Python 官方文档:入门教程 => 点击学习
目录前言SpringCloud微服务单体架构和微服务分布式架构单体架构分析微服务分布式架构分析服务拆分和远程调用服务拆分 案例需求准备远程调用初步Eureka注册中心服务注册与负载均
这篇笔记文章我还是没有接上之前的java,因为我中间偷懒了,写不动了。打算先把这篇安排下,然后再把之前的spring和SpringBoot缺失的笔记补一下。至于啥时候补全,我也没有定论。
写博客的真正目的就是做个笔记,以后自己忘记的知识点自己回顾一下。至于其他网站的盗文,我都无所谓了。毕竟网络文章博文这些其实还是没有什么保护的,又不是软件著作权。
一直在看学习视频,一直在b站学习。虽然自己菜啊,但是还是要努力啊!不然在这个社会我怕饿死。
那就从SprinGCloud开始,还没有补充前面的spring和springboot,但是之后一定会补全的。
SpringCloud是一种微服务的框架,利用它我们可以去做分布式服务开发。
至于具体的,我们现在开始介绍。
在这之前我们所有的开发都是按照单体架构开发的。什么是单体架构,其实就是所有的功能都放在一个项目中。然后部署的时候吗,就去打包为整体的一个包进行部署。
像之前黑马的单体架构基于Springboot和mybatisplus实现的瑞吉外卖这样子就是单体架构。

这里面包含一些实体类,基本的配置类,以及一些公共·的数据处理的封装的进行处理的类,还有扩展的实体类,其中主要的比较典型的就是三层架构,==数据访问层,业务逻辑层,表现层,这是mvc三层架构的基本设计理念。非常重要。在我们刚接触到这样的设计模式的时候,已经觉得这样的设计模式已经非常秒了。从小白过渡到设计模式的时候。
加上Springboot这个强大的框架,我们可以简化非常多的操作,而且可以某些操作上做的比较优雅。
我们认为在使用spring后可以极大的降低项目开发中代码的·1耦合度,但是其实这样项目的功能庞大后之间的耦合度还是很高。

当然这样开发部署的话成本肯定是成本低的。
但是单体架构带来的缺点是什么。说几点。
首先一定是在项目整体开发所用的编程语言,一定是只能用一种,整个项目的所有功能的开发只能用一种语言编写。
还有耦合度带来的问题啊,耦合度高的话,系统中只要一个模块出现问题,系统就很容易瘫痪。
还有项目的部署上线,需要功能开发完毕后才可以上线。造成的问题就是可能需要等待,无法及时满足需求。
等等。这些在了解到分布式微服务后就可以了解到如何解决这些问题的。
分布式架构的微服务有很多。



也就是说微服务并不是springcloud这一种。微服务的理念就是实现拆分功能的开发。将具体的功能分离出来。这样带来的好处就是你开发你的功能,我开发我的功能,互不影响。降低了偶尔度。而且在后面我们学到集群这些等等后,就会理解到在优化升级的时候所带来的的好处。比较常用的词就是单一职责。
需要了解一下

这些我们在后面的学习中就会得到理解。
现在我们提出一个简单的需求。我们在一张订单表中通过订单的id 查询到订单的数据还有对应用户的数据。
这样的需求的话,我们需要在订单的表的每个id对应一个用户id,这样我们才能做到表数据关联。
tb_user 建表sql如下
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for tb_user
-- ----------------------------
DROP TABLE IF EXISTS `tb_user`;
CREATE TABLE `tb_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`username` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '收件人',
`address` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '地址',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `username`(`username`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 109 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of tb_user
-- ----------------------------
INSERT INTO `tb_user` VALUES (1, '柳岩', '湖南省衡阳市');
INSERT INTO `tb_user` VALUES (2, '文二狗', '陕西省西安市');
INSERT INTO `tb_user` VALUES (3, '华沉鱼', '湖北省十堰市');
INSERT INTO `tb_user` VALUES (4, '张必沉', '天津市');
INSERT INTO `tb_user` VALUES (5, '郑爽爽', '辽宁省沈阳市大东区');
INSERT INTO `tb_user` VALUES (6, '范兵兵', '山东省青岛市');
SET FOREIGN_KEY_CHECKS = 1;tb_brand 建表sql 如下
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for tb_order
-- ----------------------------
DROP TABLE IF EXISTS `tb_order`;
CREATE TABLE `tb_order` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '订单id',
`user_id` bigint(20) NOT NULL COMMENT '用户id',
`name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL COMMENT '商品名称',
`price` bigint(20) NOT NULL COMMENT '商品价格',
`num` int(10) NULL DEFAULT 0 COMMENT '商品数量',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `username`(`name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 109 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Compact;
-- ----------------------------
-- Records of tb_order
-- ----------------------------
INSERT INTO `tb_order` VALUES (101, 1, 'Apple 苹果 iPhone 12 ', 699900, 1);
INSERT INTO `tb_order` VALUES (102, 2, '雅迪 yadea 新国标电动车', 209900, 1);
INSERT INTO `tb_order` VALUES (103, 3, '骆驼(CAMEL)休闲运动鞋女', 43900, 1);
INSERT INTO `tb_order` VALUES (104, 4, '小米10 双模5G 骁龙865', 359900, 1);
INSERT INTO `tb_order` VALUES (105, 5, 'OPPO Reno3 Pro 双模5G 视频双防抖', 299900, 1);
INSERT INTO `tb_order` VALUES (106, 6, '美的(Midea) 新能效 冷静星II ', 544900, 1);
INSERT INTO `tb_order` VALUES (107, 2, '西昊/SIHOO 人体工学电脑椅子', 79900, 1);
INSERT INTO `tb_order` VALUES (108, 3, '梵班(FAMDBANN)休闲男鞋', 31900, 1);
SET FOREIGN_KEY_CHECKS = 1;从订单表中获取到订单id然后返回订单数据对象,然后获取到user_id,然后将user_id传入对user表的请求路径中,这样我们就可以获取到user的封装数据。这里我们需要再加一个对象属性。

这样我们可以就可以对user数据进行封装,在查询结构中就会有这个对象数据。
这是我们准备的两张表,当然这只是一个简单的例子,我们后面要用这个例子做测试。
我们需要创建项目,项目下分模块来进行设计。因为这是一个人做,我们在一个项目下,分模块来进行分布式的这种操作模拟。
一个父模块,两个子模块
先看父模块的pom,不过在这之前我们特别注意看一下这里。

我们idea这里的Maven配置。不过我每次都得改。
一定要改到自己的maven配置里面


从这里看项目初步是OK的。
这是父maven的pom
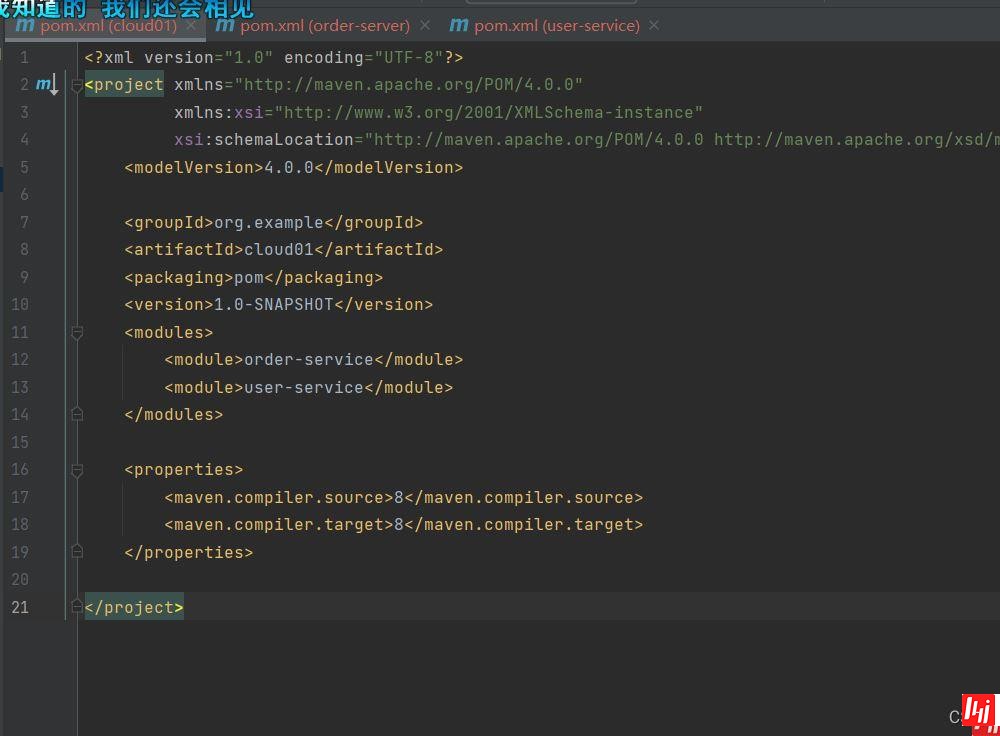

现在我们添加必要依赖,首先将这个项目变成一个springboot项目

这就是Spring Boot的父级依赖,加入之后项目就变成了Spring Boot项目。spring-boot-starter-parent是一个特殊的starter,它用来提供相关的maven默认依赖。之后再引入。其他的依赖时,可以不用指定version标签。
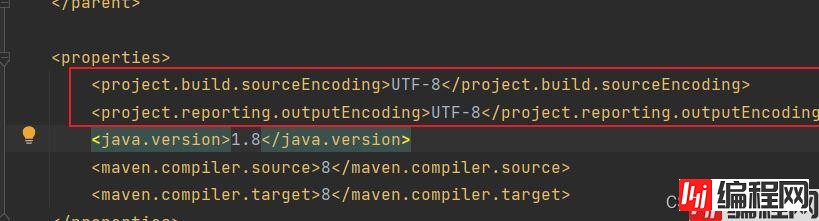
我们可以给项目maven指定jdk版本和编码,一定要注意加的位置。
还有我们做的是一个springCloud微服务啊,我们需要准备这个环境
这里特别注意springboot和springcloud的版本兼容性,否则无法运行。

