目录哈希概念冲突闭散列线性探测哈希表闭散列的模拟实现模拟实现的闭散列中的问题与改进哈希 概念 可以不经过任何比较,直接从表中得到要搜索的元素。 关键在于通过某种函数,使元素的存储位置
可以不经过任何比较,直接从表中得到要搜索的元素。 关键在于通过某种函数,使元素的存储位置与它的关键码之间能够建立 一一映射的关系。这样就可以通过o(1)的时间复杂度来寻找到元素。
例如数据集合{1,7,4,5,9,6},哈希函数hash(key)=key&capacity
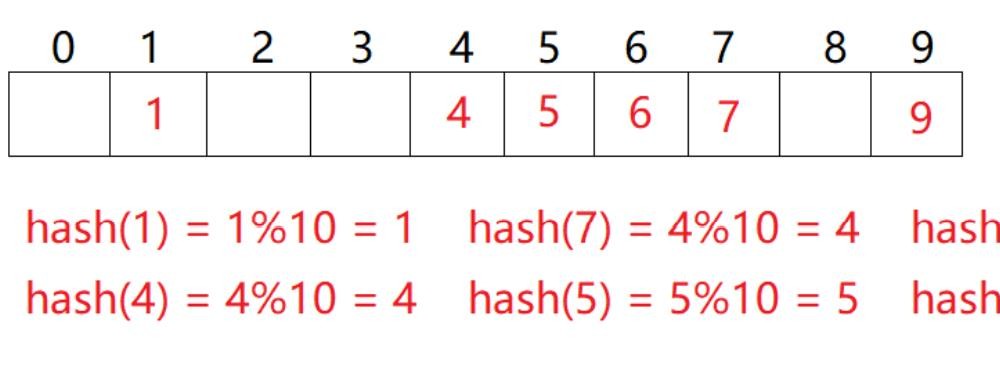
hash(7)=7 hash(17)=7,两个不同的数通过哈希函数映射到了一个位置,产生了冲突。哈希函数设计的越精妙,产生冲突的可能性就越低,但无法避免。
解决方法:
闭散列,(开放定址法)发生冲突时,如果哈希表没有被填满,则表内一定还有其他空闲位置,可以把冲突值放到下一个没有被占用的空余位置上。
如何找到下一个没有被占用的空位?答:采用线性探测方法。从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止。
线性探测的插入
如:在上述的哈希表中插入元素44,由于下标为4的位置放入了元素4,于是从该位置往后++,找到第一个不为空的位置,将44放入。

线性探测的删除
在寻找要删除的元素时,依然会根据存放在哈希表的下标开始寻找,比如在上述哈希表中寻找4,在4下标位置直接就可以找到该元素。但如果直接将其删除,那后续寻找元素44时,就会因为4下标没有元素,而认为元素44不存在于这张哈希表。所以我们需要设置一个状态来表示删除。
我们写在一个自定义类域 Closehash 里面
准备工作
哈希表中元素状态
namespace Closehash
{
//哈希表中元素的状态
enum State
{
EMPTY,
EXIT,
DELETE
};
}
存储类型用pair即可,但是数据中要包含状态,我们进行一次封装
//由于数据需要一个状态,所以需要将pair<K,V>封装一层
template<class K,class V>
struct HashDate
{
pair<K, V>_kv;
State _state;
};
开始(画饼)构建哈希表的内容
template<class K,class V>
class HashTable
{
public:
bool Insert(const pair<K,V>& kv);
HashDate<K, V>* find(const K& key);
bool Erase(const K& key);
private:
vector<HashDate<K,V>> _tables;
size_t _size = 0;
};
闭散列的插入
bool Insert(const pair<K, V>& kv)
{
//if (Find(kv.first)) return false;
//Find实现了再去掉注释
if (_tables.size() == 0
|| 10 * _size / _tables.size() >= 7)//相当于存了70%
{
//开始扩容
size_t newsize = _tables.size()== 0 ? 10 : _tables.size() * 2;
HashTable<K, V> newHash;
newHash._tables.resize(newsize);
for (auto e: _tables)//注意_tables是HashDate类型 里面有_kv 和_state
{
if (e._state == EXIST)
{
newHash.Insert(e._kv);
}
}
//资本家拷贝方法
_tables.swap(newHash._tables);
}
//走到这里扩容完成 或者空间足够大
size_t hashi = kv.first % _tables.size();//寻找在表中对应的下标是什么
while (_tables[hashi]._state==EXIST)
{
hashi++;
//走到头了得回来
hashi%=_tables.size();
}
_tables[hashi]._kv = kv;
_tables[hashi]._state = EXIST;
_size++;
return true;
