


最近偶然到博客园看了一下,距离上次的博客已经过去很多天了,阅读量却少得可怜,对于博客园小白来说感觉不是很友好(主要是心理不平衡),而且有些博客被其他网站不带出处的转载了,它的阅读量却很多。于是灵光一闪,决定写个程序增加一下阅读量。(仅用于学术交流,实际上我就试了一下,没有真正刷过)
一、原理
一般来说,阅读量是通过 ip 识别的,如果一个 ip 已经请求过了,下一次就不再增加阅读量。因此,想要增加阅读量,就需要不同的 ip 进行请求。大致清楚了之后,就可以开始写代码了。
二、获取代理 ip
国内有很多代理 ip 的网站,这里我就推荐 Http://31f.cn/http-proxy/ ,我们直接通过爬虫对 ip 和端口号进行获取,用 requests 和 BeautifulSoup ,由于这个网站的结构比较简单,就直接上代码了(记得导包)。
def getIPList(url="http://31f.cn/http-proxy/"):
proxies = []
headers = {
'User_Agent': 'Mozilla/5.0 (windows NT 6.1; WOW64) AppleWEBKit/537.36 (Khtml, like Gecko) Chrome/60.0.3112.101 Safari/537.36',
}
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, 'lxml')
ip_list = soup.select("body > div > table.table.table-striped > tr > td:nth-of-type(2)")
port_list = soup.select("body > div > table.table.table-striped > tr > td:nth-of-type(3)")
for i in range(len(port_list)):
proxies.append(ip_list[i].text + ":" + port_list[i].text)
return proxies如果想要获取更多的 ip 可以让这个方法不带参数,直接通过循环对多个页面进行抓取,毕竟大部分代理 ip 的有效期都很短。
三、发出请求
其实在一开始,我是直接对 https://www.cnblogs.com/lyuzt/p/10381107.html 进行请求的,但是我发现用 requests 请求这个网址并不能增加阅读量。因为其他的文件并没有像平时打开网站那样加载,而且增加阅读量应该是由另外的网址进行,所以要好好分析一下,到底是通过什么增加阅读量的。
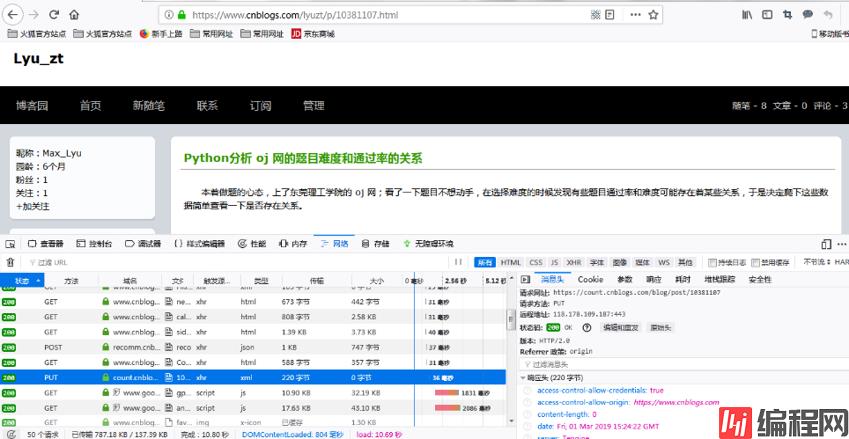
从控制台可以看到有一个 put 请求的,域名的开头为 count,这个才是阅读量增加的关键。所以改一下 url 再请求。
代码如下:
IPs = getIPList_2()
#print(IPs)
for i in range(len(IPs)):
print("开始请求")
user_agent = random.choice(user_agents)
proxy = IPs[i]
res = requests.get(blog_url, headers={'user_agent': user_agent}, proxies={'http': proxy})
print(user_agent + '\t' + proxy, end='\t')
print(res)
print("请求结束,准备下一次请求......")
time.sleep(10)ps:" user_agents " 这个变量是一个列表,相当于一个 user_agent 池,它的每个元素都是一个 user_agent 。这个就不展示了,可以上网复制。
四、总结
经过测试,博客的阅读量有所增加,但由于大部分代理 ip 的有效期短,基本上只能增加一点点。有些网站可以通过直接请求网址增加阅读量,有一些网站则是通过请求其他的文件增加的,如果觉得去分析有点麻烦可以直接用 selenium 让浏览器自动请求,至于这个方法就不尝试了。
虽然阅读量少,但我只试了一次,毕竟不能被这个数字左右,要端正心态。只要有技术,这些东西真的无所谓(不带出处转载这个就不能忍了,毕竟侵权了)。最后强调一下,这篇博客重在交流!


0