目录表引擎合并树家族MergeTree排序键主键分区数据生命周期其它设置ReplacingMergeTreeSummingMergeTree日志家族其它表引擎 表引擎作用: 数据的存
表引擎作用: 数据的存储方式和位置
支持哪些查询以及如何支持
并发数据访问
索引的使用(如果存在)
是否可以执行多线程请求
数据复制参数
| 常见表引擎 | 家族 | 说明 | 索引 | 备注 |
|---|---|---|---|---|
| TinyLog | Log Family | 以列文件的形式保存在硬盘 数据写入时,追加到文件末尾 | 不支持 | 可用于存储小批量处理的中间数据 |
| Memory | 其它 | 数据以未压缩的原始形式直接保存在内存 | 不支持 | 适用于少量数据的高性能查询 |
| MergeTree | MergeTree Family | 支持 列式存储、分区、稀疏索引、二级索引… | 支持 | 单节点ClickHouse实例的默认表引擎 |
合并树家族特点:
快速插入数据并进行后续的后台数据处理
支持数据复制
支持分区
支持稀疏索引
稀疏索引原理
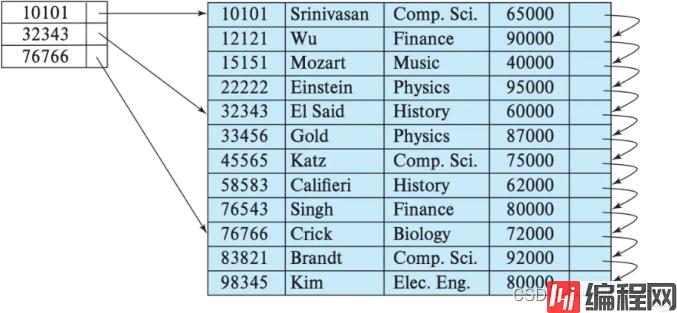
稀疏索引占用空间小,范围批量查询快,但单点查询较慢
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster](
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITioN BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
| 关键词 | 简述 |
|---|---|
| ENGINE | 引擎 |
| ORDER BY | 数据排序规则 |
| PARTITION BY | 分区 |
| PRIMARY KEY | 索引规则 |
| TTL | 数据生命周期 |
| SETTINGS | 其它设置 |
ORDER BY(必选项)
规定了分区内的数据按照哪些字段进行按序存储
如果不需要排序,就用ORDER BY tuple()
此情况下,数据顺序是根据插入顺序
如果想要按INSERT ... SELECT的数据顺序来存储,就设置max_insert_threads=1
若想 按数据存储顺序查出数据,可用 单线程查询
对于有序数据,数据一致性越高,压缩效率越高
PRIMARY KEY(可选项)
作用:为列数据提供稀疏索引(不是唯一约束),提升列查询效率
默认情况下,主键与排序键相同;通常不需要显式PRIMARY KEY子句,除非主键≠排序键
要求:主键列必须是排序列的前缀
例如ORDER BY (a,b)则PRIMARY KEY后可以是(a,b)或(a)
sparse index

PARTITION BY分区(可选项)
分区作用:缩小扫描范围,优化查询速度
并行:分区后,面对涉及跨分区的查询统计,会以分区为单位并行处理
如果不填:只会使用一个分区
数据写入与分区合并:
任何一个批次的数据写入 都会产生一个临时分区,不会纳入任何一个已有的分区。
写入后,过一段时间(约10多分钟),会自动执行合并操作,把临时分区的数据合并
可用OPTIMIZE TABLE 表名 [FINAL]主动执行合并
通常不需要使用分区键。使用时,不建议使用比月更细粒度的分区键
分区过多=>(列式)查询时扫描文件过多=>性能低
-- 建表
DROP TABLE IF EXISTS t1;
CREATE TABLE t1(
uid UInt32,
sku_id String,
total_amount Decimal(9,2),
create_time Datetime
) ENGINE = MergeTree()
PARTITION BY toYYYYMMDD(create_time)
PRIMARY KEY (uid)
ORDER BY (uid,sku_id);
-- 插数据2次
INSERT INTO t1 VALUES
(1,'sku1',1.00,'2020-06-01 12:00:00'),
(2,'sku1',9.00,'2020-06-02 13:00:00'),
(3,'sku2',6.00,'2020-06-02 12:00:00');
INSERT INTO t1 VALUES
(1,'sku1',1.00,'2020-06-01 12:00:00'),
(2,'sku1',9.00,'2020-06-02 13:00:00'),
(3,'sku2',6.00,'2020-06-02 12:00:00');
-- 插完后立即插,会发现数据写入临时分区,还未进行自动合并
SELECT * FROM t1;
┌─uid─┬─sku_id─┬─total_amount─┬─────────create_time─┐
│ 1 │ sku1 │ 1.00 │ 2020-06-01 12:00:00 │