}测试用例
void TestHT1()
{
int a[] = { 1, 11, 4, 15, 26, 7, 44 };
HashTable<int, int> ht;
for (auto e : a)
{
ht.Insert(make_pair(e, e));
}
ht.Print();
}
添加个99以验证扩容功能

闭散列的查找
HashDate<K, V>* Find(const K& key)
{
if (_tables.size() == 0) return nullptr;
size_t hashi = key % _tables.size();
while (_tables[hashi]._state != EMPTY)
{
if (_tables[hashi]._state != DELETE
&& _tables[hashi]._kv.first == key)
{
return &_tables[hashi];
}
hashi++;
hashi% _tables.size();
}
return nullptr;
}测试用例
cout << ht.Find(4)->_kv.first << endl;
闭散列的删除
bool Erase(const K& key)
{
HashDate<K,V>* ret = Find(key);
if (ret)
{
ret->_state = DELETE;
--_size;
return true;
}
else
{
return false;
}
}
上述测试用例中使用的是pair<int,int>那我要是用pair<string,int>呢?我的key还可以直接对数组长度取模吗?
文档中对这一问题采用了仿函数的解决方法,我们这里也按照该方法模拟一个。
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
// 特化
template<>
struct HashFunc<string>
{
// BKDR
size_t operator()(const string& key)
{
size_t val = 0;
for (auto ch : key)
{
val *= 131;
val += ch;
}
return val;
}
};
template<class K,class V,class Hash=HashFunc<K>>
class HashTable
{
public:
bool Insert(const pair<K,V>& kv);
HashDate<K, V>* find(const K& key);
bool Erase(const K& key);
private:
vector<HashDate<K,V>> _tables;
size_t _size = 0;
};在每次求 在哈希表中位置的前面添加
Hash hash;
size_t hashi = hash(kv.first) % _tables.size()
测试用例
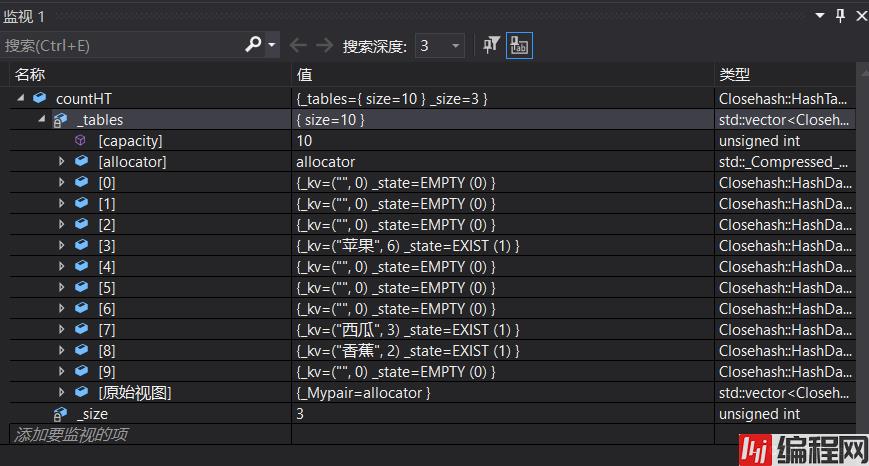
void TestHT2()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
//HashTable<string, int, HashFuncString> countHT;
HashTable<string, int> countHT;
for (auto& str : arr)
{
auto ptr = countHT.Find(str);
if (ptr)
{
ptr->_kv.second++;
}
else
{
countHT.Insert(make_pair(str, 1));
}
}
}
测试用例没加打印...让我来回看了好几遍代码...蠢到无语
到此这篇关于c++哈希表之闭散列方法的模拟实现详解的文章就介绍到这了,更多相关C++哈希表实现闭散列内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: C++哈希表之闭散列方法的模拟实现详解
本文链接: https://lsjlt.com/news/171205.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0