需要对应到版本。所以springCloud导入这个依赖。
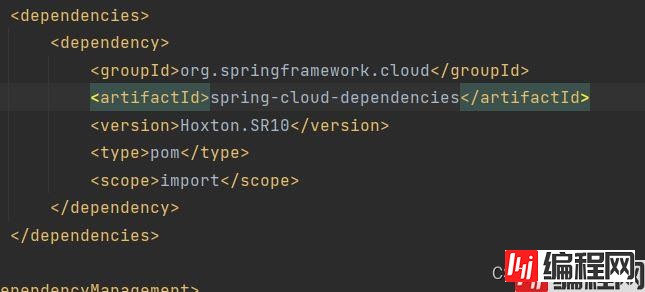
我们可以放到这个标签下
复习一下它有什么用处
Maven 可以通过 dependencyManagement 元素对依赖进行管理,它具有以下 2 大特性:
在该元素下声明的依赖不会实际引入到模块中,只有在 dependencies 元素下同样声明了该依赖,才会引入到模块中。
该元素能够约束 dependencies 下依赖的使用,即 dependencies 声明的依赖若未指定版本,则使用 dependencyManagement 中指定的版本,否则将覆盖 dependencyManagement 中的版本。
我们看到,这里多了一个import,它的意思是将spring-boot-dependencies 中dependencyManagement的dependencies,全部引入到当前工程的dependencyManagement中
另外还有Mysql的连接驱动,mybatis整合springboot框架分别导入进来。
还有一个我们用到的工具
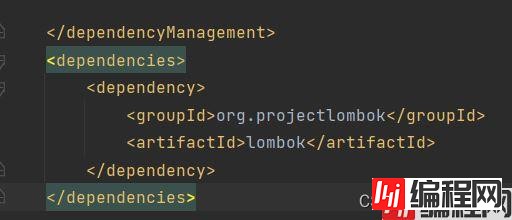
lombok插件是为了方便实体类bean快速生成get set方法,从而不用手动添加
为什么我们要这样分开写,复习一下
dependencies即使在子项目中不写该依赖项,那么子项目仍然会从父项目中继承该依赖项(全部继承)而我们的DepencyManagement是子工程依赖模块可选择的。
至此父级maven工程依赖如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="Http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>cloud01</artifactId>
<packaging>pom</packaging>
<version>1.0-SNAPSHOT</version>
<modules>
<module>order-service</module>
<module>user-service</module>
</modules>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.9.RELEASE</version>
<relativePath/>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR10</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
</project>
来看子级别pom

现在我们导入必要依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>cloud01</artifactId>
<groupId>org.example</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>order-server</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-WEB</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
</dependencies>
</project>
还有一个打包插件我们暂且可以不用
两个子工程都需要这样导入
现在我们创建三成架构的目录和类
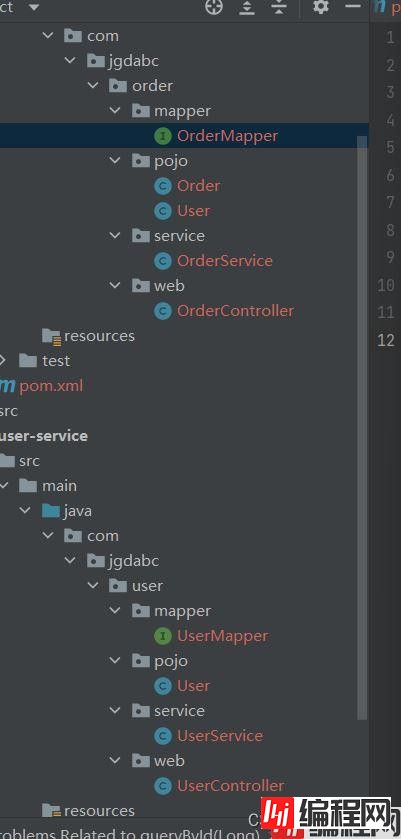
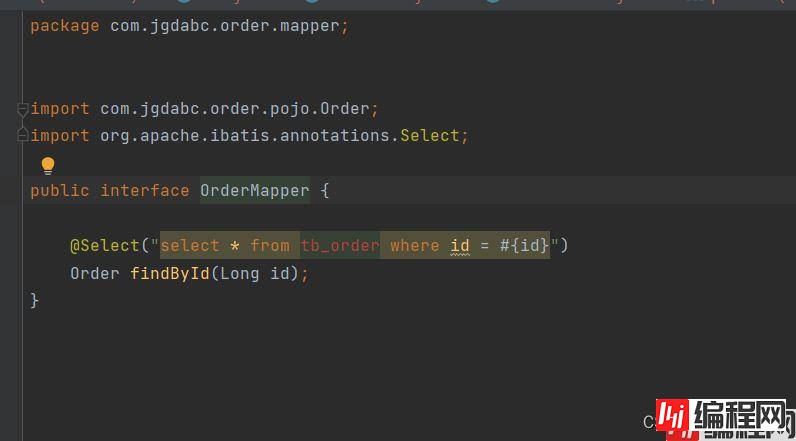
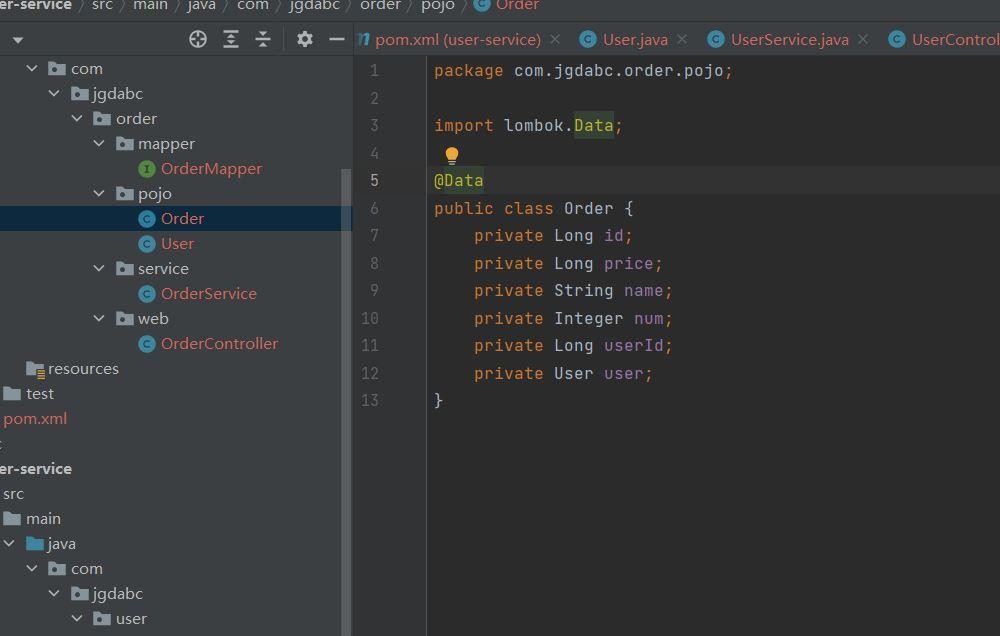