└─────┴────────┴──────────────┴─────────────────────┘
┌─uid─┬─sku_id─┬─total_amount─┬─────────create_time─┐
│ 1 │ sku1 │ 1.00 │ 2020-06-01 12:00:00 │
└─────┴────────┴──────────────┴─────────────────────┘
┌─uid─┬─sku_id─┬─total_amount─┬─────────create_time─┐
│ 2 │ sku1 │ 9.00 │ 2020-06-02 13:00:00 │
│ 3 │ sku2 │ 6.00 │ 2020-06-02 12:00:00 │
└─────┴────────┴──────────────┴─────────────────────┘
┌─uid─┬─sku_id─┬─total_amount─┬─────────create_time─┐
│ 2 │ sku1 │ 9.00 │ 2020-06-02 13:00:00 │
│ 3 │ sku2 │ 6.00 │ 2020-06-02 12:00:00 │
└─────┴────────┴──────────────┴─────────────────────┘
-- 手动合并分区
OPTIMIZE TABLE t1 FINAL;
-- 再次查询,会看到分区已经合并
SELECT * FROM t1;
┌─uid─┬─sku_id─┬─total_amount─┬─────────create_time─┐
│ 1 │ sku1 │ 1.00 │ 2020-06-01 12:00:00 │
│ 1 │ sku1 │ 1.00 │ 2020-06-01 12:00:00 │
└─────┴────────┴──────────────┴─────────────────────┘
┌─uid─┬─sku_id─┬─total_amount─┬─────────create_time─┐
│ 2 │ sku1 │ 9.00 │ 2020-06-02 13:00:00 │
│ 2 │ sku1 │ 9.00 │ 2020-06-02 13:00:00 │
│ 3 │ sku2 │ 6.00 │ 2020-06-02 12:00:00 │
│ 3 │ sku2 │ 6.00 │ 2020-06-02 12:00:00 │
└─────┴────────┴──────────────┴─────────────────────┘TTL:Time To Live
列TTL
当列中的值过期时,ClickHouse将用列数据类型的默认值替换它们
TTL子句不能用于键列
表TTL
当数据部分中的所有列值都过期,可以删除数据
DROP TABLE IF EXISTS t1;
CREATE TABLE t1 (
d DateTime,
-- 列生命周期(5秒)
a Int TTL d + INTERVAL 5 SECOND
)ENGINE = MergeTree()
ORDER BY d
-- 表生命周期(1分钟)
TTL d + INTERVAL 1 MINUTE DELETE;
-- 插数据
INSERT INTO t1 VALUES (now(),2);
-- 立即查
SELECT * FROM t1;
┌───────────────────d─┬─a─┐
│ 2022-11-01 14:39:17 │ 2 │
└─────────────────────┴───┘
-- 5秒后刷新并查询
OPTIMIZE TABLE t1 FINAL;
SELECT * FROM t1;
┌───────────────────d─┬─a─┐
│ 2022-11-01 14:39:17 │ 0 │
└─────────────────────┴───┘
-- 1分钟后查
OPTIMIZE TABLE t1 FINAL;
SELECT * FROM t1;
-- 过期数据行被删除立即查,TTL列值为2,5秒后查值为0,1分钟后查此数据被删除
| 常见设置 | 说明 | 默认值 | 备注 |
|---|---|---|---|
| index_granularity | 索引粒度。索引中相邻的『标记』间的数据行数 | 8192 | 通常不用改 |
| index_granularity_bytes | 索引粒度,以字节为单位 | 10Mb | 数据量很大 且 数据一致性很高 时 可考虑 调大索引粒度 |
| min_index_granularity_bytes | 允许的最小数据粒度 | 1024b | 用于防止 添加索引粒度很低的表 |
ReplacingMergeTree具有去重功能:分区内按排序键去重
数据的去重只会在数据合并期间进行
合并会在后台一个不确定的时间进行
