


前言
通过上一节可知,python6个序列的内置类型中,最常见的是列表和元组,但在Python中,最常用的数据类型却不是列表和元组,而是字符串。要想深入了解字符串,必须先掌握字符编码问题。因此本篇博文将讲解Python字符编码问题和Python字符串的具体方法!
一、Python字符编码
前提:计算机只认识两个数字:0和1,计算机在处理任何数据时,都要将数据转换为这两个数字的组合。
1.计算机的单位制
计算机在设计时,最小单位是 位(bit) ,位里面只能有两种情况,0或者1。位太过单调,只有两种情况,显然无法处理数据,所以引入 字节(byte) ,1字节=8位(1B = 8b),也就是说计算机一次能处理8位数据,早期的计算机都是8位的,现在的计算机有32位的,有64位的,显然现在的计算机相比以前运算能力大大提高。1字节能表示的最大整数为255(二进制1111 1111 = 十进制255)。对于存储介质来说,1个字节存储能力显然太弱,于是就有了KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB.....的出现:
1TB=1024GB 1GB=1024MB 1MB=1024KB 1KB=1024B 1B=8b
2.ASC码
由于计算机无法识别人类使用的语言,所以聪明的人类创造了一种映射关系,即让某一个数字映射到人类语言的某一个字符,比如:1---> A,这样计算机就可以识别人类语言了。因为第一台计算机是在美国诞生的,最早美国人只将常用的符号、大写英文和小写英文共127个字符编码映射到计算机中,这个编码表就是著名的ASC编码表,这个ASC码表最多只有8位,也就是说最多只能表示255个字符。
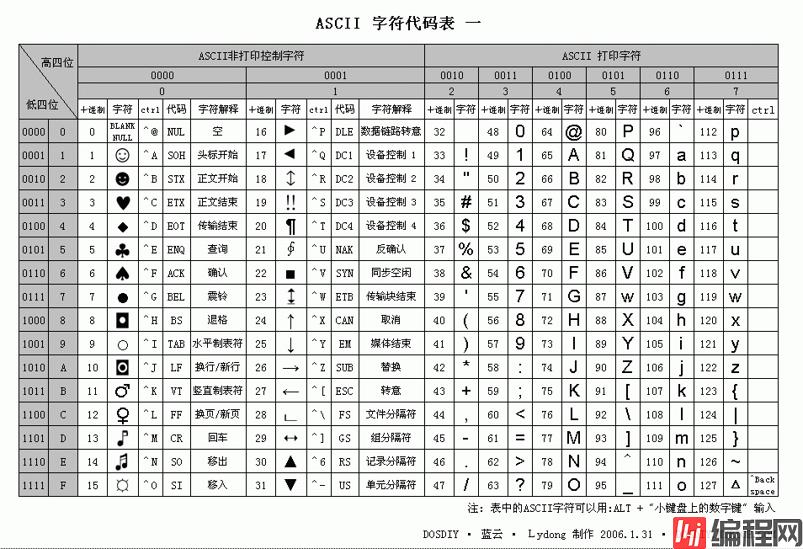
3.GB2312
后来计算机推向全球,中国人也要使用,但是早期的电脑里只有ASC码,中国人肯定不乐意啊,我大中华几千年的优秀文化,最牛的就是汉字了!然而汉字有好多啊,可不止255个,就算把ASC码表重新编一次,也不够用啊,再说,ASC码表谁也不能重新编人家,那怎么办呢?聪明的中国程序员对汉字进行了分区,分为94个区,每个区里有94个汉字。查找汉字时,找到它所在的区,再找到它所在区的哪个位置,就对一个汉字精确定位了,所以GB2312又称为区位码。GB2312中共收录6763个汉字,其中一级汉字3755个,二级汉字3008个,同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的682个字符。
4.GBK
后来,中国人又出现了新问题,GB2312支持的汉字太少了,随着国人人取名字越来越奇葩( ̄_ ̄|||),GB23132根本就无法处理,于是GBK就应运而生了。GBK支持的字符那是相当的多,现在中国计算机使用的依旧是GBK,不信你可以验证一下,再windows下的命令行里输入 chcp ,应该会显示Active code page:936 ,这个936就代表GBk。
5.Unicode
随着计算机在各国的普及,每个国家都有自己独特的编码方式,就出现了新的问题,日本人开发的软件在中国的计算机上运行的时候,会出现乱码,这样就会造成沟通障碍,为了解决类似问题,国际上的计算机头头组织决定让全世界的编码统一,于是Unicode就出现了,Unicode规定每个字符最少用16位表示。成功统一的编码,这就时Unicode。
6.UTF-8
Unicode的出现,几家欢喜几家愁啊,中国人觉得海星,美国人不乐意了,原来我的所有字符都是用8位(1字节)表示,现在莫名其妙就要用16位(2字节)表示,本来1GB的文件,现在变成2GB了,搁谁也受不了啊!那怎么办呢?于是UTF-8便出现了,UTF-8是对Unicode的压缩和优化,UTF-8不再规定必须最少用2个字节了,而是将字符进行分类:ASC码中的字符还是 1字节,欧洲使用2字节,东亚使用3字节。Perfect~~
7.python3字符编码
在Python3中,默认的字符编码是Unicode。
二、Python字符串
介绍完了字符编码的知识就该进入正题了,字符串作为Python最常用的数据类型,那一定有它独特的魅力,盘它!
