



前言
最近大家讨论最多的就是《流浪地球》了,偶尔刷逼乎,狗血的事情也是层出不穷,各种撕逼大战,有兴趣的小伙伴可以自行搜索。
截止目前,《流浪地球》已上映20天,累计票房43.94亿,豆瓣评分7.9分。博主是正月初七看的,票价有点小贵,整体效果还算可以,虽然剧情有点尴尬,各种镜头切换有时候看的稀里糊涂,但还是给了豆瓣四星好评。
爬取
逼乎上很多高手,对《流浪地球》在豆瓣的评分做了细思缜密的分析,有兴趣的也去自己搜索,这里主要是爬取《流浪地球》的好、中、差短评并分词分析。
爬取数据:
import os
import requests
import codecs
from bs4 import BeautifulSoup
# 给请求指定一个请求头来模拟chrome浏览器
global headers
headers = {'User-Agent': 'Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWEBKit/537.36 (Khtml, like Gecko) Chrome/54.0.2840.99 Safari/537.36',
'cookie': 'network→www.douban.com→headers查看cookie'}
server = 'https://movie.douban.com/subject/26266893/comments'
# 定义存储位置
global save_path
save_path = os.getcwd()+"\\Text\\"+'短评_好评.txt'
global page_max
page_max = 25
global comments
comments = ''
# 获取短评内容
def get_comments(page):
req = requests.get(url=page)
html = req.content
html_doc = str(html, 'utf-8')
bf = BeautifulSoup(html_doc, 'html.parser')
comment = bf.find_all(class_="short")
for short in comment:
global comments
comments = comments + short.text
# 写入文件
def write_txt(chapter, content, code):
with codecs.open(chapter, 'a', encoding=code)as f:
f.write(content)
# 主方法
def main():
for i in range(0, page_max):
try:
page = server + '?start='+str(i*20)+'&limit=20&sort=new_score&status=P&percent_type=h'
get_comments(page)
write_txt(save_path, comments, 'utf8')
except Exception as e:
print(e)
if __name__ == '__main__':
main()