可用OPTIMIZE语句发起计划外的合并,但会引发数据的大量读写
ReplacingMergeTree适用于在后台清除重复的数据,但是不保证没有重复数据出现
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
ver是版本列,是可选参数,类型可为UInt、Date、DateTime在数据合并时,ReplacingMergeTree从相同排序键的行中选择一行留下:
如果ver列未指定,就保留最后一条
如果ver列已指定,就保留ver值最大的版本
DROP TABLE IF EXISTS t1;
CREATE TABLE t1(
uid UInt32,
sku_id String,
create_time Datetime
) ENGINE = ReplacingMergeTree(create_time)
PARTITION BY sku_id
ORDER BY (uid);
INSERT INTO t1 VALUES
(1,'s1','2022-06-01 00:00:00'),
(1,'s1','2022-06-02 11:11:11'),
(1,'s2','2022-06-02 13:00:00'),
(2,'s2','2022-06-02 12:12:12'),
(2,'s2','2022-06-02 00:00:00');
SELECT * FROM t1;
-- 插了5条数据,去重了,查出来只有3条,不同分区没有去重
┌─uid─┬─sku_id─┬─────────create_time─┐
│ 1 │ s1 │ 2022-06-02 11:11:11 │
└─────┴────────┴─────────────────────┘
┌─uid─┬─sku_id─┬─────────create_time─┐
│ 1 │ s2 │ 2022-06-02 13:00:00 │
│ 2 │ s2 │ 2022-06-02 12:12:12 │
└─────┴────────┴─────────────────────┘适用场景:不需要查询明细,只查询 按维度聚合求和 的场景
原理:预聚合
优点:加快聚合求和查询、节省空间
语法:SummingMergeTree([columns])
columns是可选参数,必须是数值类型,并且不可位于主键中
所选列将会被预聚合求和;若缺省,则所有非维度数字列将会被聚合求和
DROP TABLE IF EXISTS t1;
CREATE TABLE t1(
uid UInt32,
amount1 Decimal(9,2),
amount2 Decimal(9,2)
) ENGINE = SummingMergeTree(amount1)
ORDER BY (uid);
INSERT INTO t1 VALUES (1,1.00,2.00),(1,9.00,8.00);
SELECT * FROM t1;
┌─uid─┬─amount1─┬─amount2─┐
│ 1 │ 10.00 │ 2.00 │
└─────┴─────────┴─────────┘
INSERT INTO t1 VALUES (1,1.11,2.22),(2,5.00,5.00);
SELECT * FROM t1;
┌─uid─┬─amount1─┬─amount2─┐
│ 1 │ 10.00 │ 2.00 │
└─────┴─────────┴─────────┘
┌─uid─┬─amount1─┬─amount2─┐
│ 1 │ 1.11 │ 2.22 │
│ 2 │ 5.00 │ 5.00 │
└─────┴─────────┴─────────┘
OPTIMIZE TABLE t1;
SELECT * FROM t1;
┌─uid─┬─amount1─┬─amount2─┐
│ 1 │ 11.11 │ 2.00 │
│ 2 │ 5.00 │ 5.00 │
└─────┴─────────┴─────────┘图示amount1会按照uid聚合求和,而amount2是第一条插入uid时的值
注意
不能直接SELECT amount1 FROM t1 WHERE 维度来得到汇总值,因为有些临时明细数据还没来得及聚合
所以仍要SELECT SUM(amount1)
INSERT期间,表会被锁定ENGINE = Log()内存引擎
ENGINE = Memory()到此这篇关于Mysql ClickHouse常用表引擎超详细讲解的文章就介绍到这了,更多相关mysql ClickHouse内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: MySQLClickHouse常用表引擎超详细讲解
本文链接: https://lsjlt.com/news/170575.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0