先来看看字符串的具体方法:
In [1]: dir(str)
Out[1]:
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__fORMat__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']从上面可以看到,字符串的方法那是超级多啊⊙﹏⊙∥
注意:字符串同元组一样,其内部元素不可以被修改
1.初始化字符串
In [2]: name = 'MinuteSheep' # 单引号
In [3]: gender = 'M' # 一个字符也是字符串
In [4]: introduction = "I'm MinuteSheep" # 双引号
In [5]: info = ''' # 三引号
...: i am,
...: the,
...: best man
...: '''
# 前面已经说过他们的区别与用法,这里就不再重复了2.字符串索引
通过索引访问字符串元素:同列表用法一样
In [19]: name = 'MinuteSheep'
In [20]: name[0] # 同列表用法一样
Out[20]: 'M'
In [21]: name[5]
Out[21]: 'e'
In [22]: name[-1]
Out[22]: 'p'
In [23]: name[-6]
Out[23]: 'e'通过元素获取索引:有两种方法:str.index() , str.find()
In [24]: name = 'MinuteSheep'
In [25]: name.index('S') # 查找一个字符在字符串中的索引
Out[25]: 6
In [26]: name.index('te') # 查找子字符串在字符串中的索引,如果有多个子字符串,则返回第一个的索引
Out[26]: 4
In [31]: name.index('te',3,9) # 可以指定查找范围:第3个字符到第9个字符
Out[31]: 4
In [27]: name.index('Sp') # 当查找的字符或字符串不存在时,抛出没找到的异常
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-27-1d8e59855f71> in <module>
----> 1 name.index('Sp')
ValueError: substring not found
In [28]: name.find('S') # 用法和str.index()类似
Out[28]: 6
In [29]: name.find('te') # 用法和str.index()类似
Out[29]: 4
In [32]: name.find('te',3,9) # 用法和str.index()类似
Out[32]: 4
In [30]: name.find('Sp') # 当查找的字符或字符串不存在时,返回-1,就这点不一样
Out[30]: -13.字符串切片
使用方法同列表一样
In [34]: name = 'MinuteSheep'
In [35]: name[:] # 使用方法同列表一样
Out[35]: 'MinuteSheep'
In [36]: name[:4]
Out[36]: 'Minu'
In [37]: name[5:-1]
Out[37]: 'eShee'
In [38]: name[3:9:2]
Out[38]: 'ueh'4.字符串组合
字符串相加:直接用 + 号将两个字符串加起来,效果如下:
In [40]: name1 = 'MinuteSheep'
In [41]: name2 = 'Heenoor'
In [42]: name1 + name2
Out[42]: 'MinuteSheepHeenoor'字符串拼接:
In [51]: '-'.join('MinuteSheep') # 将字符串的每个字符用 - 拼接起来
Out[51]: 'M-i-n-u-t-e-S-h-e-e-p'
In [53]: '-'.join(['MinuteSheep','Heenoor']) # 将列表的每个元素用 - 拼接起来
Out[53]: 'MinuteSheep-Heenoor'
In [55]: '-'.join({'a':3,'b':5}) # 将字典的key值用 - 拼接起来
Out[55]: 'a-b'字符串居中:
In [56]: name = 'MinuteSheep'
In [58]: name.center(20,'*') # 使用str.center(数量,符号)方法将字符串居中
Out[58]: '****MinuteSheep*****'字符串乘法:同列表一样
In [60]: 'MinuteSheep' * 5
Out[60]: 'MinuteSheepMinuteSheepMinuteSheepMinuteSheepMinuteSheep'5.字符串统计
统计字符串长度:使用len()查看:
In [61]: name
Out[61]: 'MinuteSheep'
In [62]: len(name)
Out[62]: 11统计指定字符出现次数:使用str.count()方法:
In [61]: name
Out[61]: 'MinuteSheep'
In [63]: name.count('e')
Out[63]: 36.字符串转义
在Python中,有些字符被转义了,通常字符前面有 \ 代表转义字符,比如 '\n' 代表换行符,其他的转义字符见下表:
\(在行尾时) # 续行符
\\ # 反斜杠符号
\' # 单引号
\" # 双引号
\a # 响铃
\b # 退格(Backspace)
\e # 转义
\000 # 空
\n # 换行
\v # 纵向制表符
\t # 横向制表符
