


本系列来自《编写高质量代码 改善python程序的91个建议》的读书笔记整理。
本章主要内容
建议8:利用assert语句来发现问题建议9:数据交换值时不推荐使用中间交换变量建议11:理解枚举替代实现的缺陷建议12:不推荐使用type来进行类型检查建议13:尽量转换为浮点类型再做除法建议14:警惕eval()的安全漏洞建议15:使用enumerate()获取序列迭代的索引和值建议16:分清==与is的适用场景建议17:考虑兼容性,尽可能使用Unicod建议18:构建合理的包层次来管理module
建议8:利用assert语句来发现问题
1)__debug__的值默认为True,且只读,无法修改(py2.7)。
2)断言是有代价的,对性能产生一定影响。禁用断言的方法是在运行脚本的时候加上-O标记(不优化字节码,而是忽略与断言相关的语句)。
使用断言注意点:
1)不要滥用,这是使用断言的最基本的原则;
2)如果Python本身的异常能够处理就不要再使用断言;
3)不要使用断言来检查用户的输入;
4)在函数调用后,当需要确认返回值是否合理时可以使用断言;
5)当条件时业务逻辑继续下去的先决条件时,可以使用断言。
建议9:数据交换值时不推荐使用中间交换变量
1 >>> from timeit import Timer
2 >>> Timer('temp=x;x=y;y=temp','x=2;y=3').timeit()
3 0.03472399711608887
4 >>> Timer('x,y=y,x','x=2;y=3').timeit()
5 0.031581878662109375建议10:充分利用Lazy evaluation的特性
Lazy evaluation常被译作“延时计算”或“惰性计算”,指的是仅仅在真正需要执行计算的时候才计算表达式的值。典型例子:生成器表达式。
1)避免不必要的计算,带来性能上的提升;
2)节省空间,使用无限循环的数据结构成为可能。
建议11:理解枚举替代实现的缺陷
1)替代方法:使用类属性;借助函数;使用collections.namedtuple.
1 >>> from collections import namedtuple
2 >>> Seasons=namedtuple('Seasons','spring Summer Autumn Winter')._make(xrange(4))
3 >>> print Seasons
4 Seasons(Spring=0, Summer=1, Autumn=2, Winter=3)
5 >>> print Seasons.Autumn
6 2 2)替代缺陷:允许枚举值重复;支持无意义的操作.
1 >>> Seasons._replace(Spring=2) # 不合理
2 Seasons(Spring=2, Summer=1, Autumn=2, Winter=3)
3 >>> Seasons.Summer+Seasons.Autumn == Seasons.Winter # 无意义
4 True 3)py2.7的替代方案(py3.4后引入Enum类型):flufl.enum
1 from flufl.enum import Enum
2
3
4 class Seasons(Enum):
5 Spring = "Spring"
6 Summer = 2
7 Autumn = 3
8 Winter = 4
9
10 Seasons = Enum('Seasons', 'Spring Summer Autumn Winter')
11 print Seasons
12 print Seasons.Summer.value 建议12:不推荐使用type来进行类型检查
1)基于内建类型扩展的用户自定义类型,type函数并不能准确返回结果;
2)在旧式类中,所有类的实例的type值都相等。
3)可以用isinstance()函数检查。
建议13:尽量转换为浮点类型再做除法
当涉及除法运算的时候尽量先将操作数转换成浮点类型再做运算。
浮点数不精确性导致的无限循环:
1 >>> i=1
2 >>> while i!=1.5:
3 ... i=i+0.1
4 ... print i建议14:警惕eval()的安全漏洞
1 # -*-coding:UTF-8 -*-
2
3 import sys
4 from math import *
5
6
7 def ExpCalcBot(string):
8 try:
9 print 'Your answer is', eval(string)
10 except NameError:
11 print "The expression you enter is not valid."
12
13
14 while True:
15 print 'Please enter a number or operation. Enter e to complete. '
16
17 inputStr = raw_input()
18 if inputStr == 'e':
19 sys.exit()
20 elif repr(inputStr) != ' ':
21 ExpCalcBot(inputStr)输入:__import__("os").system("dir") 显示当前目录下的所有文件.
__import__("os").system("del */Q") 删除当前目录下的所有文件.
因此,在实际应用过程中国呢如果使用对象不是信任源,应该尽量避免使用eval,在需要使用eval的地方可以用安全性更好的ast.literal_eval替代。
建议15:使用enumerate()获取序列迭代的索引和值
注意,在获取迭代过程中字典的key和value,应该使用如下iteritems()方法。
1 >>> person={'name': 'Josn', 'age': 19, 'hobby': 'football'}
2 >>> for k,v in person.iteritems():
3 ... print k, ":", v建议16:分清==与is的适用场景
1 >>> a="Hi"
2 >>> b="Hi"
3 >>> a is b
4 True
5 >>> a==b
6 True
7 >>> a1 ="I am using long string for testing" # 注意区分
8 >>> b1 ="I am using long string for testing"
9 >>> a1 is b1
10 False
11 >>> a1==b1
12 True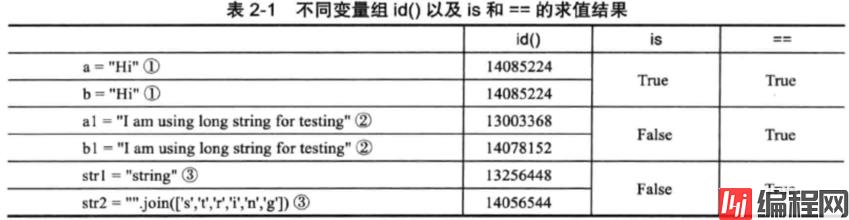

