目录1、#define的深度认识1.1 数值宏常量1.2 字符串宏常量1.3 用宏充当注释符号1.4 用宏替换多条语句1.5 宏定义的使用建议2、#undef 撤销宏2.1 宏的定义
宏定义数值常量相信大家都不陌生,相信很多小伙伴用过,这里我们就简单的提一下,我们前面也讲过,#define 本质上是替换,它可以出现在代码的任何地方,也可以把任何东西都定义成宏,编译器会在预编译的时候进行替换掉,举例:
#dfeine PI 3.1415926
这样在以后的代码中你就可以用 PI 来代替 3.1415926 那么这样做的好处是什么呢?假设在未来的某一天,你要提升这个精度,如果你代码中出现 3.1415926 过多的话,你提升精度还得一个个修改, 如果使用宏定义的话,你只需要改一次即可。
除了宏定义常量之外,还经常用来定义字符串,特别是路径:
① #define PATH_1 D:\code\lesson1\test
②#define PATH_1 "D:\code\lesson1\test"
以上哪个是正确的呢?如果觉得太长还可以用续行符:
③ #define PATH_1 "D:\code\lesson1\\test"
很显然第一个肯定是不对的,字符串需要用 "" 引起来,第三个也不对,第二个呢?我们去实践证明下(以上写法都不推荐!):
在linux平台环境下:

在windows环境下:
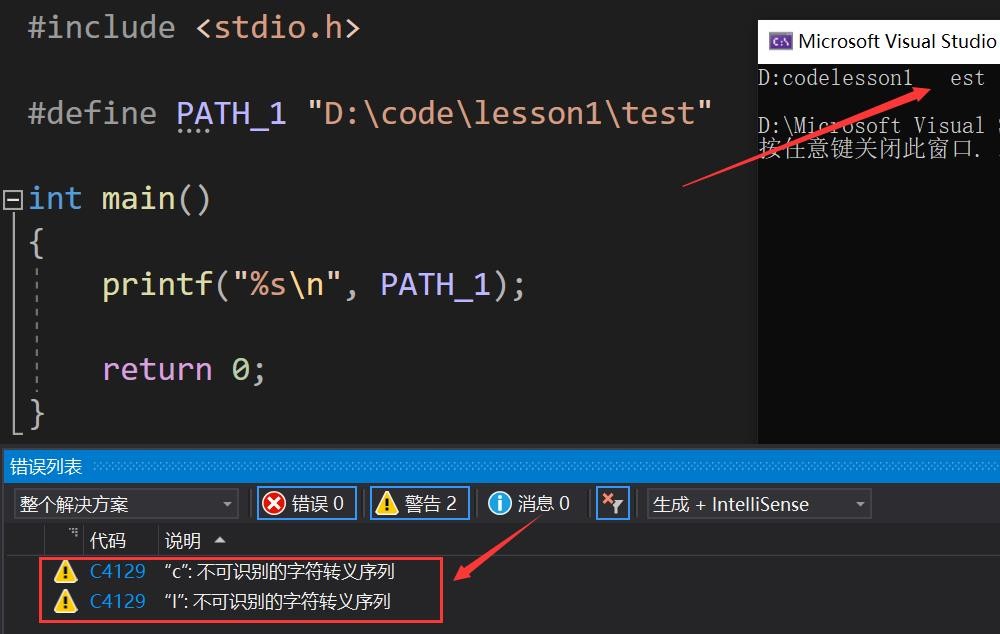
很显然他们都有同样的警告,都是未知转义序列,也无法正确打印出我们的路径,在前面我们讲到,' \ ' 是转义字符,当我们要打印路径的时候需要用转义字符 ' \ ' 去还原 ' \ ' 的字面意思,所以这里打印路径要用 \\ !
注意:Windows路径分隔是用 ' \ ',而Linux路径分隔是用 ' / ',所以如上测试用例改成 ' / ' 的话是不会报警告的。
所以要正确的打印如上用例应该这样写:
//不使用续行符
#define PATH_1 "D:\\code\\lesson1\\test"
//使用续行符
#define PATH_1 "D:\\code\\lesson1\\\test"因为 Linux 环境能直接查看预处理过程,便于我们验证,所以我们下边会在 Linux 环境下测试。
我们先简单了解下程序的翻译过程:
这里我们来看一段用宏充当注释符号的代码:
#include <stdio.h>
#define BSC //
int main()
{
BSC printf("hello world\n");
printf("you can see me!\n");
return 0;
}这里我们要探讨一个什么问题呢?如果替换成功,则不会执行第一个函数,如果替换失败,则我们会看到两行打印:

这究竟是为什么呢?我们可以执行:
[lwp@localhost code]$ GCc -E test.c -o test.i
把预处理后的结果保留下来为 test.i 文件,接着我们可以去用 vim 编辑器查看一下它与源文件的区别在哪,究竟是如何替换的:

