目录正文不使用仓库模式时的代码使用仓库有什么好处?设计仓库接口实现仓库接口选择用哪个仓库实现处理数据源的变更总结正文 在现代 Swift 项目中,很流行一种模式叫做仓库模式,英文是
在现代 Swift 项目中,很流行一种模式叫做仓库模式,英文是 Repository Pattern。这个模式主要用于构建数据层代码。按照一般的 App 层级划分,一般从上到下划分为 UI 层,业务层,数据层,那么仓库模式的应用位置可以参考下图:
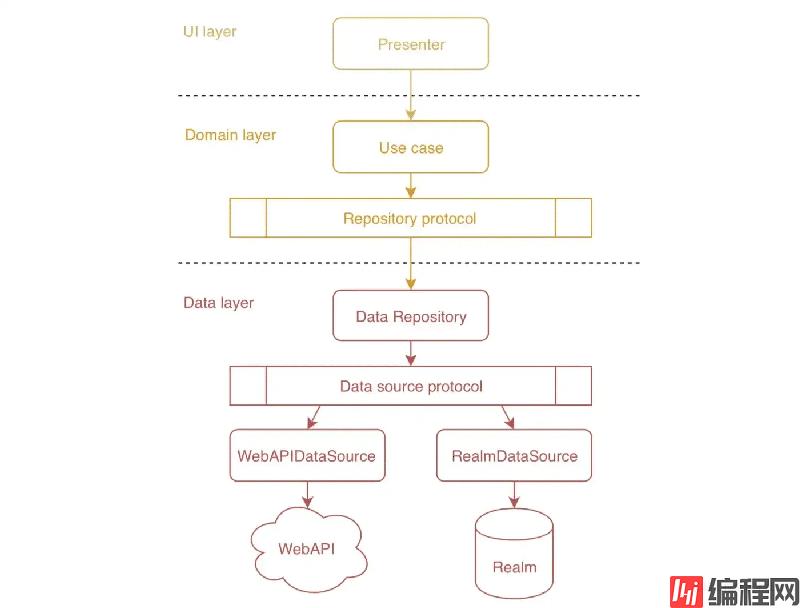
可以看到仓库应用在数据层,业务层通过接口来访问仓库。
为了研究为什么要使用仓库模式,我们先看看不使用仓库模式时我们是怎么写代码的。一般打开一个界面,会发送网络请求来获取这个界面所需的数据,这时会在 ViewController 写类似下面的代码:
func viewDidLoad() {
super.viewDidLoad()
requestData()
}
func requestData() {
api.request(xxxId: 12345) { result in
switch result {
case .success(let model):
handle(model)
DispatchQueue.main.async {
render(model)
}
case .failure(let error):
print(error.localizedString)
}
}
}
这种写法在小项目中是没有问题的,但是在稍具规模的项目中,就会对项目的扩展性,维护性,团队合作,开发效率有比较高的要求,这时候就更应该根据科学的软件设计原则来设计更好的架构。
上面的代码在稍具规模的项目中会有以下的缺点:
稍具规模的项目一般会采用 MVVM 等架构,于是以上的代码会写在 ViewModel 中,来避免 ViewController 太过臃肿,但是还是会有无法测试和修改数据访问方式时改动比较大的问题。
总的来说,就是能提供高层次的抽象,从而获得因为抽象带来的一系列好处。
仓库模式提供了数据层的抽象,可以让你的业务代码只依赖一个简单的抽象接口就可以工作。这使得代码松耦合,业务代码不需要知道数据的具体获取和存储细节。
仓库模式让代码可以测试,对于网络请求和数据库读写的部分,可以实现一个提供测试数据的仓库实例,这样就可以编写相应的测试代码。
下面就来看一看怎样使用仓库模式。
按照依赖倒转原则,数据访问层作为架构中的一个整体,上层对象在调用数据访问层时应该依赖接口,而不依赖于实现,这样数据访问层的逻辑就可以灵活的变更、替换,比如在网络请求和本地数据之间切换,在不同的网络请求协议之间切换等。
所以设计仓库模式应该先定义接口,定义接口有两种方式,一种是根据具体的数据定义特定的仓库接口,例如对于一个新闻列表的接口:
protocol NewsListRepository {
func readNewsList() async throws -> [News]
}
或者是根据不同的业务数据的访问逻辑其实大同小异,可以设计统一的泛型接口:
protocol Repository {
associatedtype T
func query(with predicate: NSPredicate?, sortDescriptors: [NSSortDescriptor]?) async throws -> [T]
func save(entity: T) async throws
func delete(entity: T) async throws
}
我们一般会根据数据的存放方式来定义不同的仓库实现,比如对于网络请求的数据,定义一种仓库的实现,对于本地数据库中存放的数据定义一种仓库的实现,也可以定义一种假数据仓库来编写测试代码。
比如对于网络请求的数据,可以定义一个如下的仓库实现:
class DefaultNewsListRepository: NewsListRepository {
let remoteDataSource: NewsListRemoteAPI
init(remoteDataSource: NewsListRemoteDataSource) {
self.remoteDataSource = remoteDataSource
}
func readNewsList() async throws -> [News] {
return remoteDataSource.requestNewsList();
}
}
对于本地数据,可以设计一个如下的仓库实现:
class DatabaseNewsListRepository: NewsListRepository {
let newsListDataStore: NewsListDataStore
init(newsListRemoteAPI: NewsListRemoteAPI) {
self.newsListRemoteAPI = newsListRemoteAPI
}
func readNewsList() async throws -> [News] {
return newsListRemoteAPI.requestNewsList();
}
}