添加配置信息

同样userservice



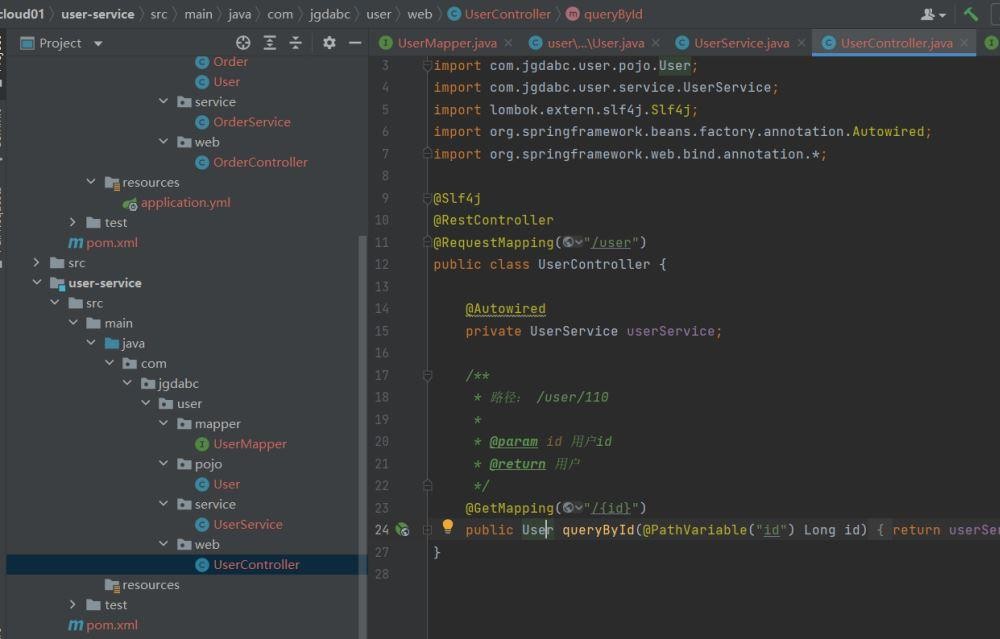
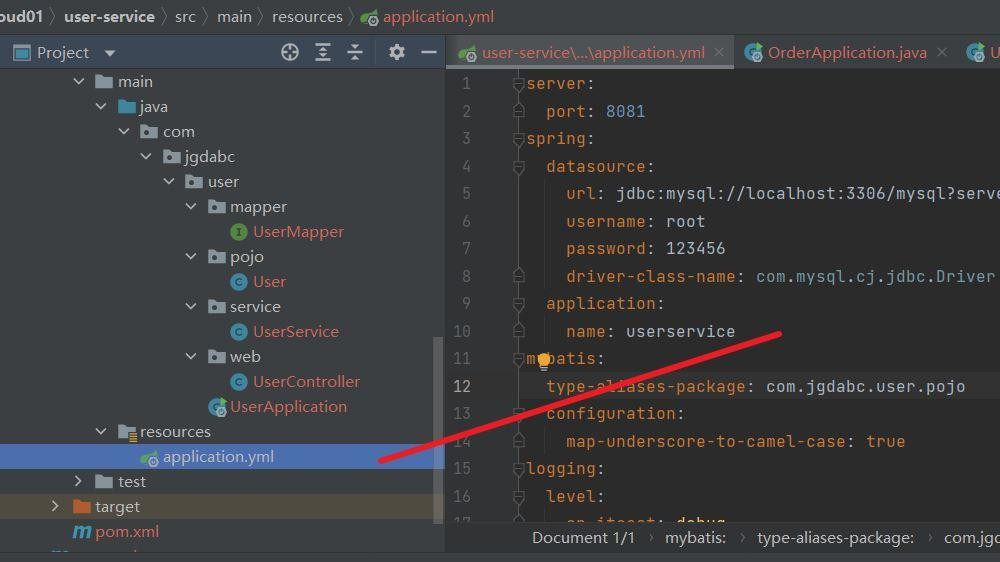
配置yml
这样做好以后我们去做启动类
我们还没有写启动类,
user-service
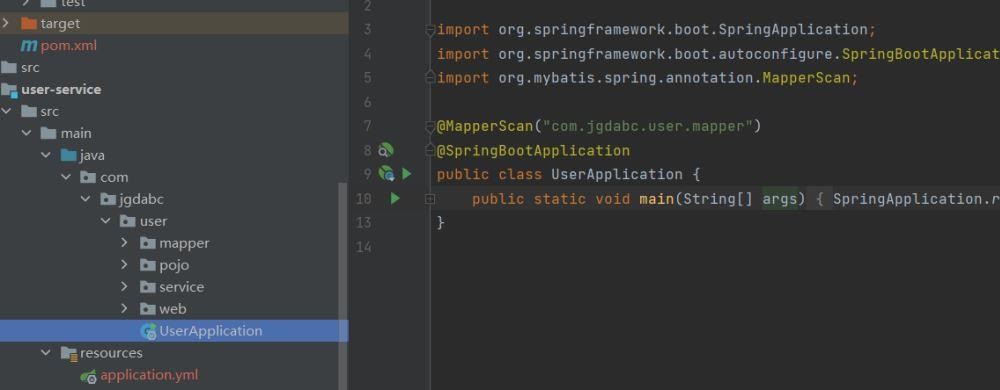
我门需要是用RestTemplate实现服务调用。按照查询的需求,我门需要在order-service这里进行一个查询,我门需要根据请求提交id参数查询出来order的数据,然后根据order数据表里面id对应的用户id查询出来用户的数据,然后进行一个统一的封装。这说明order-sertvice需要调用user-service。
我们来看order-sertvice的启动类
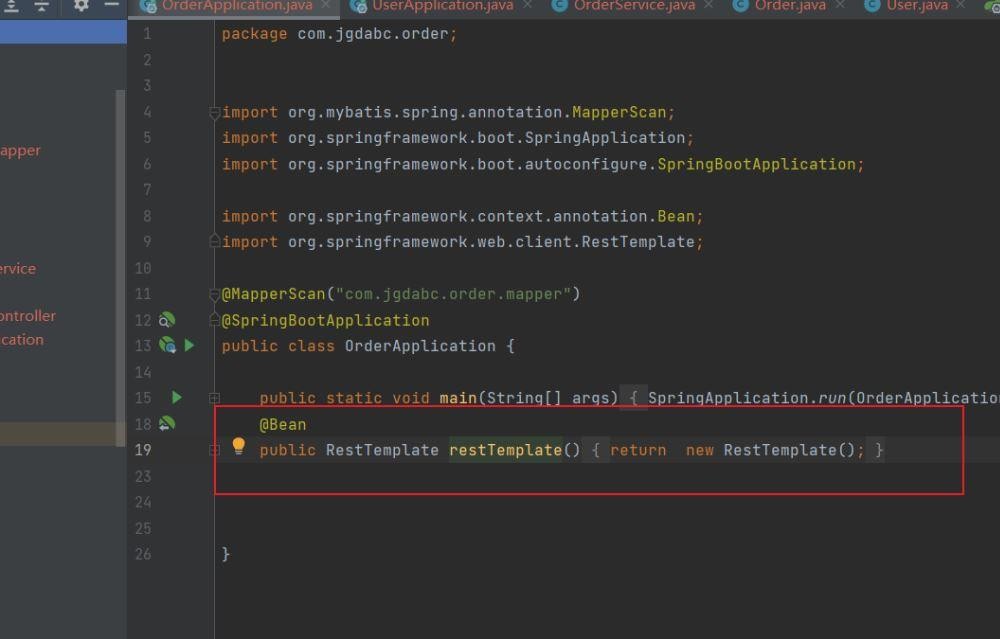
我们除了写出一个启动类的规则后,还new出了RestTemplate的bean。这个bean在哪里使用呢?
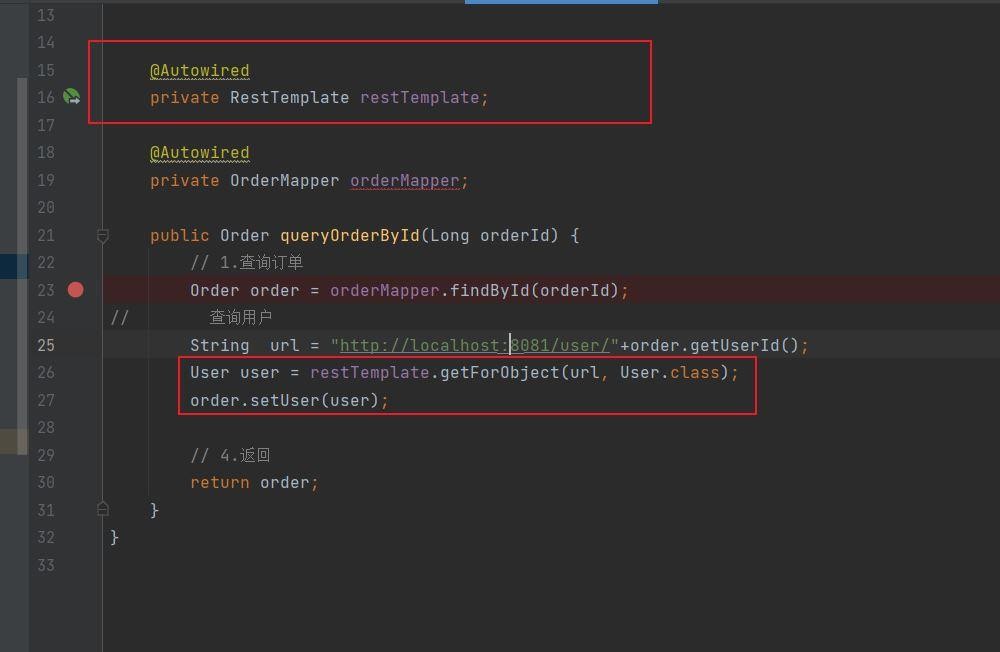
getForObject对应的就是get请求,User.class表示将返回的数据封装到User对象里面。
order-service的端口地址指定过。在yml文件里面。
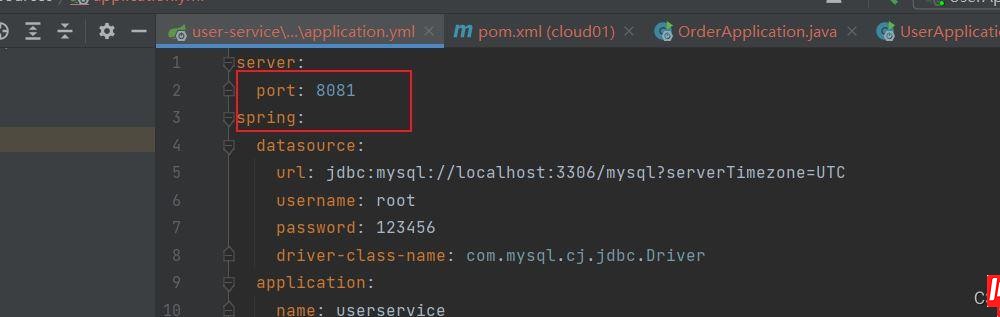
注意现在还没有用到Springcloud的东西,我们目前是模拟实现远程调用。只不过现在和之前相比是将功能模块分开,而且启动的不在是单独的一个服务。
我们需要将两个服务都启动起来。
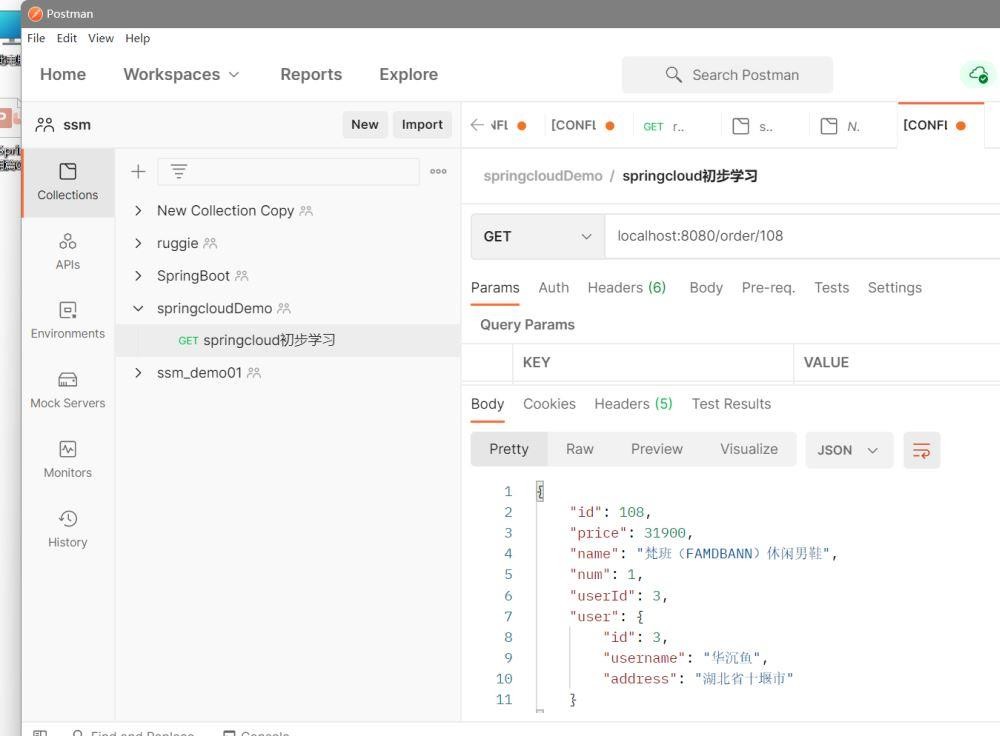
在postman中发送请求

