


第三关开始才算是进入正题了。
输入网址 Http://www.heibanke.com/lesson/crawler_ex02/,直接跳转到了 http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex02/,显示如下
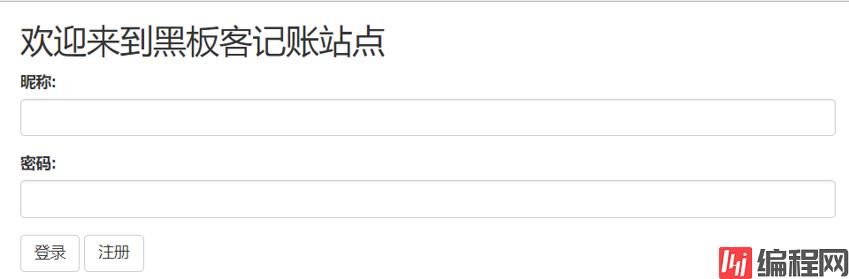
仔细看一下这个网址,显然,这是一个登陆网址,next参数应该是登录成功后跳转网页的地址。注册登录后,显示第三关:
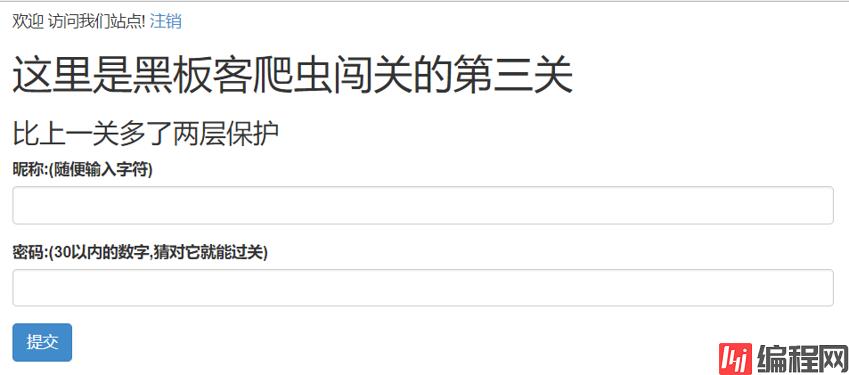
首先可以肯定的是,必须要先登录,并保持登录状态,否则是爬不过关的。界面提示有两层保护,这应该就是第一层。
先注册了一个账号,然后用代码尝试登录,post 用户名密码之后,print 一下响应的 html,发现并不是我看到的第三关的内容,说明登录没有成功。看一下里面有一句话:You are seeing this message because this site requires a CSRF cookie when submitting fORMs. This cookie is required for security reasons, to ensure that your browser is not being hijacked by third parties.
简单的说,就是为了防止CSRF攻击(其实就是黑板课设的障碍),需要一个cookie。
退出登录,回到登录界面,打开开发者工具(我用的是谷歌浏览器),追踪一下网络请求,发现登录的时候,除了用户名密码,还有一个 csrfmiddlewaretoken 参数,而 csrfmiddlewaretoken 参数来自于 cookie 中的 csrftoken。
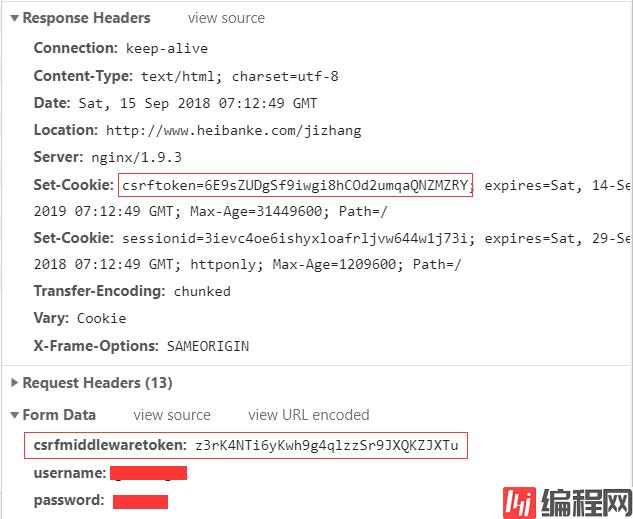
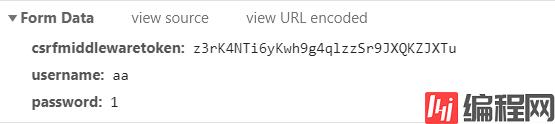
先 get 一下登录页面,从返回的 session 中获取 cookie 值中获取 csrftoken 值,连同用户名密码一起 post,print 响应的 html,结果正确。
然后就是跟第二关一样,暴力破解密码了。保险起见,也追踪了下请求,发现机制跟登录是一样的,也需要csrfmiddlewaretoken 参数,一样处理就好了。
这样思路就理清了,每次 post 用户名密码之前,先 get 请求一下,从服务器发给你的 cookie 中获取 csrftoken 的值作为 post 时的 csrfmiddlewaretoken 参数即可。
代码如下:
import re
import requests
import time
def main():
url_login = 'http://www.heibanke.com/accounts/login/?next=/lesson/crawler_ex02/'
url = 'http://www.heibanke.com/lesson/crawler_ex02/'
session = requests.Session()
# 获取cookie
session.get(url_login)
token = session.cookies['csrftoken']
# 登录
session.post(url_login, data={'csrfmiddlewaretoken': token, 'username': '', 'passWord': ''})
for psd in range(30):
print(f'test password {psd}')
session.get(url)
token = session.cookies['csrftoken']
r = session.post(url, data={'csrfmiddlewaretoken': token, 'username': 'aa', 'password': psd})
html = r.text
if '密码错误' not in html:
m = re.search('(?<=\<h3\>).*?(?=\</h3\>)', html)
print(m.group())
m = re.search('(\<).*?href="([^"]*?)".*?(\>下一关\</a\>)', html)
print(f'下一关 http://www.heibanke.com{m.group(2)}')
return
else:
time.sleep(1)
if __name__ == '__main__':
main()


0