 19, 11, 23, 4, 16, 8, 20, 12, 24,
nditer默认以内存中元素的顺序(order='K')访问元素,对比例一可见,创建 ndarray 时,指定不同的顺序将影响元素在内存中的位置。
例三:nditer 也可以指定使用某种顺序遍历。
ls = [[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]],
[[13, 14, 15, 16], [17, 18, 19, 20], [21, 22, 23, 24]]]
a = np.array(ls, dtype=int, order='F')
for x in np.nditer(a, order='C'):
print(x, end=", ")
输出:
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24,
行主顺序(
order='C')和列主顺序(order='F'),参看 https://en.wikipedia.org/wiki/Row-_and_column-major_order。例一是行主顺序,例二是列主顺序,如果将 ndarray 数组想象成一棵树,那么会发现,行主顺序就是深度优先,而列主顺序就是广度优先。NumPy 中之所以要分行主顺序和列主顺序,主要是为了在矩阵运算中提高性能,顺序访问比非顺序访问快几个数量级。(矩阵运算将会在后面的章节中讲到)
3、op_flags 参数:迭代时修改元素的值
默认情况下,nditer 将视待迭代遍历的数组为只读对象(readonly),为了在遍历数组的同时,实现对数组元素值得修改,必须指定 op_flags 参数为 readwrite 或者 writeonly 的模式。
例四:
import numpy as np
a = np.arange(5)
for x in np.nditer(a, op_flags=['readwrite']):
x[...] = 2 * x
print(a)
输出:
[0 1 2 3 4]
4、flags 参数
flags 参数需要传入一个数组或元组,既然参数类型是数组,我原本以为可以传入多个值的,但是,就下面介绍的 4 种常用选项,我试了,不能传多个,例如 flags=['f_index', 'external_loop'],运行报错。
(1)使用外部循环:external_loop
将一维的最内层的循环转移到外部循环迭代器,使得 NumPy 的矢量化操作在处理更大规模数据时变得更有效率。
简单来说,当指定 flags=['external_loop'] 时,将返回一维数组而并非单个元素。具体来说,当 ndarray 的顺序和遍历的顺序一致时,将所有元素组成一个一维数组返回;当 ndarray 的顺序和遍历的顺序不一致时,返回每次遍历的一维数组(这句话特别不好描述,看例子就清楚了)。
例五:
import numpy as np
ls = [[[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]],
[[13, 14, 15, 16], [17, 18, 19, 20], [21, 22, 23, 24]]]
a = np.array(ls, dtype=int, order='C')
for x in np.nditer(a, flags=['external_loop'], order='C'):
print(x,)
输出:
[ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24]
例六:
b = np.array(ls, dtype=int, order='F')
for x in np.nditer(b, flags=['external_loop'], order='C'):
print(x,)
输出:
[1 2 3 4]
[5 6 7 8]
[ 9 10 11 12]
[13 14 15 16]
[17 18 19 20]
[21 22 23 24]
(2)追踪索引:c_index、f_index、multi_index
例七:
import numpy as np
a = np.arange(6).reshape(2, 3)
it = np.nditer(a, flags=['f_index'])
while not it.finished:
print("%d <%d>" % (it[0], it.index))
it.iternext()
输出:
0 <0>
1 <2>
2 <4>
3 <1>
4 <3>
5 <5>
这里索引之所以是这样的顺序,因为我们选择的是列索引(f_index)。直观的感受看下图:
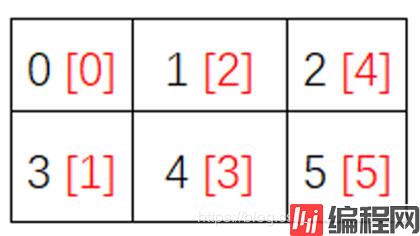
遍历元素的顺序是由
order参数决定的,而行索引(c_index)和列索引(f_index)不论如何指定,并不会影响元素返回的顺序。它们仅表示在当前内存顺序下,如果按行/列顺序返回,各个元素的下标应该是多少。
例八:
import numpy as np
a = np.arange(6).reshape(2, 3)
it = np.nditer(a, flags=['multi_index'])
while not it.finished:
print("%d <%s>" % (it[0], it.multi_index))
it.iternext()
输出:
0 <(0, 0)>
1 <(0, 1)>
2 <(0, 2)>
3 <(1, 0)>
4 <(1, 1)>
5 <(1, 2)>
5、同时迭代多个数组
说到同时遍历多个数组,第一反应会想到 zip 函数,而在 nditer 中不需要。
例九:
a = np.array([1, 2, 3], dtype=int, order='C')
b = np.array([11, 12, 13], dtype=int, order='C')
for x, y in np.nditer([a, b]):
print(x, y)
输出:
1 11
2 12
3 13
其他函数
1、flatten函数
flatten 函数将多维 ndarray 展开成一维 ndarray 返回。
语法:
flatten(order='C')
示例:
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]], dtype=int, order='C')
b = a.flatten()
print(b)
print(type(b))
输出:
[1 2 3 4 5 6]
<class 'numpy.ndarray'>
2、flat
flat 返回一个迭代器,可以遍历数组中的每一个元素。
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]], dtype=int, order='C')
for b in a.flat:
print(b)
print(type(a.flat))
输出:
1
2
3
4
5
6
<class 'numpy.flatiter'>


0