数据测试是没有问题的。但是似乎上面的地址请求显得十分笨拙。还有这里其实并没有实现真的远程调用。只是模块之前的不同服务的之间的调用。还有就是服务的健康信息1我们在调用的时候不得而知,如果对应调用的服务有问题我们在调用前也是无法得知的。如何对服务进行一个更好的管理,我们继续往下看。
说明一下这个是干嘛用的
Eureka 是 Netflix 出品的用于实现服务注册和发现的工具,spring cloud 封装了 Netflix 公司开发的 Eureka 模块来实现服务注册和发现
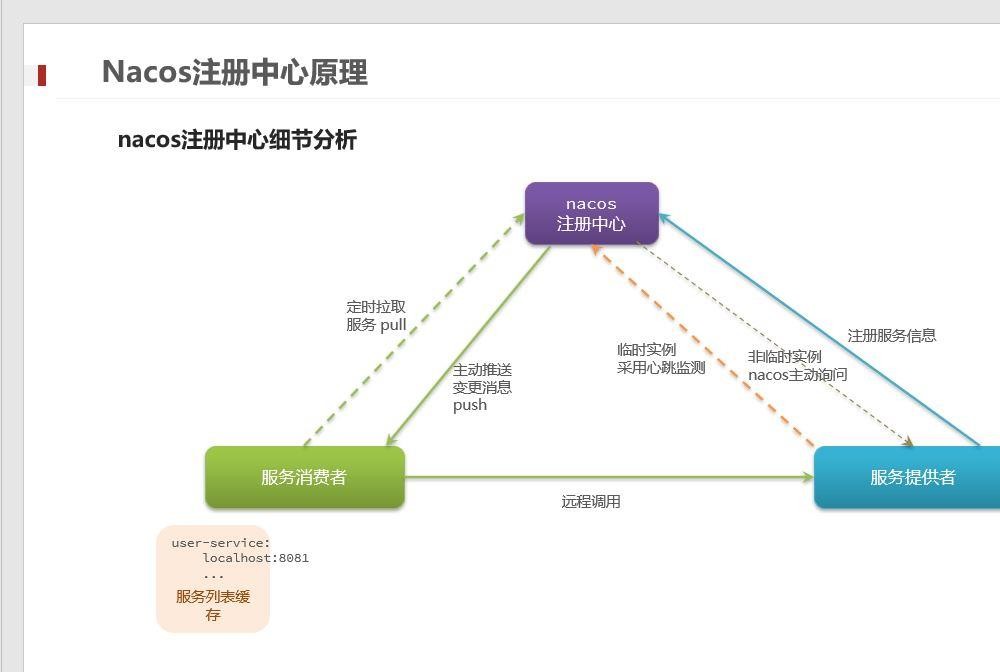
Eureka采用C-S的设计架构,包含Eureka Server 和Eureka Client两个组件
它的原理就是基于服务提供者和服务消费者。像我们的orderservice需要去访问userservice,那么userservice就是服务提供者,orderservice就是。服务消费者。
服务启动后向Eureka注册,Eureka Server会将注册信息向其他Eureka Server进行同步,当服务消费者要调用服务提供者,则向服务注册中心获取服务提供者地址,然后会将服务提供者地址缓存在本地,下次再调用时,则直接从本地缓存中取,完成一次调用。
在默认配置中EurekaServer服务在一定时间(默认为90秒)没接受到某个服务的心跳连接后,EurekaServer会注销该服务。但是会存在当网络分区发生故障,导致该时间内没有心跳连接,但该服务本身还是健康运行的情况。Eureka通过“自我保护模式”来解决这个问题。
在自我保护模式中,Eureka Server会保护服务注册表中的信息,不再注销任何服务实例。
我们可以对服务创建多个节点,如果有的节点挂掉以后,就可以去启用另外可用的服务。
当然这个是基于springcloud的。所以我们需要导入相关的依赖。
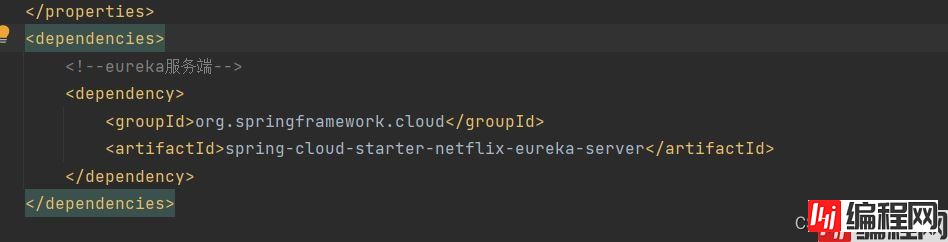
在这之前啊,我们需要将eureka服务端创建出来
我们再创建一个模块
打开这个pom文件添加必要依赖
然后创建启动类

一定要注意启动类要放在java目录的包下面,所以最好创建包后,将这个启动类放到下面,不要直接放在java目录下。
这里我们做的就是服务端。
即热是服务,那么我们还是要配置一下,比如端口等等,所以需要在resource下面创建一个yml文件。
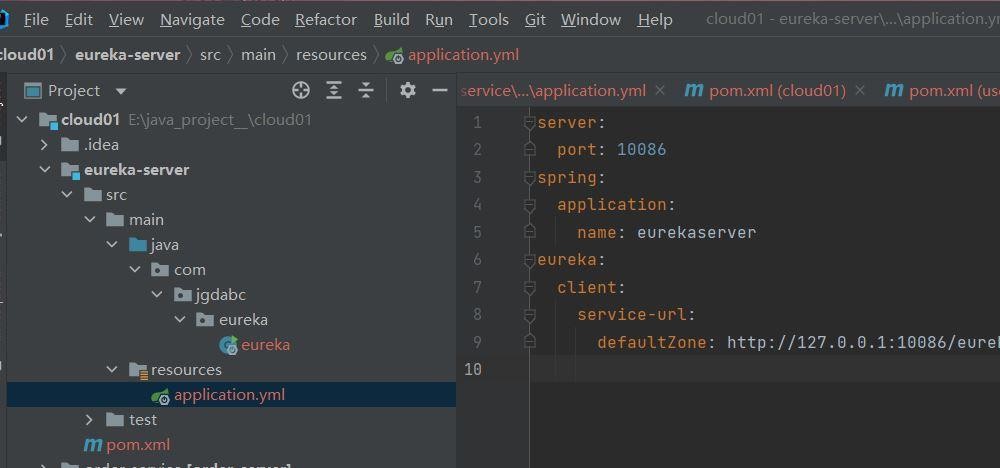
一定要注意yml文件中字段的层级关系,这是非常严格的。
配置完这个后,我们需要配置客户端。
首先还是需要引入依赖。

useservice 和orderservice都需要导入。
另外需要配置服务端的地址

同样是都需要配置。
初步的话其实还有一定就是这里
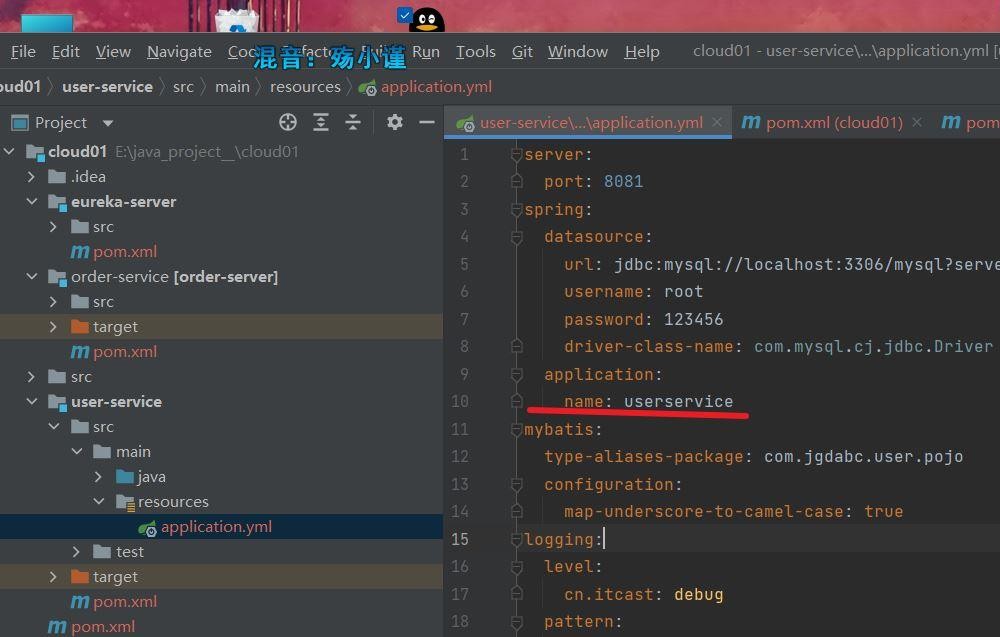
我们需要指定一下服务名称。先这样配置一下,然后去启动
三者都启动
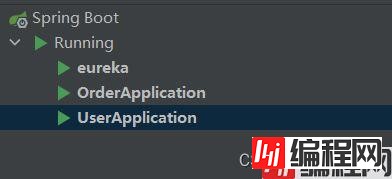
现在需要去访问一个地址