\r # 回车
\f # 换页
\oyy # 八进制数,yy代表的字符,例如:\o12代表换行
\xyy # 十六进制数,yy代表的字符,例如:\x0a代表换行
\other # 其它的字符以普通格式输出如果字符串需要这些字符又该怎么办呢,比如 s = '\n' ,运行代码后Python就会将 \n 识别为换行,如果字符串需要出现 \n,那就再转义即可,如 s = '\\n'
In [73]: s = '\n'
In [74]: s
Out[74]: '\n'
In [75]: print(s)
In [76]: s = '\\n'
In [77]: print(s)
\n但如果一个字符串中转义符过多的话,想要同时让这些转义符出现再字符串中,那岂不是要一个一个再转义,其实,Python中有一个简单的方法,那就是再创建的字符串前面加一个 r 或者 R ,例如:
In [78]: s = r'\n'
In [79]: print(s)
\n
In [80]: s = R'\n'
In [81]: print(s)
\n7.字符串格式化
字符串的格式化可以说是一种动态编程,相当于创建一个模板,填写内容即可,例如:你好,我叫XXX,我今年XXX岁了,我的电话号码是XXX。盘它!
使用 % :
In [82]: name = 'MinuteSheep'
In [83]: 'Hello, I am %s' % name # 只有一个%时,可以不加括号
Out[83]: 'Hello, I am MinuteSheep'
In [84]: name2 = 'Heenoor'
In [86]: 'Hi, i am %s, I am the friend of %s' % (name2, name) # 大于一个%时,必须加括号
Out[86]: 'Hi, i am Heenoor, I am the friend of MinuteSheep'以上代码就做到了一个动态编程,用%s占位,之后用其他内容替换它。
其实,在Python中,%s属于字符串占位符,还有其他的占位符:
%c # 格式化字符及其ASCII码
%s # 格式化字符串,最常用
%d # 格式化整数,比较常用
%u # 格式化无符号整型
%o # 格式化无符号八进制数
%x # 格式化无符号十六进制数
%X # 格式化无符号十六进制数(大写)
%f # 格式化浮点数字,可指定小数点后的精度,比较常用
%e # 用科学计数法格式化浮点数
%E # 作用同%e,用科学计数法格式化浮点数
%g # %f和%e的简写
%G # %f 和 %E 的简写
%p # 用十六进制数格式化变量的地址其中,%d 和 %f 可以指定整数与小数的位数:
In [87]: '%2d' % 345
Out[87]: '345'
In [88]: '%5d' % 345
Out[88]: ' 345'
In [89]: '%.2f' % 3.4567
Out[89]: '3.46'
In [90]: '%5.2f' % 345.5678
Out[90]: '345.57'使用 format :
Python中还有另外一种字符串格式化方法 format,这也是Python官方建议的方式
In [92]: 'I am {0} you are {1} he is {2}'.format('A','B','C')
Out[92]: 'I am A you are B he is C'
In [93]: 'I am {0} you are {0} he is {2}'.format('A','B','C')
Out[93]: 'I am A you are A he is C'
In [94]: 'I am {2} you are {0} he is {1}'.format('A','B','C')
Out[94]: 'I am C you are A he is B'
In [96]: 'I am {name1} you are {name2} he is {name3}'.format(name1='A',name2='B',name3='C')
Out[96]: 'I am A you are B he is C'
In [97]: 'I am {name1} you are {name2} he is {name3}'.format(name3='A',name2='B',name1='C')
Out[97]: 'I am C you are B he is A'
# 懂了哇,弟弟们8.字符串编码转换
上面说了一长串的编码,到这里来实际操作一下
使用 str.encode(编码方式) 进行编码:
In [98]: name_unicode = '小绵羊'
In [99]: name_utf8 = name_unicode.encode('utf8') # 将unicode编码为utf8,默认为utf8,可以省略不写
In [100]: name_gbk = name_unicode.encode('gbk') # 将unicode编码为gbk
In [101]: name_unicode
Out[101]: '小绵羊'
In [102]: name_utf8 # 可以看到明显和gbk的编码方式不一样
Out[102]: b'\xe5\xb0\x8f\xe7\xbb\xb5\xe7\xbe\x8a'
In [103]: name_gbk
Out[103]: b'\xd0\xa1\xc3\xe0\xd1\xf2'使用 bytes.decode(当前字符串编码) 解码成 unicode:
In [105]: name_utf8.decode('utf8') # 将utf8解码为unicode,括号里默认为utf8,可以省略不写
Out[105]: '小绵羊'
In [106]: name_gbk.decode('gbk') # 将gbk解码为unicode