为了编写测试代码,可以提供一个假数据的仓库实现:
class FakeNewsListRepository: NewsListRepository {
func readNewsList() async throws -> [News] {
return [
News(),
News(),
News()
]
}
}
如果需要从接口请求到数据后放入本地数据库缓存,然后从本地数据库中读取数据渲染在界面上,也可以用一个仓库搞定。
class DefaultNewsListRepository: NewsListRepository {
let newsListRemoteAPI: NewsListRemoteAPI
let newsListDataStore: NewsListDataStore
init(newsListRemoteAPI: NewsListRemoteAPI, newsListDataStore: NewsListDataStore) {
self.newsListRemoteAPI = newsListRemoteAPI
self.newsListDataStore = newsListDataStore
}
func readNewsList() async throws -> [News] {
var newsList = newsListDataStore.readNewsList()
if newsList.count == 0 {
let news = newsListRemoteAPI.requestNewsList()
newsListDataStore.save(newsList)
newsList = news
}
return newsList
}
}
在现代 App 项目中,一般会用 MVVM 等架构来组织代码。这里以 MVVM 为例,ViewModel 会依赖仓库接口来存取数据。
class NewsListViewModel: ViewModel {
let newsListRepository: NewsListRepository
init(newsListRepository: NewsListRepositoy) {
self.newsListRepository = newsListRepository
}
}
为了提高代码的维护性和扩展性,最好使用依赖注入的方式来给 ViewModel 注入 Repository 的依赖,这样可以方便得替换仓库的实现而不用修改 ViewModel 的代码。
可以在创建 ViewModel 时创建对应的仓库对象,也可以使用依赖注入容器。
init(newsListRepository: NewsListRepository = DIContainer.shared.resolve(NewsListRepository.self)) {
self.newsListRepository = newsListRepository
}
当遇到需要变更数据源的时候,例如本地数据库从 CoreData 切换到 sqlite 或 Realm。或者更换了网络库,从 NSURLSession 换成 Alamofire,这些情况仓库模式就能发挥它的优势。无需修改业务方代码,只需要替换成一种新的仓库实现即可。
还有另一种情况,就是对于同一个业务,后端协议变更了。如果使用了仓库模式,也可以很方便的进行代码调整。
通常,业务层会有一个业务模型,比如对于用户的信息,在业务层定义了一套模型:
struct DomainUser {
let name: String
let age: Int
let nickname: String
}
{
"name": "zhangsan",
"age": 20,
"nickname": "xiaozhang"
}
可以直接通过解析 jsON 然后构造出 DomainUser 对象,但是突然某一天后端说要技术调整,迁移到新的接口,新接口返回的结构和以前不一样了。
如果没有用仓库模式,业务方直接依赖具体的数据模型,如果接口结构调整了,那么所有的业务调用方的代码都要调整。
使用了仓库模式,业务方依赖于仓库,仓库可以在获取到数据结构后将它转为业务方需要的数据模型,这样无论后端协议怎么变更,都可以仅在数据层增加一种新的仓库实现,不需要改动业务方代码。这遵守了开放-封闭程序设计原则。
在稍具规模的项目中使用仓库模式,可以让代码抽象度更高,耦合度更低,方便扩展和维护,可以编写测试代码,在大型项目中,可以方便的实现数据源和数据结构的切换。仓库模式也将数据存储的细节和程序的其它部分分离开,使得职责更清晰。
仓库模式也有一些缺点:为了实现这一模式需要编写更多的代码,增加了代码复杂性。需要编写映射代码来讲数据映射为业务模型。如果是小型的项目就不需要使用仓库模式了。
参考资料
以上就是仓库模式及其在Swift 项目中的应用详解的详细内容,更多关于Swift 项目仓库模式的资料请关注编程网其它相关文章!
--结束END--
本文标题: 仓库模式及其在Swift项目中的应用详解
本文链接: https://lsjlt.com/news/178509.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0