注意端口10086后不需要加eureka
我们现在需要去查看服务是否注册成功,或者说eureka服务端是否将userservice 和orderservice加入实例。

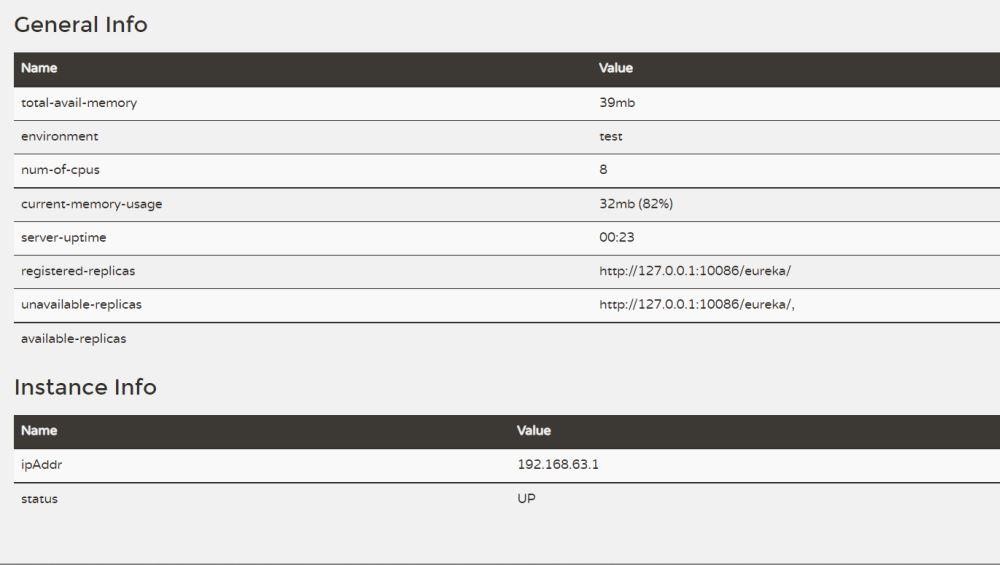
这样就成功了。
然后我们就可以开启去使用它了。
这里我们可以修改一下这里

但是在这之前,我们需要做一个负载均衡的指定,否则是无法解析服务地址。
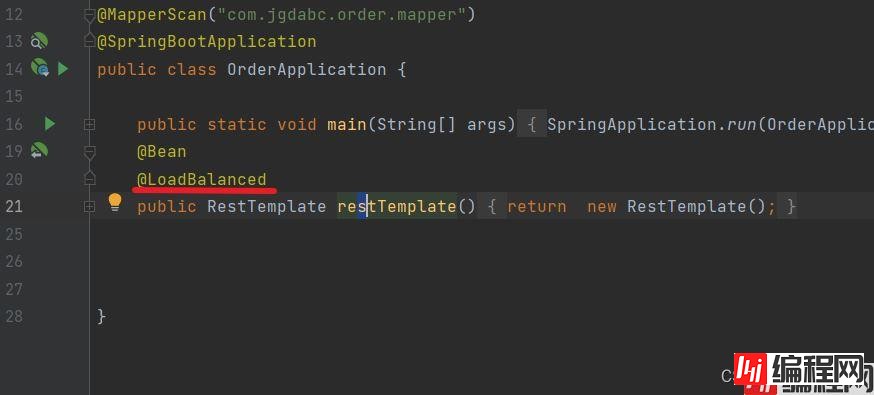
然后这样
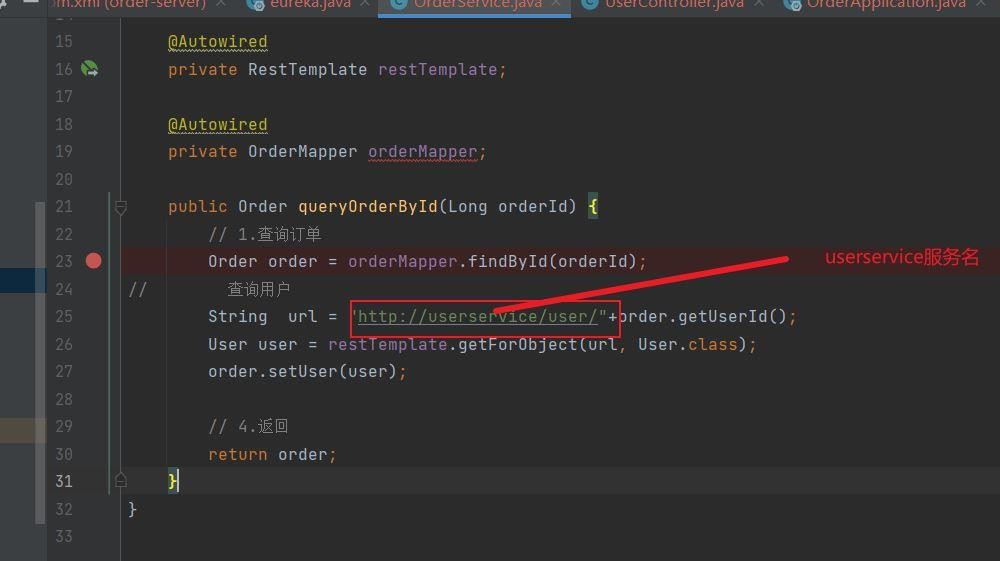
这样我们再次启动,就可以去访问了。
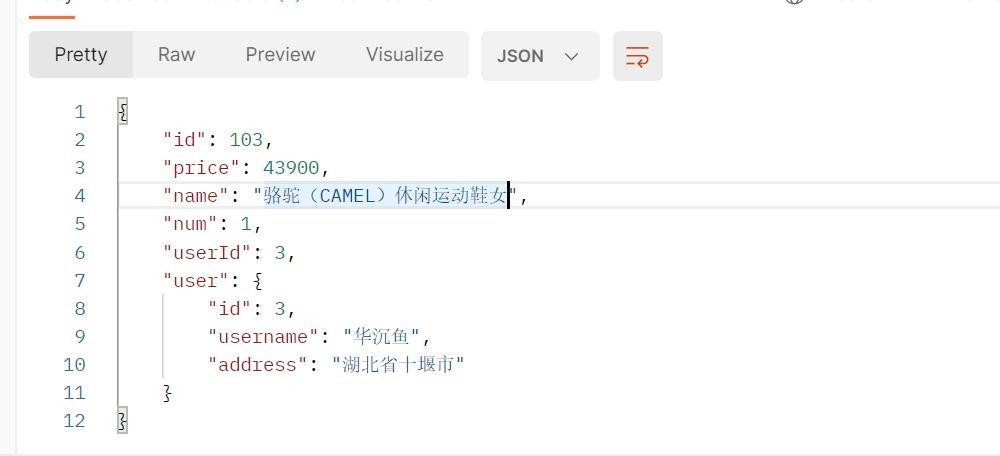
上面我们用到了负载策略
负载均衡是高可用网络基础架构的关键组件,通常用于将工作负载分布到多个服务器来提高网站、应用、数据库或其他服务的性能和可靠性。
注:图片数据来自知乎
什么是负载均衡
从这里可以去看负载均衡策略
没有负载均衡的服务架构
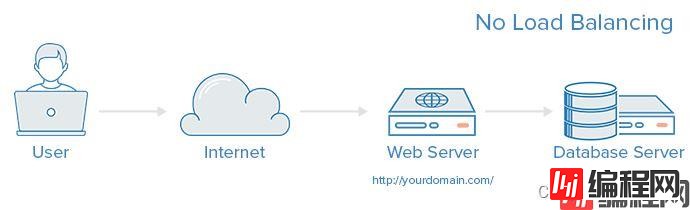
有负载均衡的服务架构
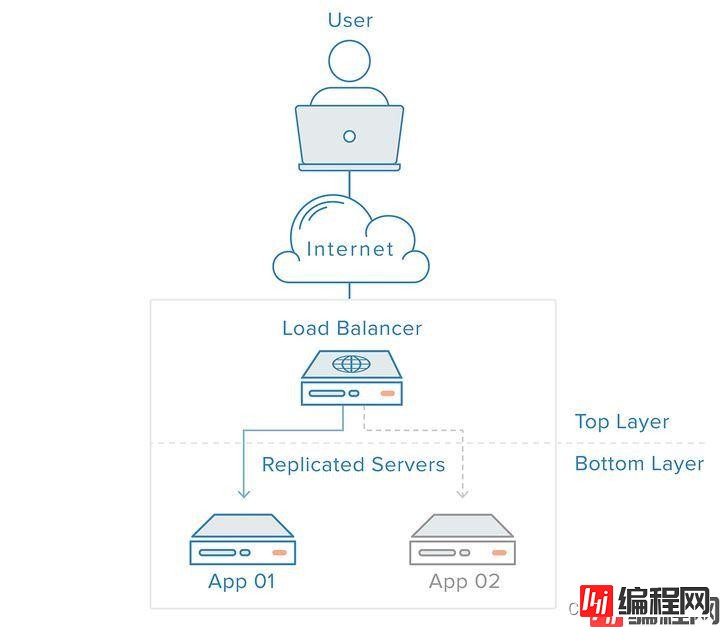
我们这样的特点可以去用多实例部署的特点。
定要记得修改端口