is:表示的是对象标识符,检查对象的标识符是否一致,也就是比较两个对象在内存中是否拥有同一块内存空间;
==:表示的是值相等,用来判断两个对象的值是否相等,可以被重载。
字符串驻留(string interning)机制:对于较小的字符串,为了提高系统性能会保留其值的一个副本,当创建新的字符串时直接指向该副本即可。
建议17:考虑兼容性,尽可能使用Unicode
python内建的字符串有两种类型:str和Unicode,共同祖先为basestring。
windows本地默认编码是CP936。
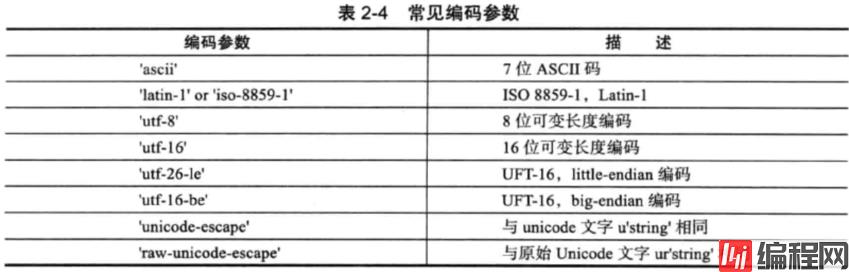

解码:str.decode([编码参数[,错误处理]])
编码:str.encode([编码参数[,错误处理]])
错误处理参数有3种方式:
(1)strict:默认值,抛出UnicodeError异常;
(2)ignore:忽略不可转换的字符;
(3)replace:将不可转换字符用?代替。
有些软件在保存UTF-8编码时,会在文件最开始地方插入不可见的BOM,可以利用codecs解决。
1 import codecs
2
3
4 content = open('manage.py', 'r').read()
5
6 if content[:3] == codecs.BOM_UTF8:
7 content = content[:3]
8
9 print content.decode("utf-8") 编码声明的三种方式:
1 # coding=<encoding name> #方式一
2 #!/usr/bin/env python
3
4 # -*- coding:<encoding name> -*- #方式二
5
6 #!/usr/bin/env python
7 # vim:set fileencoding=<encoding name> #方式三建议18:构建合理的包层次来管理module
包中__init__.py文件的作用:1)使包和普通目录区分;
2)在该文件中声明模块级别的import语句从而使其变成包级别可见;
3)通过该文件中定义__all__变量,控制需要导入的子包或者模块。
使用包的好处:
使用包的好处:
1)合理组织代码,便于维护和使用;
2)能够有效地避免名称空间冲突。


0