通过上图我们可以发现,在预处理之后的文件中,并没有去成功通过宏替换注释掉第一个 printf 函数,由此可见,在预处理阶段,是先执行去掉注释,然后在进行宏替换,如上代码,本质是直接定义了一个空宏,我们特别不推荐这样写代码!(C语言注释风格也一样不行,感兴趣可以下去尝试下)
先看一段代码:
#include <stdio.h>
#define INIT_VALUE(a, b) a = 0; b = 0;
int main()
{
int flag = 0;
scanf("%d", &flag);
int a = 100;
int b = 200;
if (flag)
INIT_VALUE(a, b);
else
printf("%d, %d\n", a, b);
return 0;
}我想请问,这段代码有问题吗?应该如何改进呢?这段代码明显是编译不会通过的,但是可以通过执行预处理指令,发现预处理并没有出问题,那么,我们可以看一下预处理之后的结果与源文件的区别在哪:
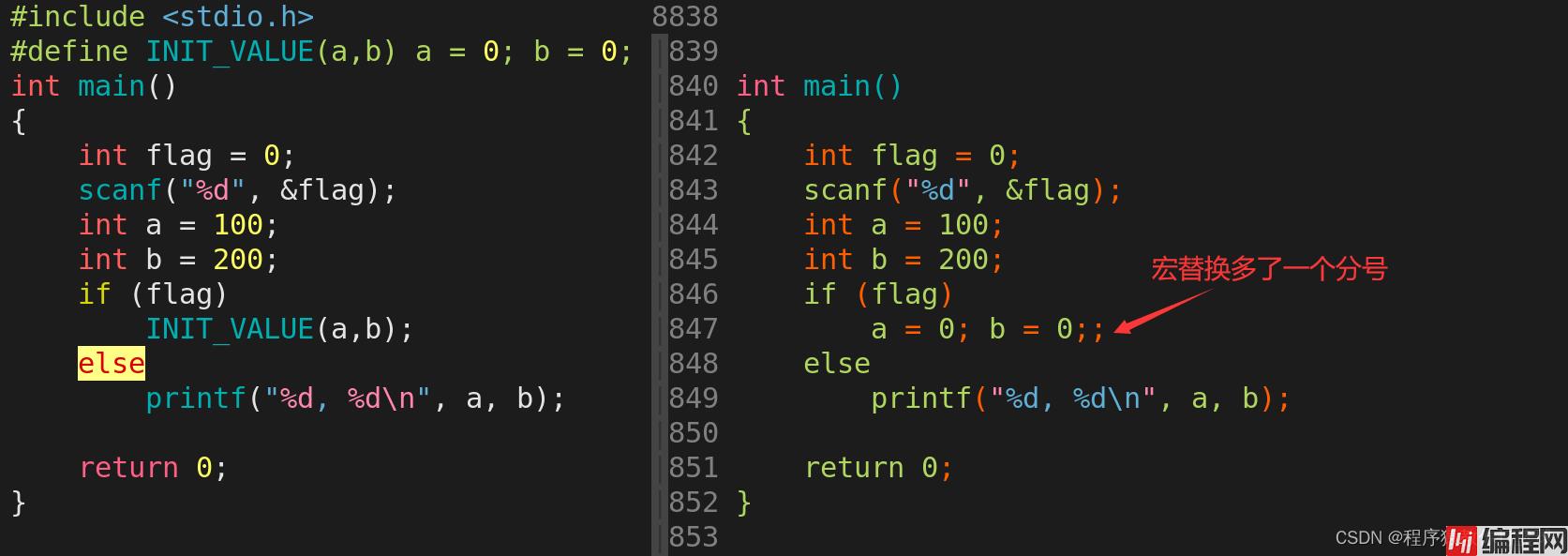
通过预处理之后的结果我们可以看到,宏替换多了一个分号。于是有小伙伴就讨论出来如下三种解决方法:
第一种解决方法肯定是不行的,去掉最后一个分号并不能解决问题,if else 在没有大括号的情况下后面只能跟一条语句,所以第一条行不通。
第二种解决方案看似不错,但是我们有没有想过,并不是所有人都会有良好的代码风格,我们作为程序员,写出的宏应该具有健壮性,所以第二条不可取。
第三种解决方案我们看着好像靠谱,但是我们通常写完一条语句中后面都会带上分号,那可想而知会出现这种情况:{a = 0, b = 0;}; 大括号外是不能跟分号的,所以这个方法也不可取!
最好的解决方法是什么呢?使用 do while 结构:
#include <stdio.h>#define INIT_VALUE(a, b) do{a = 0; b = 0;}while(0)int main(){ int flag = 0; scanf("%d", &flag); int a = 100; int b = 200; if (flag) INIT_VALUE(a, b); else printf("%d, %d\n", a, b); return 0;}#include <stdio.h>
#define INIT_VALUE(a, b) do{a = 0; b = 0;}while(0)
int main()
{
int flag = 0;
scanf("%d", &flag);
int a = 100;
int b = 200;
if (flag)
INIT_VALUE(a, b);
else
