


实例化的时候python会自动把实例本身传给self
__dict__ 查看属性
类调用的时候不会自动传递参数
s1.tell_info()
School.tell_info(s1)
增 .key=什么;减 del;改 =;查 .调用
类属性包括数据属性和函数属性
实例属性只有数据属性
说的就是数据属性,点的方式调用的就是属性,把函数封装成数据属性,使得外部在调用的时候感觉不到内部的逻辑。既可以访问实例属性还可以访问类属性。
函数前加@property调用的时候不用加括号,看起来就像数据属性(例如r1.cal_area,如果函数内部是return,则需要print才能打印)
函数开头加@claSSMethod跟类绑定,变成一个专门跟类有关的方法(取消和实例的捆绑),函数的参数是cls即类名。可以访问类的数据属性和函数属性,但不能访问实例的属性。
类调用类方法的时候传不传参数?有自动传递参数。
类方法用来访问类属性。
1 class Foo:
2 x=1
3 # @classmethod
4 def test(cls):
5 print('aaa')
6 f1=Foo()
7 f1.test()
8 Foo.test()输出
aaa
Traceback (most recent call last):
File "F:/PyCharmProjects/Python_s3/复习练习/practice.py", line 122, in <module>
Foo.test()
TypeError: test() missing 1 required positional argument: 'cls'
(如果第八行传入参数Foo,或者第三行去掉注释打印结果为两行aaa,不会报异常)
函数前加@staticmethod,跟类和实例无关的操作。名义上的归属类管理,不能使用类变量和实例变量,是类的工具包。不能访问类和实例属性。
如果在class里单独写个函数,前面啥也不加,实例是无法调用它的,这样写毫无意义。
大类由一个个小类拼接而成。类跟类之间没共同点,但是有关联,用组合实现。
1 class School:
2 def __init__(self,name,addr):
3 self.name=name
4 self.addr=addr
5
6 def zhao_sheng(self):
7 print('%s 正在招生' %self.name)
8
9 class Course:
10 def __init__(self,name,price,period,school):
11 self.name=name
12 self.price=price
13 self.period=period
14 self.school=school
15
16
17
18 s1=School('oldboy','北京')
19 s2=School('oldboy','南京')
20 s3=School('oldboy','东京')
21
22 # c1=Course('linux',10,'1h','oldboy 北京')
23 c1=Course('linux',10,'1h',s1)
24
25 print(c1.__dict__)
26 print(c1.school.name)
27 print(s1)输出
{'name': 'linux', 'price': 10, 'period': '1h', 'school': <__main__.School object at 0x0000021A650C99E8>}
oldboy
<__main__.School object at 0x0000021A650C99E8>
类的继承有两层意义:1.改变 2.扩展
什么时候用继承?当类之间有很多相同的功能,提取这些共同的功能做成基类,用继承比较好
而,当类显著不同,且较小的类是较大的类所需要的组件时,用组合比较好
类名(参数) #__init__中需要的参数
派生是衍生新的东西,继承就是延续之前的功能
继承具有两种含义:1.继承基类的方法,并且做出自己的改变或者扩展(减少代码重用);2.声明某子类兼容于某基类,定义一个接口类,子类继承接口类,并且实现接口中定义的方法。
(第一种含义意义并不大,甚至通常是有害的,因为它使得子类和基类出现强耦合,而程序倡导解耦合;而第二种含义的意义非常重要,叫做接口继承,接口就是方法(一个具体的函数),子类必须实现父类的方法)
Python的类可以继承多个类,Java和C#则只能继承一个类。
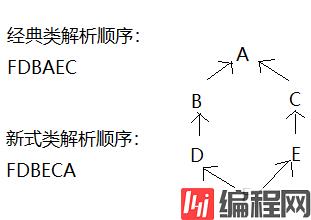
经典类继承(基类没有任何继承关系,不继承object)(python2):深度优先
新式类继承(python3默认;python2):广度优先
__mro__生成解析顺序元组(经典类没这个方法) 最后一步找的object说明再往上没父类了
MRO遵循三条准则:1.子类会先于父类被检查;2.多个父类会根据他们在MRO元组中的顺序被检查;3.若下一
个类存在两个合法的选择,选择第一个父类
真正的接口继承要import abc 基类参数写metaclass=abc.ABCMeta @abc.abstractmethod 确保子类必须实现接口
归一化,就是只要是基于同一个接口实现的类,那么所有的这些类产生的对象在使用时,从用法上来说都一样。
好处在于:
1. 归一化让使用者无需关心对象的类是什么,只需要的知道这些对象都具备某些功能就可以了,这极大地降低了使用者的使用难度。
2. 归一化使得高层的外部使用者可以不加区分的处理所有接口兼容的对象集合
子类中如何调用父类的方法?(不好用,扩展性差,父类变更之后子类需要变更的地方太多)__init__:在子类的__init__中写父类名.__init__(包括self在内参数) 方法:vehicle.run(self)
实例化或对象调用方法时会动到self
super().方法(参数,不用传self)不用写父类名了
选课系统
1 import pickle #数据传送模块
2 import hashlib #产生哈希值标识身份
3 import time
4 def create_md5():
5 m = hashlib.md5()
6 m.update(str(time.time()).encode('utf-8'))
7 return m.hexdigest()
8
9 class Base:
10 def save(self):
11 with open('school.db','wb') as f:
12 pickle.dump(self,f)
13
14 class School(Base):
15 def __init__(self,name,addr):
16 self.id=create_md5()
17 self.name=name
18 self.addr=addr
19
20 class Course(Base):
21 def __init__(self,name,price,period,school):
22 self.id=create_md5()
23 self.name=name
24 self.price=price
25 self.period=period
26 self.school=school
27
28 school_obj = pickle.load(open('school.db', 'rb'))
29 print(school_obj.name,school_obj.addr)
30 # s1=School('oldboy','北京')
31 # s1.save() 

0