将这个服务启动起来
然后我们去eureka注册中心看看有没有实例
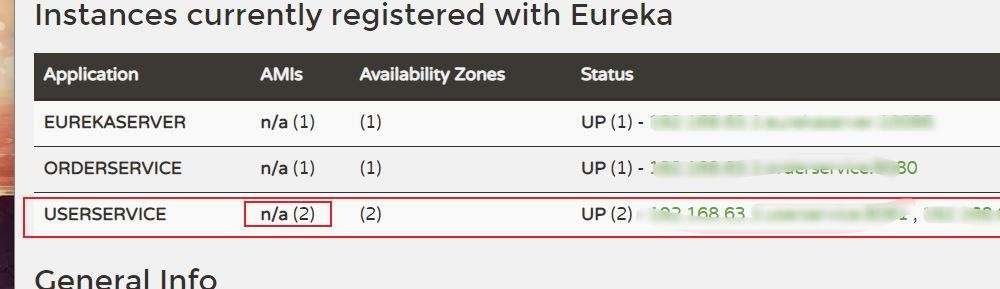
可以看到userservice一共有两个实例对象了。
这样创建多实例的好处就是如果一个实例存在问题的话就可以换另一个。我们这里就模拟了多实例部署。
还有我们需要去观察一下这个负载均衡策略,其实默认是轮询的负载均衡策略。
我们可以去测试,多访问几次userservice,而现在userservice有两个实例,我们在postman测试工具做出测试,发出请求,看看具体调用的哪个实例。
注意现在需要改一个东西,就是上面有一个错误的地方。有关日志的。

logging.level设置日志级别,后面跟生效的区域,比如root表示整个项目,也可以设置为某个包下,也可以具体到某个类名(日志级别的值不区分大小写)这里需要注意,上面的包名没有写对。
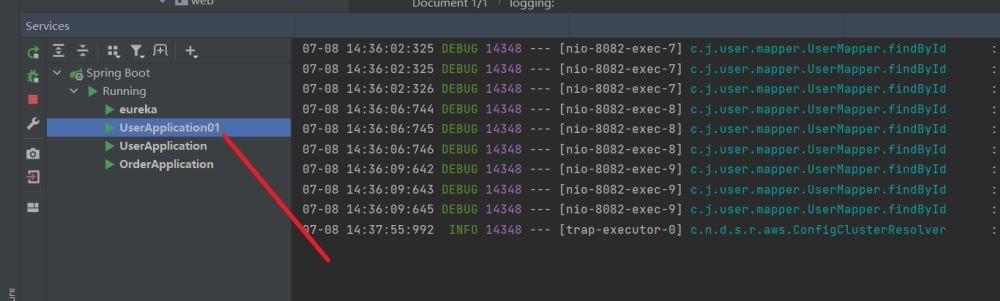
然后开始测试,首先将控制台的输出全部清除掉。

我这里从1到6一共访问6次。
然后来看控制台的日志输出,可见这是轮询的方式



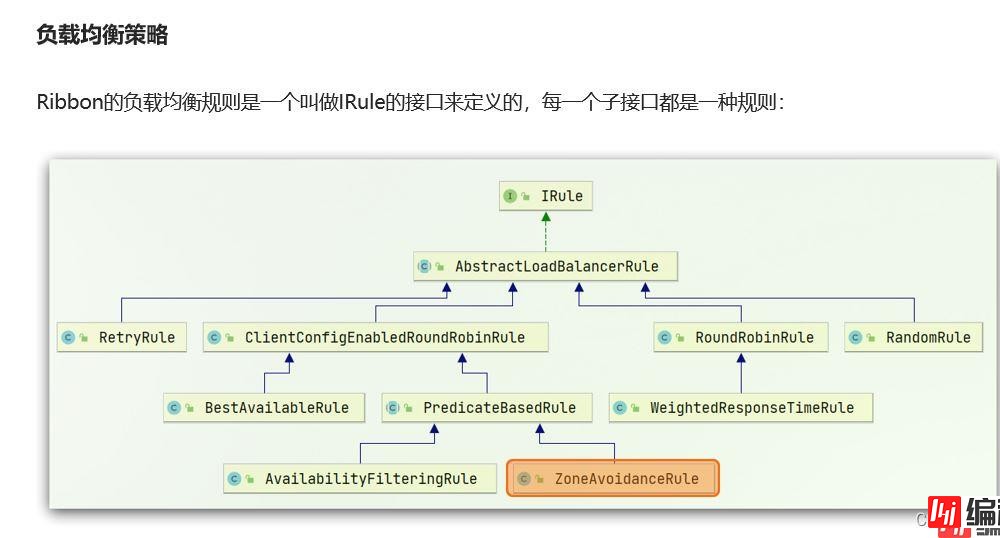

默认的是轮询,我们可以自己去指定一个规则

所以就从这里来重新指定规则
我们在orderservice的启动类里面写,当然这个是代码的方式。并且,我们需要将它做成一个bean。
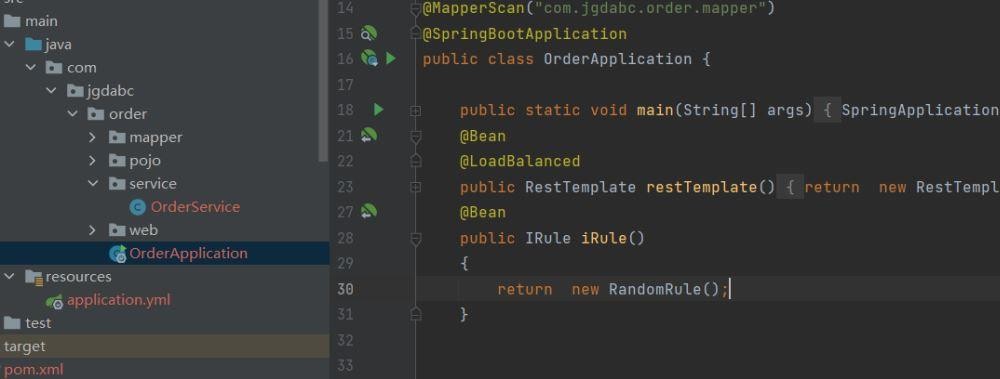
我们这样定义是选择了随机的原则,代表随机选择一个服务器。
然后我们去重新启动测试


测试成功
如果采用配置文件的方式
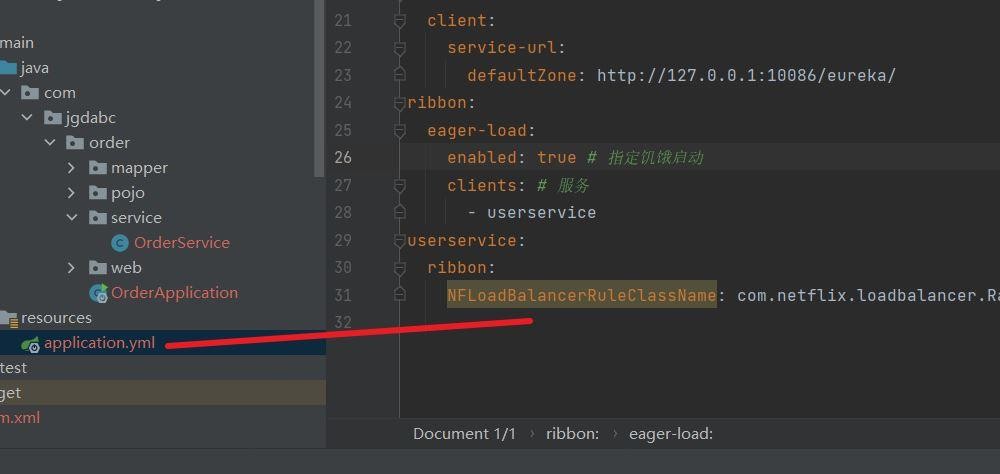
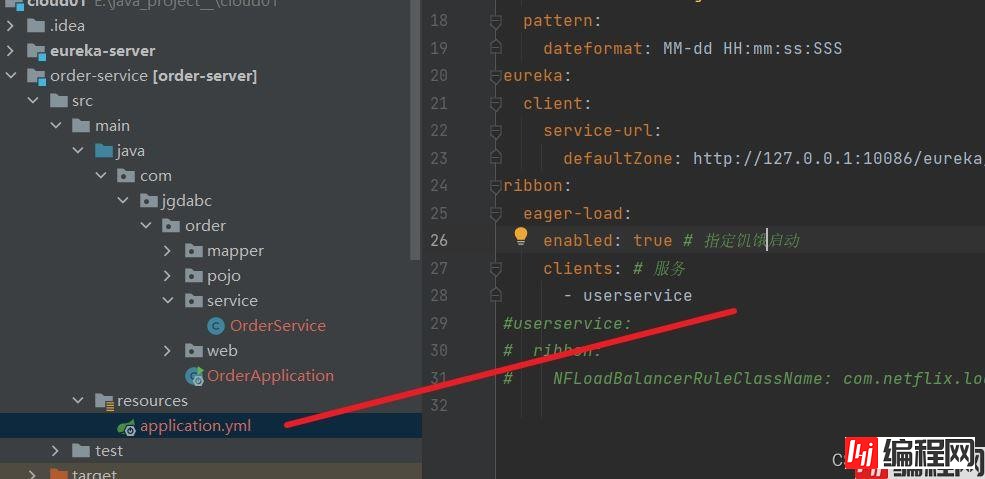
两者配置不同之处在于作用范围。代码配置的话就是会在全部服务中起作用,而配置文件配置的话就只会在指定的服务起作用。
还有一个就是关于启动问题的知识点,默认是懒加载。

