Python 官方文档:入门教程 => 点击学习
目录Javaapi过滤(不推荐)1千数据量1万数据量10万数据量100万数据量List集合双层遍历比较不同(不推荐)借助Map集合查找(推荐)1千数据量1万数据量10万数据量100万
本文将带你了解如何快速的找出两个相似度非常高的List集合里的不同元素。主要通过Java API、List集合双层遍历比较不同、借助Map集合查找三种方式,以及他们之间的执行效率情况,话不多说,开搞! 集合初始化方法:
private static List<String> dataList(int size) {
List<String> dataList = new ArrayList<>();
for (int i = 0; i < size; i++) {
dataList.add("" + i);
}
return dataList;
}测试数据为集合A: 1千, 1万, 10万,1百万, 1千万的数据量.
List<String> listA = dataList(1000);
//集合A添加一个集合B没有的元素
listA.add("onlyA10086");
List<String> listB = dataList(1006);
Long startTime = System.currentTimeMillis();
// 复制集合A和集合B作为备份
List<String> listABak = new ArrayList<>(listA);
List<String> listBBak = new ArrayList<>(listB);
// 集合B存在,集合A不存在的元素
listB.removeAll(listA);
// 集合A存在,集合B不存在的元素
listA.removeAll(listBBak);
Long endTime = System.currentTimeMillis();
List<String> differentList = new ArrayList<>();
differentList.addAll(listB);
differentList.addAll(listA);
System.out.println("集合A和集合B不同的元素:"+differentList);
Long costTime = endTime-startTime;
System.out.println("比对耗时:"+costTime+"毫秒。");
耗时:22毫秒

List<String> listA = dataList(10000);
//集合A添加一个集合B没有的元素
listA.add("onlyA10086");
List<String> listB = dataList(10006);
Long startTime = System.currentTimeMillis();
// 复制集合A和集合B作为备份
List<String> listABak = new ArrayList<>(listA);
List<String> listBBak = new ArrayList<>(listB);
// 集合B存在,集合A不存在的元素
listB.removeAll(listA);
// 集合A存在,集合B不存在的元素
listA.removeAll(listBBak);
Long endTime = System.currentTimeMillis();
List<String> differentList = new ArrayList<>();
differentList.addAll(listB);
differentList.addAll(listA);
System.out.println("集合A和集合B不同的元素:"+differentList);
Long costTime = endTime-startTime;
System.out.println("比对耗时:"+costTime+"毫秒。");
耗时:613毫秒

List<String> listA = dataList(100000);
//集合A添加一个集合B没有的元素
listA.add("onlyA10086");
List<String> listB = dataList(100006);
Long startTime = System.currentTimeMillis();
// 复制集合A和集合B作为备份
List<String> listABak = new ArrayList<>(listA);
List<String> listBBak = new ArrayList<>(listB);
// 集合B存在,集合A不存在的元素
listB.removeAll(listA);
// 集合A存在,集合B不存在的元素
listA.removeAll(listBBak);
Long endTime = System.currentTimeMillis();
List<String> differentList = new ArrayList<>();
differentList.addAll(listB);
differentList.addAll(listA);
System.out.println("集合A和集合B不同的元素:"+differentList);
Long costTime = endTime-startTime;
System.out.println("比对耗时:"+costTime+"毫秒。");