printf("%d, %d\n", a, b);
return 0;
}循环会被看成一条复合语句,所以 if 不带大括号也没事(建议带上),这样我们的宏就会更健壮,也不会出错,同时你也可以在中间添加续行符,让他们的格式更清晰!同时我也有个小建议,宏定义的结尾最好都不要带分号。
结论: 当我们需要宏进行多条语句替换的时候,推荐使用 do-while-zero结构。
【建议1】在宏定义体的结尾省略分号。
【建议2】函数宏的调用不能省略参数。
【建议3】函数宏的定义中,每个参数都应该以小括号括起来,避免替换之后出现优先级的问题。
第一个问题,宏定义的位置有限制要求吗?
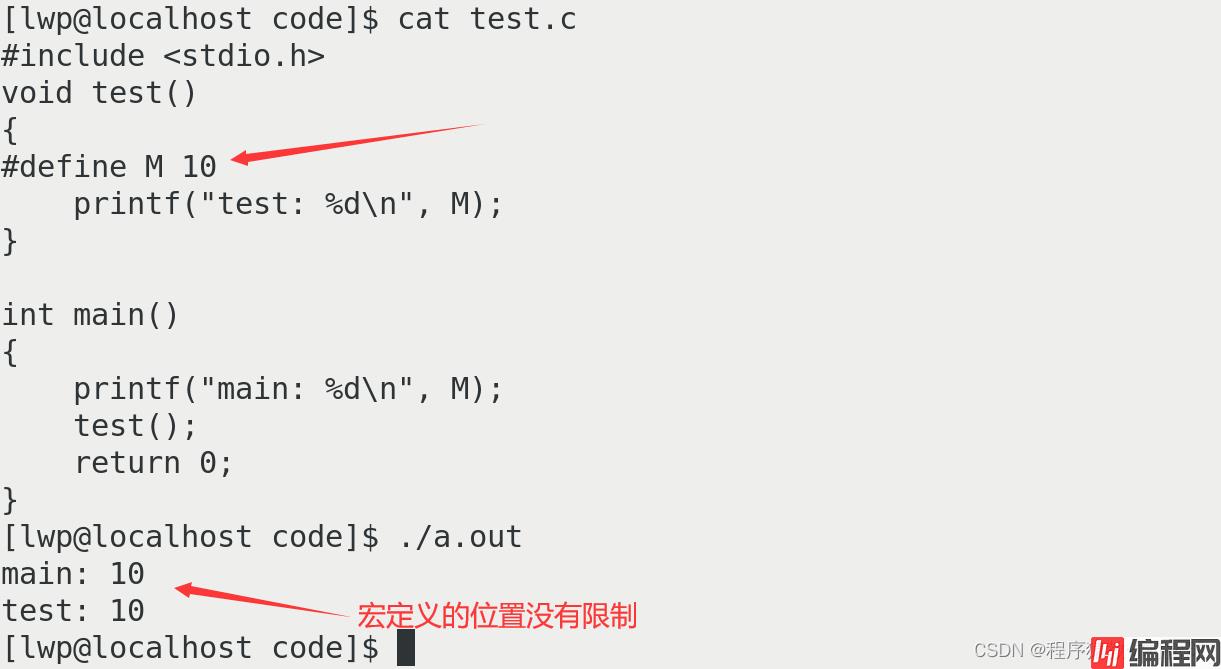
答案:源文件的任何地方,宏都可以定义,与是否在函数内外无关。
第二个问题,宏的有效范围有多大呢?
#include <stdio.h>
void test()
{
printf("test: %d\n", M);
}
int main()
{
test();
#define M 10
printf("main: %d\n", M);
return 0;
}这段代码我们就发现编译不通过了,那么我们来进入预处理文件来对比下源文件:

答案:宏的作用范围,从定义处开始,往后都是有效的!
这里我们用一个例子就能很好的证明了:
#include <stdio.h>
#define M 10
int main()
{
printf("%d\n", M);
#undef M
printf("undef: %d\n", M);
return 0;
} 我们来查看如上代码的预处理之后的结果:

结论:undef 是取消宏的意思,可以用来限定宏的有效范围!
#include <stdio.h>
int main()
{
#define X 3
#define Y X*2
#undef X
#define X 2
int z = Y;
printf("%d\n", z);
return 0;
}请问小伙伴们,这段代码打印什么?
这里我就不截图给大家看了,感兴趣的可以自行下去敲一敲,经过Linux平台和windows平台的测试,最终打印的都是 4,因为编译器都是从上到下扫描代码的,以最近的宏定义为准。
到此这篇关于C语言零基础彻底掌握预处理上篇的文章就介绍到这了,更多相关C语言预处理内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: C语言零基础彻底掌握预处理上篇
本文链接: https://lsjlt.com/news/172179.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0