


前言:
边学习,边创造是一件开心的事情,因为你会清楚的认识到自己的状态,以及那充满内心的成就感,因此从写爬虫开始学习python是一个简单粗暴的提升路线,不知不觉了解很多东西
这里以半次元为例对爬虫整体流程以及部分细节进行简单汇总,如果有不正确的地方还请大家指出
---------------------------------------分割线----------------------------------------------
话不多说,我们打开待爬的页面

会发现这个页面运用了ajax技术,只有向下滑动才会触发请求,如果我们按照现在页面地址爬取,也只能是得到部分相册,既然是ajax,这里我们打开F12 网络工具 刷新页面
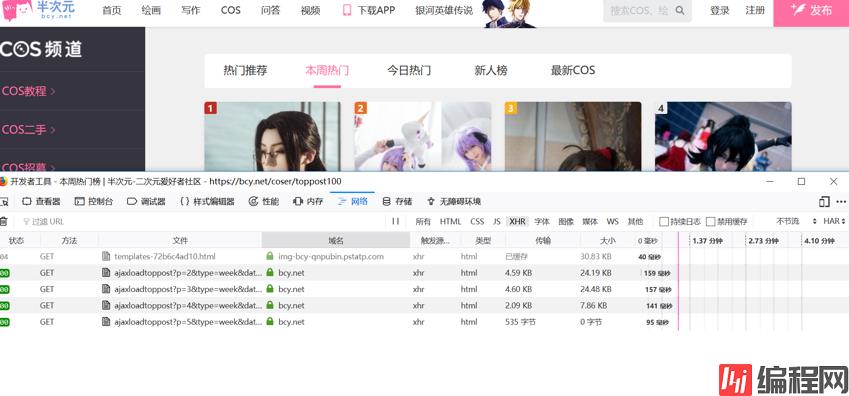
滑动到底部,会发现又多了四条GET请求,查看请求的url ,会发现这些url之间不同的只有 p 的值 p=1, p=2, p=3, p=4,p=5

知道了这些,就可以开始编写Python文件,请求页面内容了
1、创建一个AlbumUrl类 , 开始获取页面所有相册的url
import requests
from bs4 import BeautifulSoup
album_urls = [] #相册url列表
headers = {
"Host": "bcy.net",
"User-Agent": "Mozilla/5.0 (windows NT 10.0; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0"
}
#获取相册url
class AlbumUrl():
def __init__(self, url, url2):
self.url = url
self.url2 = url2
def page(self, start, end):
for i in range(start, end):
url = self.url % i
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
after_bs = BeautifulSoup(response.text, 'lxml')
li_s = after_bs.find_all('li', class_='js-smallCards _box') #提取li标签内容
for li in li_s:
list_a = li.find_all('a', class_='db posr ovf') #提取a标签内容
for a in list_a:
a_href = a.get('href') #取出部分url 进行拼接
album_urls.append(self.url2 + a_href)
if __name__ == '__main__':
url = 'https://bcy.net/coser/index/ajaxloadtoppost?p=%s'
url2 = 'Https://bcy.net'
spider = AlbumUrl(url, url2)
spider.page(1, 6) #分析出来的页数编写完毕,运行一下, 无误,把这些相册url保存到列表,等待逐个分析里面的图片内容

2、新建一个ImgUrl类 继承threading.Thread类 因为这里我打算用多线程, 导入相应的模块
import requests
from bs4 import BeautifulSoup
import threading
import re
import time
album_urls = [] #相册url列表
all_img_urls = [] #所有图片
lock = threading.Lock() #互斥锁
headers = {
"Host": "bcy.net",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0"
}
#抓取每个相册里面图片url
class ImgUrl(threading.Thread):
def run(self):
while len(album_urls) > 0: #只要不为空 就一直抓取
lock.acquire() #上锁
album_url = album_urls.pop()
lock.release() # 解锁
try:
response = requests.get(album_url, headers=headers, timeout=3)
response.encoding = 'utf-8'
re_obj = re.compile('"path(.*?)w650', re.S)
r = (re_obj.findall(response.text))
print("正在分析" + album_url)
after_bs = BeautifulSoup(response.text, 'lxml')
lock.acquire() # 上锁
for title in after_bs.find_all('title'):
global album_title
album_title = (str(title.get_text())).split('-')[0]
for i in range(len(r)):
img_url = r[i].replace(r'\\u002F', '/')[5:] + 'w650.jpg' #拼接字符串,完成每张图片url
img_dict = {album_title: img_url} #相册名和图片url存入字典
all_img_urls.append(img_dict)
print(album_title + '获取成功')
lock.release() # 解锁
time.sleep(0.5)
except:
pass
#获取相册url
class AlbumUrl():
def __init__(self, url, url2):
self.url = url
self.url2 = url2
def page(self, start, end):
for i in range(start, end):
url = self.url % i
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
after_bs = BeautifulSoup(response.text, 'lxml')
li_s = after_bs.find_all('li', class_='js-smallCards _box') #提取li标签内容
for li in li_s:
list_a = li.find_all('a', class_='db posr ovf') #提取a标签内容
for a in list_a:
a_href = a.get('href') #取出部分url 进行拼接
album_urls.append(self.url2 + a_href)
if __name__ == '__main__':
url = 'https://bcy.net/coser/index/ajaxloadtoppost?p=%s'
url2 = 'https://bcy.net'
spider = AlbumUrl(url, url2)
spider.page(1, 5) #分析出来的页数
for x in range(5):
t = ImgUrl()
t.start()# 这里需要注意的是,图片的url并不是直接暴露的,里面惨杂了一些字符串,这里我们运用正则来进行筛选,然后用replace进行相应字符串的替换
开五个线程运行一下, 无误,可以准备写入文件了