最终发现,每个类型只能查询出 500 条短评,后面就看不到了,不知道是否豆瓣有意而为之给隐藏了,哈哈哈原来是没登录导致的(headers 设置下 cookie 就可以)。最后读了一下好评文本居然有40MB,不过最终还是按照500条采样。
# 好评500条,中评500条,差评500条,自行更换 percent_type 参数即可。
# Https://movie.douban.com/subject/26266893/comments?start=0&limit=20&sort=new_score&status=P&percent_type=h
# https://movie.douban.com/subject/26266893/comments?start=0&limit=20&sort=new_score&status=P&percent_type=m
# https://movie.douban.com/subject/26266893/comments?start=0&limit=20&sort=new_score&status=P&percent_type=l分析
使用结巴中文分词第三方库来进行高频分析:
import jieba
import os
txt = open(os.getcwd()+"\\Text\\"+"短评_差评.txt", "r", encoding='utf-8').read()
Words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(0, 10):
word, count = items[i]
print("{0:<6}{1:>6}".fORMat(word, count))
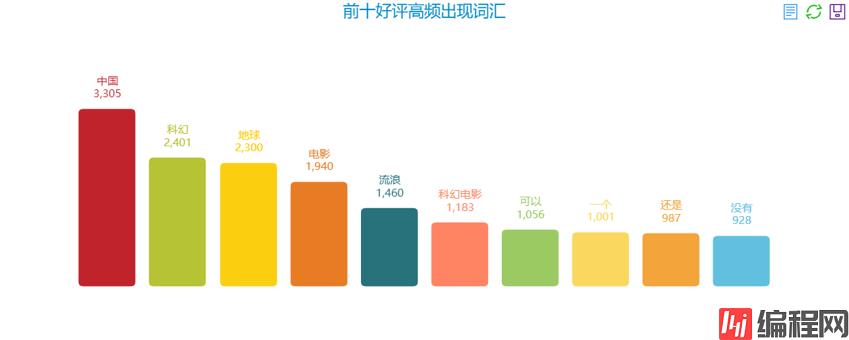
前十好评高频出现词汇:
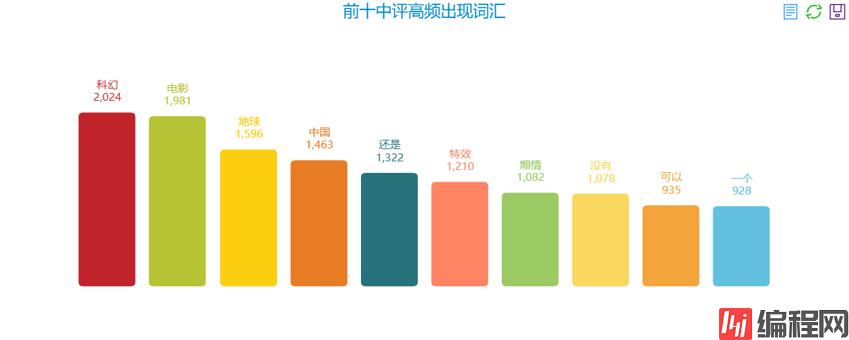
前十中评高频出现词汇:
前十差评高频出现词汇:
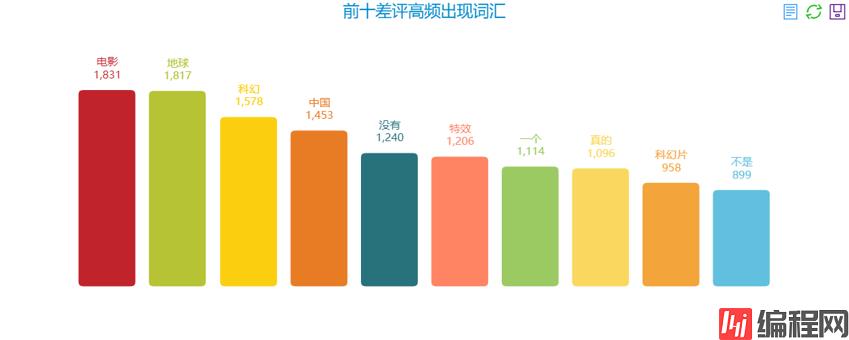
前十高频词汇分析基本没有任何参考价值,基本就是科幻、地球、特效、电影,这些都是电影的基本元素,其它的都是一些中性词汇。
然后,我们分析了11-30的高频词汇,提取了部分关键词:
好评:
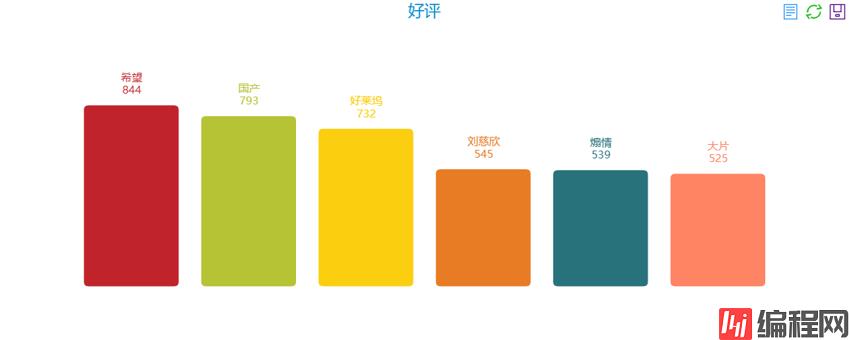
结论:国产希望好莱坞科幻煽情大片。大家注意一下,前三十高频词汇只出现了刘慈欣的名字,并没有出现吴京的名字。
中评:
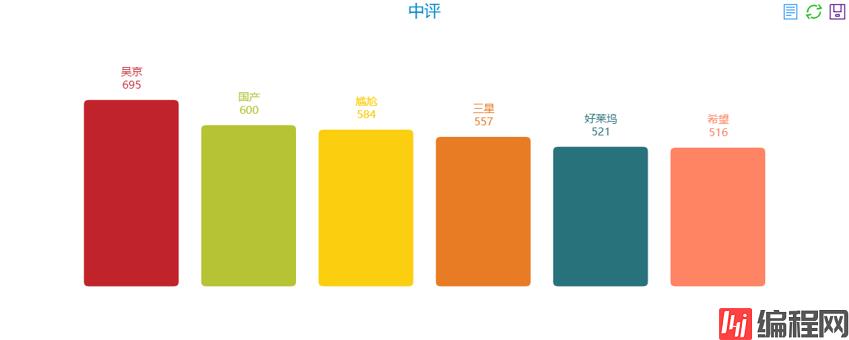
结论:总体来说还算中肯,不知道为啥会出现三星?原谅我没有读过原著,原来是《三体》中"三恒星"系统。
差评:
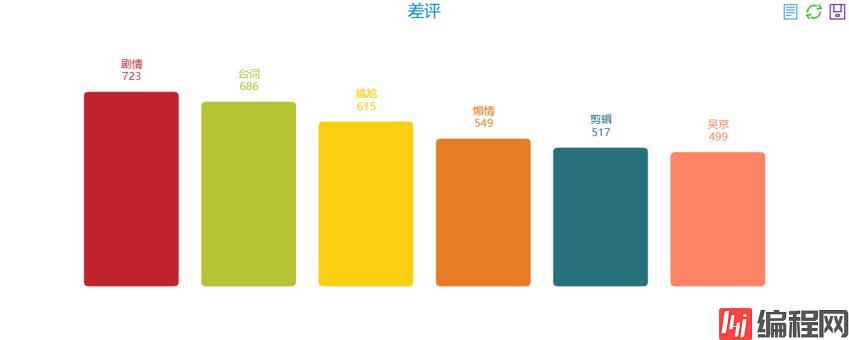
结论:既然是一星差评,肯定是一黑到底,剧情尴尬、台词尴尬、剪辑尴尬、吴京尴尬,相比于好评中高频出现的原著作者刘慈欣,应该有大部分吴京黑粉。
总结
逼乎上有人做了详细的统计分析,同类评分电影中,小破球的一星占比出奇的高。不管是意识形态还是商业利益,《流浪地球》注定要被美分狗和《战狼》PTSD 患者往死里整。《流浪地球》的评价问题已经不仅仅是一部电影的问题。


0