Out[106]: '小绵羊'9.字符串判断方法集合
如果仔细去看字符串的方法,发现有好多is开头的方法,这些方法其实都是判断方法,一起来看看哇:
In [107]: name = 'MinuteSheep'
In [108]: name.isalnum() # 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False
Out[108]: True
In [109]: name.isalpha() # 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
Out[109]: True
In [110]: name.isdecimal() # 如果 string 只包含十进制数字则返回 True 否则返回 False.
Out[110]: False
In [111]: name.isdigit() # 如果 string 只包含数字则返回 True 否则返回 False.
Out[111]: False
In [112]: name.islower() # 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False
Out[112]: False
In [113]: name.isnumeric() # 如果 string 中只包含数字字符,则返回 True,否则返回 False
Out[113]: False
In [114]: name.isspace() # 如果 string 中只包含空格,则返回 True,否则返回 False.
Out[114]: False
In [115]: name.istitle() # 如果 string 是标题化的(见 title())则返回 True,否则返回 False
Out[115]: False
In [116]: name.isupper() # 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False
Out[116]: False还有两个很重要的判断方法:
In [117]: name
Out[117]: 'MinuteSheep'
In [119]: name.startswith('mi') # 判断开头,区分大小写
Out[119]: False
In [120]: name.startswith('Mi')
Out[120]: True
In [122]: name.endswith('ep') # 判断结尾,区分大小写
Out[122]: True10.字符串其他方法
In [123]: name = 'minutesheep'
In [124]: name.capitalize() # 把字符串的第一个字符大写
Out[124]: 'Minutesheep'
In [129]: name = 'MinuteSheep'
In [130]: name.ljust(20) # 返回一个原字符串左对齐,并使用空格填充至长度20的新字符串
Out[130]: 'MinuteSheep '
In [132]: name.rjust(20) # 返回一个原字符串右对齐,并使用空格填充至长度20的新字符串
Out[132]: ' MinuteSheep'
In [133]: name.lower() # 转换 string 中所有大写字符为小写.
Out[133]: 'minutesheep'
In [134]: name = ' MinuteSheep '
In [135]: name.strip() # 截掉 string 两边边的空格
Out[135]: 'MinuteSheep'
In [136]: name.lstrip() # 截掉 string 左边的空格
Out[136]: 'MinuteSheep '
In [137]: name.rstrip() # 截掉 string 右边的空格
Out[137]: ' MinuteSheep'
In [138]: max(name) # 返回字符串 str 中最大的字母。
Out[138]: 'u'
In [139]: min(name) # 返回字符串 str 中最小的字母。
Out[139]: ' '
In [140]: name.replace(' ','-') # 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次.
Out[140]: '-----MinuteSheep-----'
In [141]: name.replace(' ','-',3)
Out[141]: '--- MinuteSheep '
In [142]: name = 'i am minutesheep'
In [143]: name.split(' ') # 把string按照空格分割,默认为空格
Out[143]: ['i', 'am', 'minutesheep']
In [144]: name.split()
Out[144]: ['i', 'am', 'minutesheep']
In [145]: name.swapcase() # 翻转 string 中的大小写
Out[145]: 'I AM MINUTESHEEP'
In [146]: name.title() # 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写
Out[146]: 'I Am Minutesheep'
In [147]: name.upper() # 转换 string 中的小写字母为大写
Out[147]: 'I AM MINUTESHEEP'至此,Python字符串方法全部记录完,卒


0