


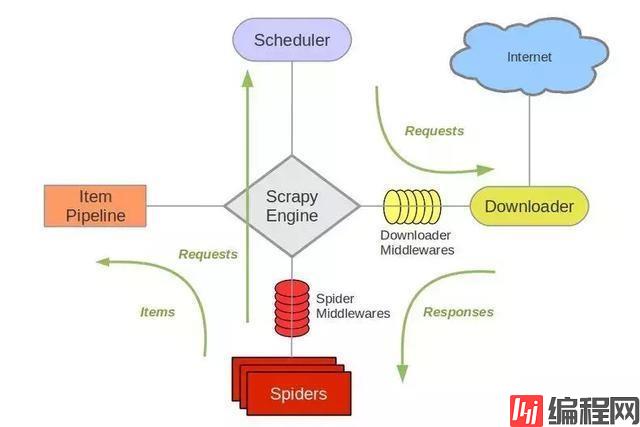
主要介绍,spiders,engine,scheduler,downloader,Item pipeline
scrapy常见命令如下:
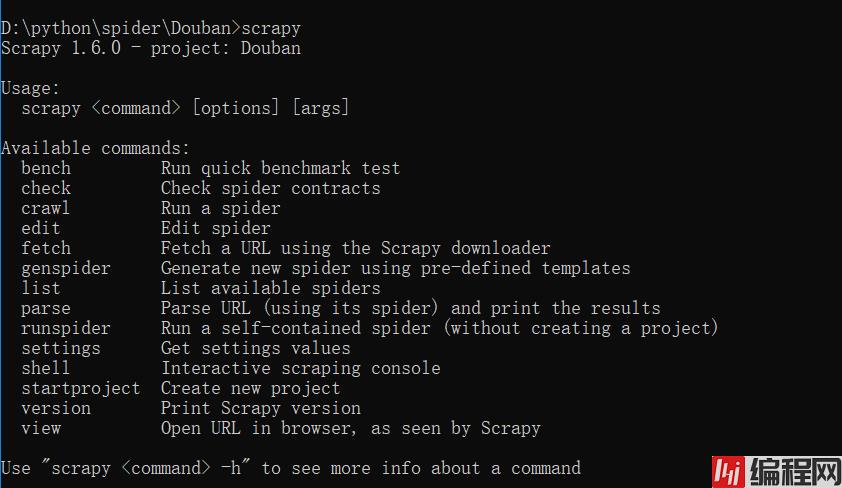
对应在scrapy文件中有,自己增加爬虫文件,系统生成items,pipelines,setting的配置文件就这些。
items写需要爬取的属性名,pipelines写一些数据流操作,写入文件,还是导入数据库中。主要爬虫文件写domain,属性名的xpath,在每页添加属性对应的信息等。
movieRank = scrapy.Field()
movieName = scrapy.Field()
Director = scrapy.Field()
movieDesc = scrapy.Field()
movieRate = scrapy.Field()
peopleCount = scrapy.Field()
movieDate = scrapy.Field()
movieCountry = scrapy.Field()
movieCateGory = scrapy.Field()
moviePost = scrapy.Field()import JSON
class DoubanPipeline(object):
def __init__(self):
self.f = open("douban.json","w",encoding='utf-8')
def process_item(self, item, spider):
content = json.dumps(dict(item),ensure_ascii = False)+"\n"
self.f.write(content)
return item
def close_spider(self,spider):
self.f.close()
这里xpath使用过程中,安利一个chrome插件xpathHelper。
allowed_domains = ['douban.com']
baseURL = "https://movie.douban.com/top250?start="
offset = 0
start_urls = [baseURL + str(offset)]
def parse(self, response):
node_list = response.xpath("//div[@class='item']")
for node in node_list:
item = DoubanItem()
item['movieName'] = node.xpath("./div[@class='info']/div[1]/a/span/text()").extract()[0]
item['movieRank'] = node.xpath("./div[@class='pic']/em/text()").extract()[0]
item['Director'] = node.xpath("./div[@class='info']/div[@class='bd']/p[1]/text()[1]").extract()[0]
if len(node.xpath("./div[@class='info']/div[@class='bd']/p[@class='quote']/span[@class='inq']/text()")):
item['movieDesc'] = node.xpath("./div[@class='info']/div[@class='bd']/p[@class='quote']/span[@class='inq']/text()").extract()[0]
else:
item['movieDesc'] = ""
item['movieRate'] = node.xpath("./div[@class='info']/div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()").extract()[0]
item['peopleCount'] = node.xpath("./div[@class='info']/div[@class='bd']/div[@class='star']/span[4]/text()").extract()[0]