可以看出来十万数据量级别已经比较慢了,需要77秒
emmm估计挺慢,不继续验证了。
为什么在数据量增大的时候,这种方法性能下降的这么明显? 我们不妨来看一下removeAll的源码:
public boolean removeAll(Collection<?> c) {
// 先判空,然后执行批量remove
Objects.requireNonNull(c);
return batchRemove(c, false);
}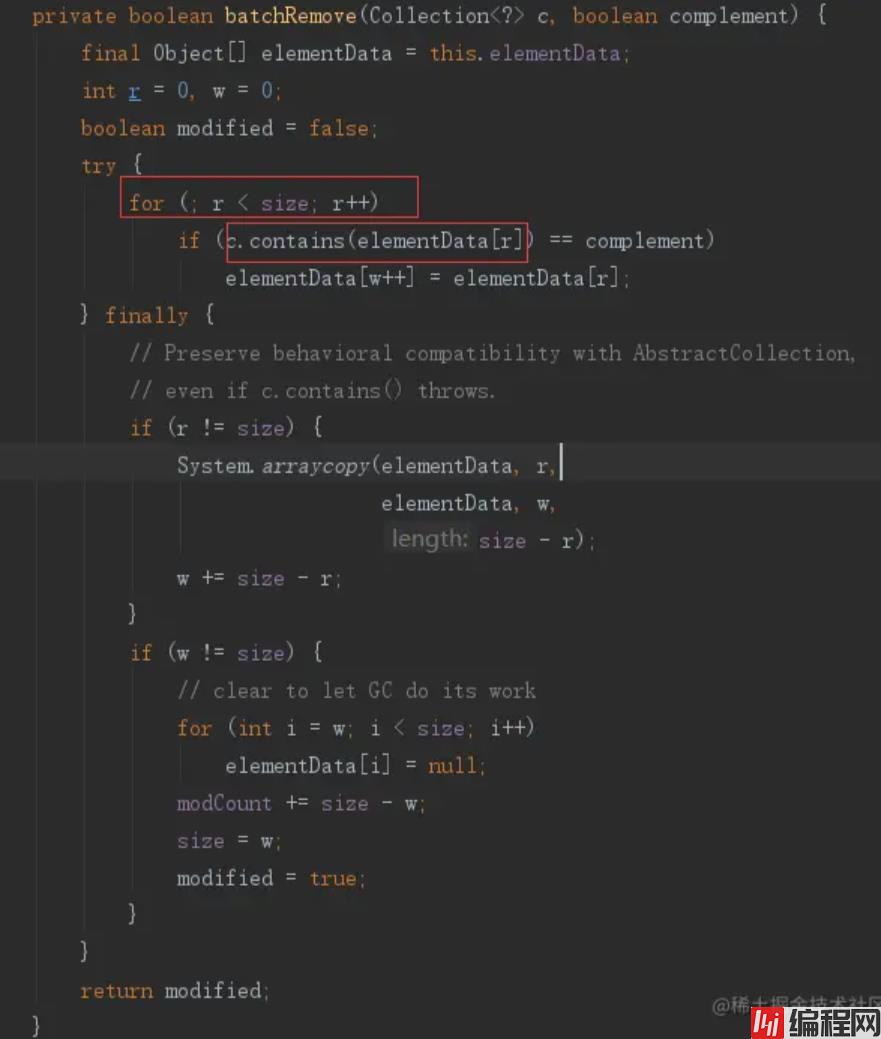
通过源码我们可以看到,该方法是使用for循环对集合进行遍历 第一层循环需要执行 listA.size()次,里面调用了contains方法来确定集合B是否含有该元素, 再看contains方法的源码:
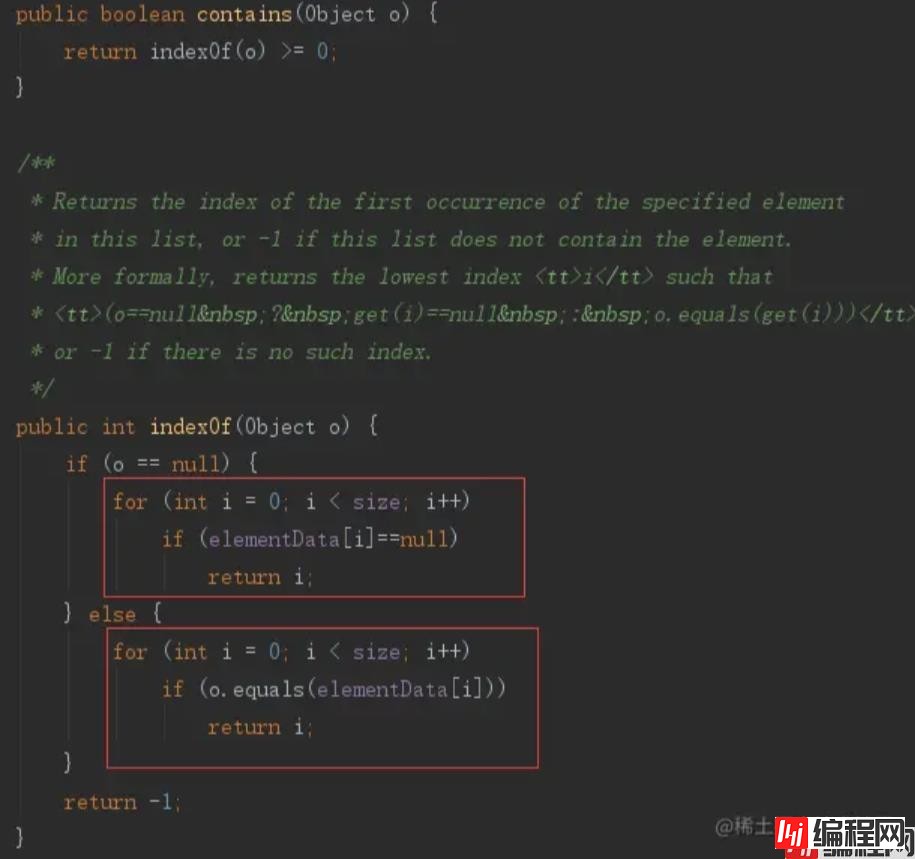
可以看到,indexOf方法里又进行了一层遍历. 平均每次遍历要进行list.size() / 2次计算, 假设集合A的元素个数为m,集合B的元素个数为n 我们可以得到结论,运算次数为 m *(n/2) 对于100W数据量来说,假设你的计算机每秒能够执行1千万次运算,也需要13.8个小时才能对比出来。所以大数据量不建议通过此方法。