我们这样去配置
Nacos是阿里巴巴的一个产品,说实话,这个注册中心是真的好用。下面我们开始介绍。
首先我们需要安装这个服务,服务区官网下载就可以了。

官网 可以选择点进去GitHub下载服务。
目录结构
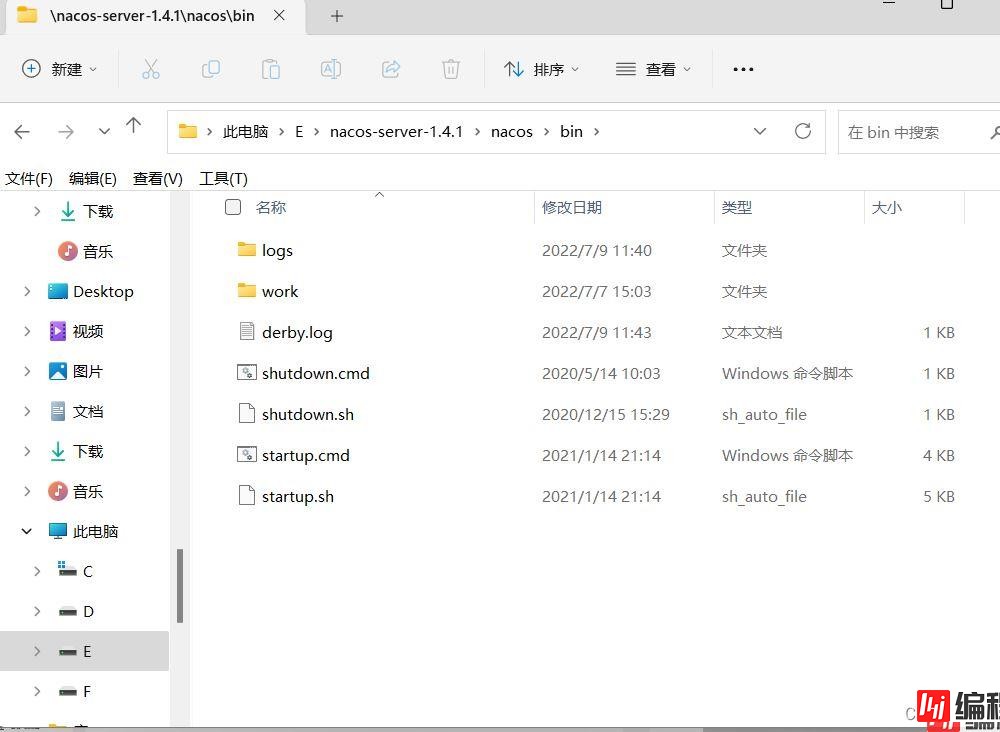
然后进去bin目录里面,进行执行开启服务
如何开启服务,打开手册。

在快速开始这里,我们可以进行执行命令。

将这个命令执行后就可以开启这个服务了

然后我们去idea里面配置相关的东西
然后在里面配置相关的依赖,配置依赖的话就需要注释掉eureka的依赖。
如果没有在父工程添加阿里巴巴的依赖的话,我们需要进行添加依赖。
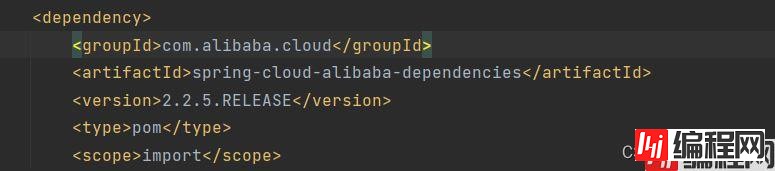
将这个依赖导入到父工程里面。
然后在子工程中将原来的eureka的依赖注释掉
在pom文件当中配置的就是客户端依赖。因为服务端是已经下载安装的。
我们需要将服务端的service和客户端的sevice都配置依赖。
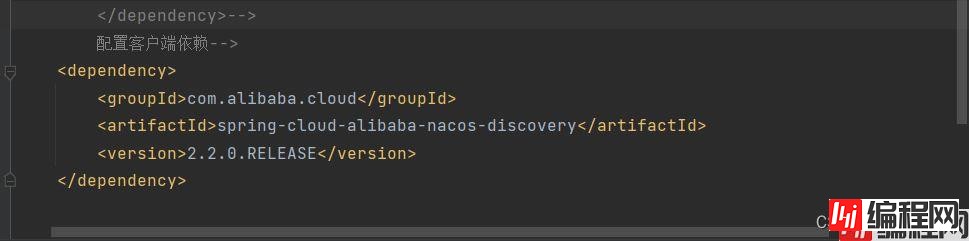
然后我们进行配置yml文件进行配置
然后将eureka的配置注释掉

然后我们将这几个服务启动。我们现在就不需要去启动eureka了。

我们访问nacos的服务列表
管理页面访问地址
进入到服务列表,我们可以看到服务列表查看注册情况
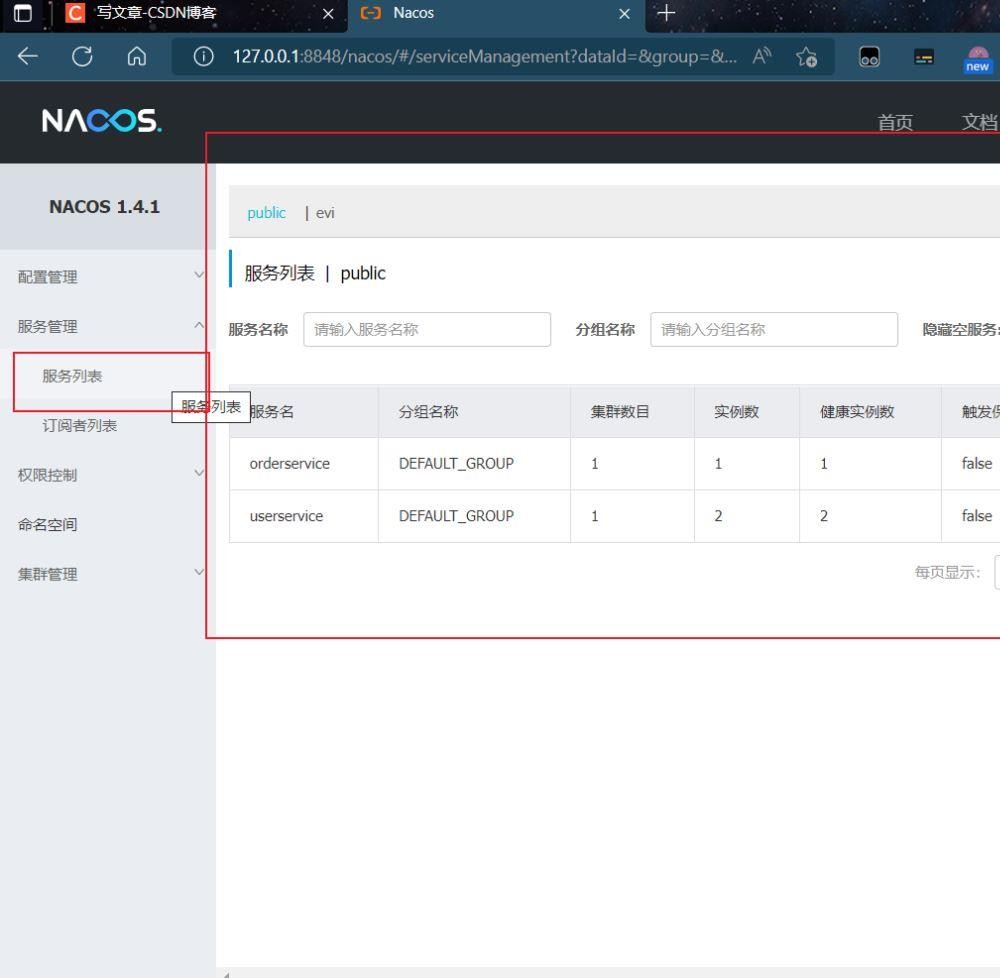
至此注册成功。而且我们可以看到这里userservice一共有两个实例。
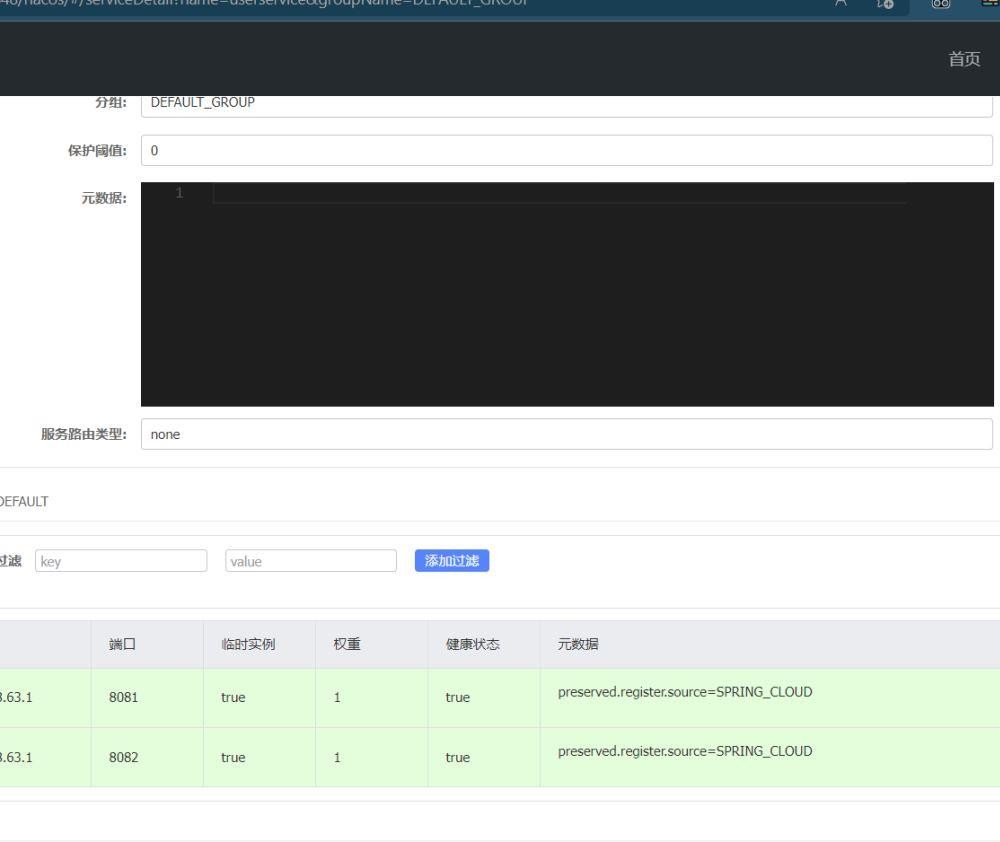
这里我们可以看到具体的一些信息,包括端口号,已经健康状态,后面可以进行一些操作,包括服务上线下线的操作。
我们可以进去到服务列表具体实例的详情,可以查看到一些具体的信息。