item['movieDate'] = node.xpath("./div[2]/div[2]/p[1]/text()[2]").extract()[0].lstrip().split('\xa0/\xa0')[0]
item['movieCountry'] = node.xpath("./div[2]/div[2]/p[1]/text()[2]").extract()[0].lstrip().split('\xa0/\xa0')[1]
item['movieCategory'] = node.xpath("./div[2]/div[2]/p[1]/text()[2]").extract()[0].lstrip().split('\xa0/\xa0')[2]
item['moviePost'] = node.xpath("./div[@class='pic']/a/img/@src").extract()[0]
yield item
if self.offset <250:
self.offset += 25
url = self.baseURL+str(self.offset)
yield scrapy.Request(url,callback = self.parse)
这里基本可以爬虫,产生需要的json文件。
接下来是可视化过程。
我们先梳理一下,我们掌握的数据情况。
douban = pd.read_json('douban.json',lines=True,encoding='utf-8')
douban.info()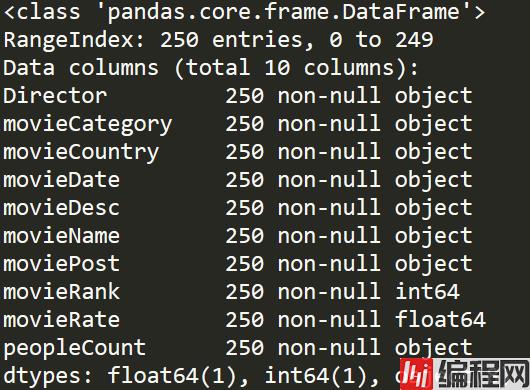
基本我们可以分析,电影国家产地,电影拍摄年份,电影类别以及一些导演在TOP250中影响力。
先做个简单了解,可以使用value_counts()函数。
douban = pd.read_json('douban.json',lines=True,encoding='utf-8')
df_Country = douban['movieCountry'].copy()
for i in range(len(df_Country)):
item = df_Country.iloc[i].strip()
df_Country.iloc[i] = item[0]
print(df_Country.value_counts())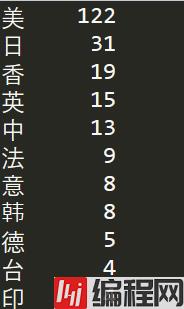
美国电影占半壁江山,122/250,可以反映好莱坞电影工业之强大。同样,日本电影和香港电影在中国也有着重要地位。令人意外是,中国大陆地区电影数量不是令人满意。豆瓣影迷对于国内电影还是非常挑剔的。
douban = pd.read_json('douban.json',lines=True,encoding='utf-8')
df_Date = douban['movieDate'].copy()
for i in range(len(df_Date)):
item = df_Date.iloc[i].strip()
df_Date.iloc[i] = item[2]
print(df_Date.value_counts()) 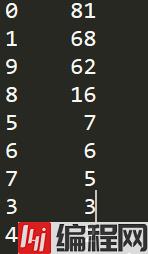
2000年以来电影数目在70%以上,考虑10代才过去9年和打分滞后性,总体来说越新的电影越能得到受众喜爱。这可能和豆瓣top250选取机制有关,必须人数在一定数量以上。
douban = pd.read_json('douban.json',lines=True,encoding='utf-8')
df_Cate = douban['movieCategory'].copy()
for i in range(len(df_Cate)):
item = df_Cate.iloc[i].strip()
df_Cate.iloc[i] = item[0]
print(df_Cate.value_counts()) 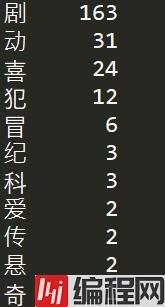
剧情电影情节起伏更容易得到观众认可。
下面展示几张可视化图片
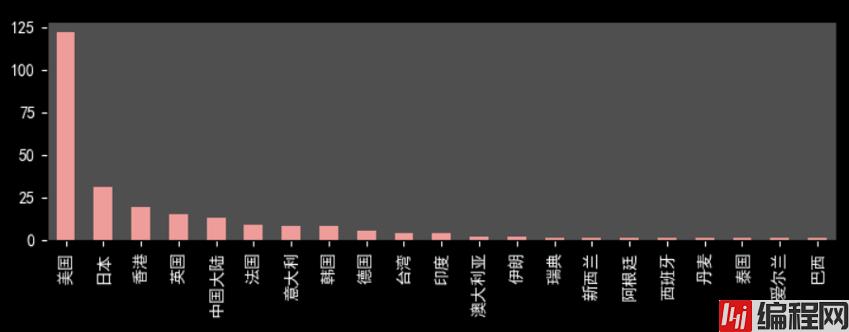
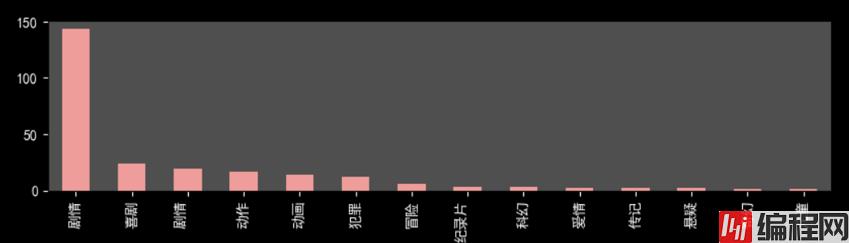
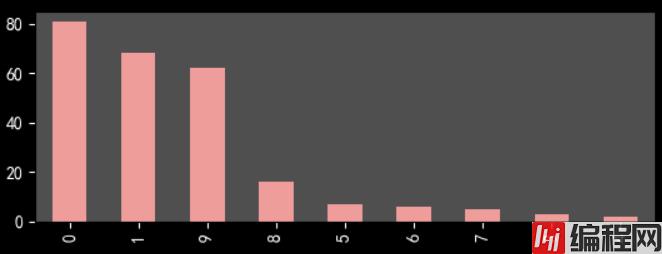
不太会用python进行展示,有些难看。其实,推荐用Echarts等插件,或者用excel,BI软件来处理图片,比较方便和美观。
第一次做这种爬虫和可视化,多有不足之处,恳请指出。


0