该方法实际上就是将removeAll的实现逻辑用自己的方式写出来,所以执行效率,运行结果和上一种方法没什么区别,这里只贴代码出来,不再赘述。
private static void doubleFor() {
List<String> listA = dataList(1000);
//集合A添加一个集合B没有的元素
listA.add("onlyA10086");
List<String> listB = dataList(1006);
System.out.println("数量级为 " + listA.size() + "集合的不同元素为");
List<String> differentList = new ArrayList<>();
long startTime = System.currentTimeMillis();
for (String str : listB) {
if (!listA.contains(str)) {
differentList.add(str);
}
}
for (String str : listA) {
if (!listB.contains(str)) {
differentList.add(str);
}
}
long endTime = System.currentTimeMillis();
System.out.println("集合A和集合B不同的元素:"+differentList);
System.out.println("使用双层遍历方法 比对耗时: " + (endTime - startTime)+"毫秒。");
}以上两个方法中我都做了m*n次循环,其实完全没有必要循环这么多次,我们的需求是找出两个List中的不同元素,那么我可以这样考虑:用一个map存放lsit的所有元素,其中的key为lsit1的各个元素,value为该元素出现的次数,接着把list2的所有元素也放到map里,如果已经存在则value加1,最后我们只要取出map里value为1的元素即可,这样我们只需循环m+n次,大大减少了循环的次数。
以List集合里的元素作为Map的key,元素出现的次数作为Map的Value,那么两个List集合的不同元素在Map集合中value值为1,所对应的键。把所有value值为1的键找出来,我们就得到了两个List集合不同的元素。 代码如下:
public static List<String> getDifferListByMap(List<String> listA, List<String> listB) {
List<String> differList = new ArrayList<>();
Map<String, Integer> map = new HashMap<>();
long beginTime = System.currentTimeMillis();
for (String strA : listA) {
map.put(strA, 1);
}
for (String strB : listB) {
Integer value = map.get(strB);
if (value != null) {
map.put(strB, ++value);
continue;
}
map.put(strB, 1);
}
for (Map.Entry<String, Integer> entry : map.entrySet()) {
//获取不同元素集合
if (entry.getValue() == 1) {
differList.add(entry.geTKEy());
}
}
long endTime = System.currentTimeMillis();
System.out.println("集合A和集合B不同的元素:"+differList);
System.out.println("使用map方式遍历, 对比耗时: " + (endTime - beginTime)+"毫秒。");
return differList;
} List<String> listA = dataList(1000);
//集合A添加一个集合B没有的元素
listA.add("onlyA10086");
List<String> listB = dataList(1006);
getDifferListByMap(listA,listB);
耗时:7毫秒