3、新建一个Download类 同样继承threading.Thread类 ,用于下载图片到本地
import os
import requests
from bs4 import BeautifulSoup
import threading
import re
import time
album_urls = [] #相册url列表
all_img_urls = [] #所有图片
lock = threading.Lock() #互斥锁
headers = {
"Host": "bcy.net",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:63.0) Gecko/20100101 Firefox/63.0"
}
#抓取每个相册里面图片url
class ImgUrl(threading.Thread):
def run(self):
while len(album_urls) > 0: #只要不为空 就一直抓取
lock.acquire() #上锁
album_url = album_urls.pop()
lock.release() # 解锁
try:
response = requests.get(album_url, headers=headers, timeout=3)
response.encoding = 'utf-8'
re_obj = re.compile('"path(.*?)w650', re.S)
r = (re_obj.findall(response.text))
print("正在分析" + album_url)
after_bs = BeautifulSoup(response.text, 'lxml')
lock.acquire() # 上锁
for title in after_bs.find_all('title'):
global album_title
album_title = (str(title.get_text())).split('-')[0]
for i in range(len(r)):
img_url = r[i].replace(r'\\u002F', '/')[5:] + 'w650.jpg' #拼接字符串,完成每张图片url
img_dict = {album_title: img_url}
all_img_urls.append(img_dict)
print(album_title + '获取成功')
lock.release() # 解锁
time.sleep(0.5)
except:
pass
num = 0
#下载图片
class Download(threading.Thread):
def run(self):
while True:
lock.acquire() #上锁
if len(all_img_urls) == 0:
lock.release() #解锁
continue
else:
img_dict = all_img_urls.pop()
lock.release() #解锁
for key, values in img_dict.items(): #把键值取出
try:
os.mkdir(key)
print(key + '创建成功')
except:
pass
global num
num += 1
filename = str(num) + '.' + str(values).split('.')[-1] #给每张图片重新命名
filepath = os.path.join(key, filename)
session = requests.Session() #这里使用会话请求
http_obj = requests.adapters.HTTPAdapter(max_retries=20) #每次连接的最大失败重试次数
session.mount('https://', http_obj) #增加请求类型
session.mount('http://', http_obj)
try:
response = session.get(values) #读取会话
with open(filepath, 'wb', buffering=4*1024) as image:
image.write(response.content)
image.close()
print(filepath + '下载完毕')
except:
pass
time.sleep(0.1)
#获取相册url
class AlbumUrl():
def __init__(self, url, url2):
self.url = url
self.url2 = url2
def page(self, start, end):
for i in range(start, end):
url = self.url % i
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
after_bs = BeautifulSoup(response.text, 'lxml')
li_s = after_bs.find_all('li', class_='js-smallCards _box') #提取li标签内容
for li in li_s:
list_a = li.find_all('a', class_='db posr ovf') #提取a标签内容
for a in list_a:
a_href = a.get('href') #取出部分url 进行拼接
album_urls.append(self.url2 + a_href)
if __name__ == '__main__':
url = 'https://bcy.net/coser/index/ajaxloadtoppost?p=%s'
url2 = 'https://bcy.net'
spider = AlbumUrl(url, url2)
spider.page(1, 5) #分析出来的页数
threads = []
for x in range(5):
t = ImgUrl()
t.start()
threads.append(t)
for tt in threads: #设置堵塞,避免线程抢先
tt.join()
for x in range(5):
down = Download()
down.start()#这里需要注意的是,请求图片的时候不能直接请求,否则会发生异常,这里用会话请求并设置相应的类型
好,开五个线程运行一下,看结果如何

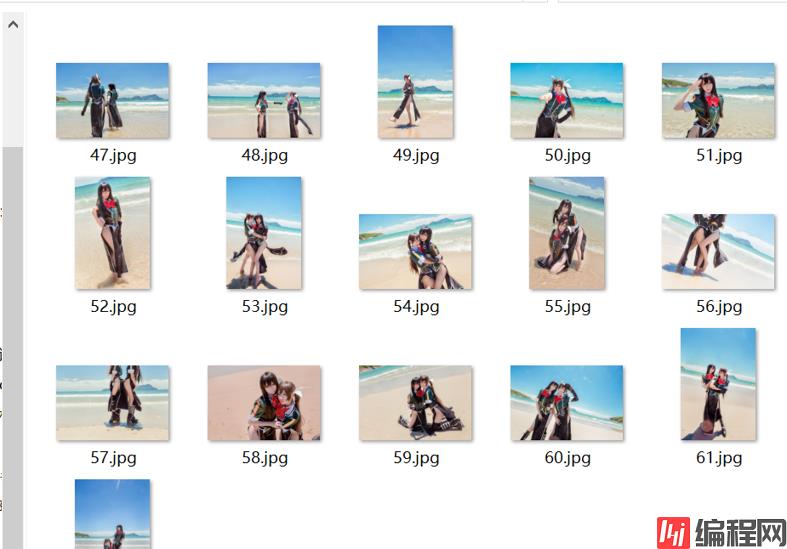
到此为止,三步爬取半次元热门图片,演示完毕,其实不光是热门,我们也可以换成别的链接进行分析爬取,包括全站,整体原理都是类似的,一些请求细节需要理解
还有,bs4简直就是爬虫神器


0