List<String> listA = dataList(10000);
//集合A添加一个集合B没有的元素
listA.add("onlyA10086");
List<String> listB = dataList(10006);
getDifferListByMap(listA,listB);
耗时:42毫秒

List<String> listA = dataList(100000);
//集合A添加一个集合B没有的元素
listA.add("onlyA10086");
List<String> listB = dataList(100006);
getDifferListByMap(listA,listB);
耗时:130毫秒

List<String> listA = dataList(1000000);
//集合A添加一个集合B没有的元素
listA.add("onlyA10086");
List<String> listB = dataList(1000006);
getDifferListByMap(listA,listB);
耗时:283毫秒

List<String> listA = dataList(10000000);
//集合A添加一个集合B没有的元素
listA.add("onlyA10086");
List<String> listB = dataList(10000006);
getDifferListByMap(listA,listB);
耗时:6.6秒

可以看出来这种方法相当高效,千万级数据比对也才用了6.6秒。 使用map集合的方式寻找不同元素,时间增长基本上是线性的,它的时间复杂度为O(m)。 而上面的remove方式和双层循环遍历的时间复杂度为O(m * n)。 所以,选用这种方式带来的性能收益随着集合元素的增长而增长。
上述通过map集合的方式效率很高,有没有可以优化的点呢?
优化后代码如下:
public static Collection getDifferListByMapPlus(Collection collmax, Collection collmin) {
//使用LinkedList防止差异过大时,元素拷贝
Collection csReturn = new LinkedList();
Collection max = collmax;
Collection min = collmin;
long beginTime = System.currentTimeMillis();
//先比较大小,这样会减少后续map的if判断次数
if (collmax.size() < collmin.size()) {
max = collmin;
min = collmax;
}
//直接指定大小,防止再散列
Map<Object, Integer> map = new HashMap<Object, Integer>(max.size());
for (Object object : max) {
map.put(object, 1);
}
for (Object object : min) {
if (map.get(object) == null) {
csReturn.add(object);
} else {
map.put(object, 2);
}
}
for (Map.Entry<Object, Integer> entry : map.entrySet()) {
if (entry.getValue() == 1) {
csReturn.add(entry.getKey());
}
}
long endTime = System.currentTimeMillis();
System.out.println("集合A和集合B不同的元素:"+csReturn);
System.out.println("使用map方式遍历, 对比耗时: " + (endTime - beginTime)+"毫秒。");
return csReturn;
}同样找出相同元素可以使用如下代码:
public static Collection getSameListByMap(Collection collmax, Collection collmin) {
//使用LinkedList防止差异过大时,元素拷贝
Collection csReturn = new LinkedList();
Collection max = collmax;
Collection min = collmin;
//先比较大小,这样会减少后续map的if判断次数
if (collmax.size() < collmin.size()) {
max = collmin;
min = collmax;
}
//直接指定大小,防止再散列
Map<Object, Integer> map = new HashMap<Object, Integer>(max.size());
for (Object object : max) {
map.put(object, 1);
}
for (Object object : min) {
if (map.get(object) != null) {
csReturn.add(object);
}
}
return csReturn;
}以上就是Java找出两个大数据量List集合中的不同元素的方法总结的详细内容,更多关于Java找出List集合中的不同元素的资料请关注编程网其它相关文章!
--结束END--
本文标题: Java找出两个大数据量List集合中的不同元素的方法总结
本文链接: https://lsjlt.com/news/169973.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0