这里引入了一个新的概念。集群的概念。
这里先不用去关注集群的具体的概念,但是在结合分布式服务的话,集群可以帮助我们解决服务的跨区域的问题。跨区域部署服务器。
按照上图所示集群部署的话,可以部署在不同的地域。杭州,上海等等。然后我们通过nacos进行集群管理。包括相关的实例部署等等。
我们可以去模拟配置集群
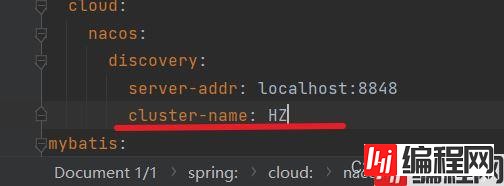
这里我们指定了一个集群,表示部署在此地。我们可以对这些服务都指定相关的服务集群

好,现在再次启动重新服务
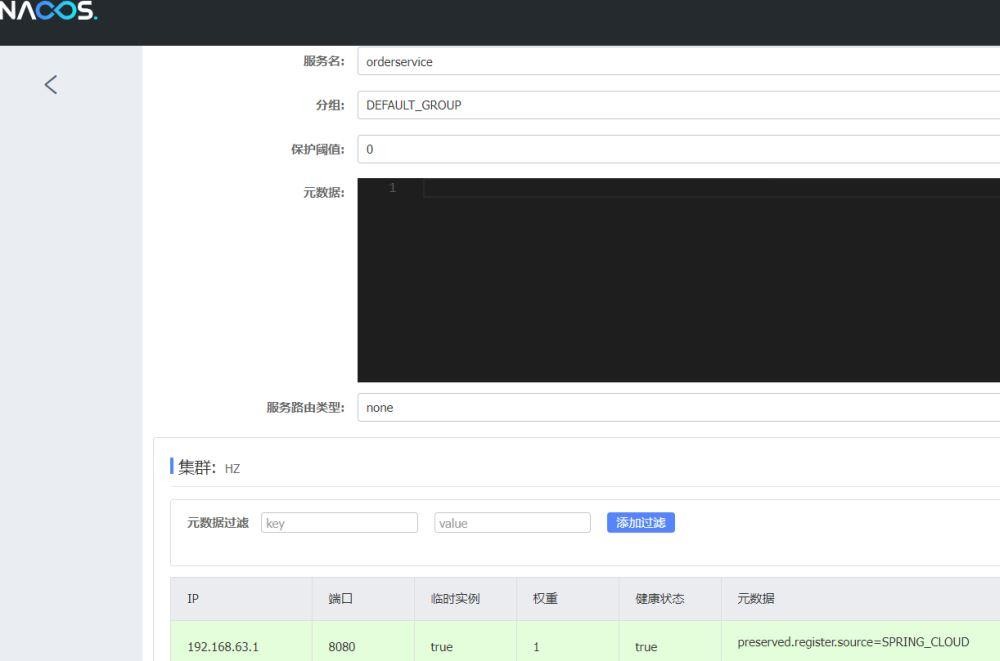
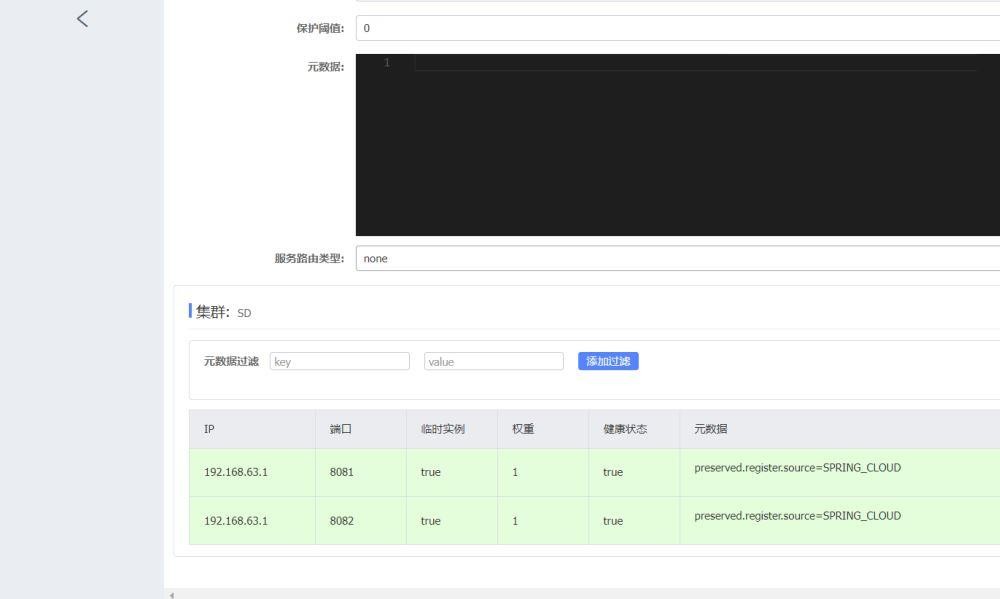
我们可以看到一共有两个集群,这样我们就指派成功了。
在nacos 也可以进行加权负载均衡
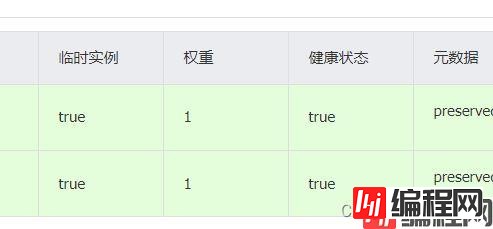
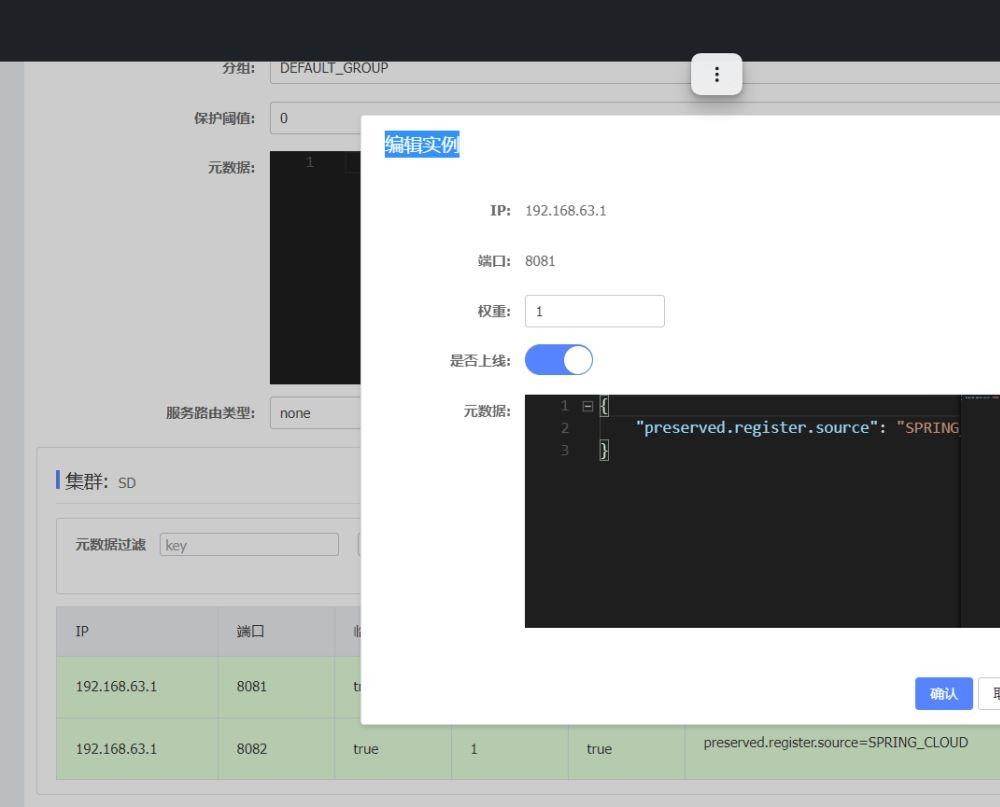
我们一共有两个usersrvice的服务,我们可以去指定其中的一个权值,权值越低被访问调用的几率越1低,权值为0的话就不会被访问了。我们可以测试。
我们可以用postman进行访问测试。
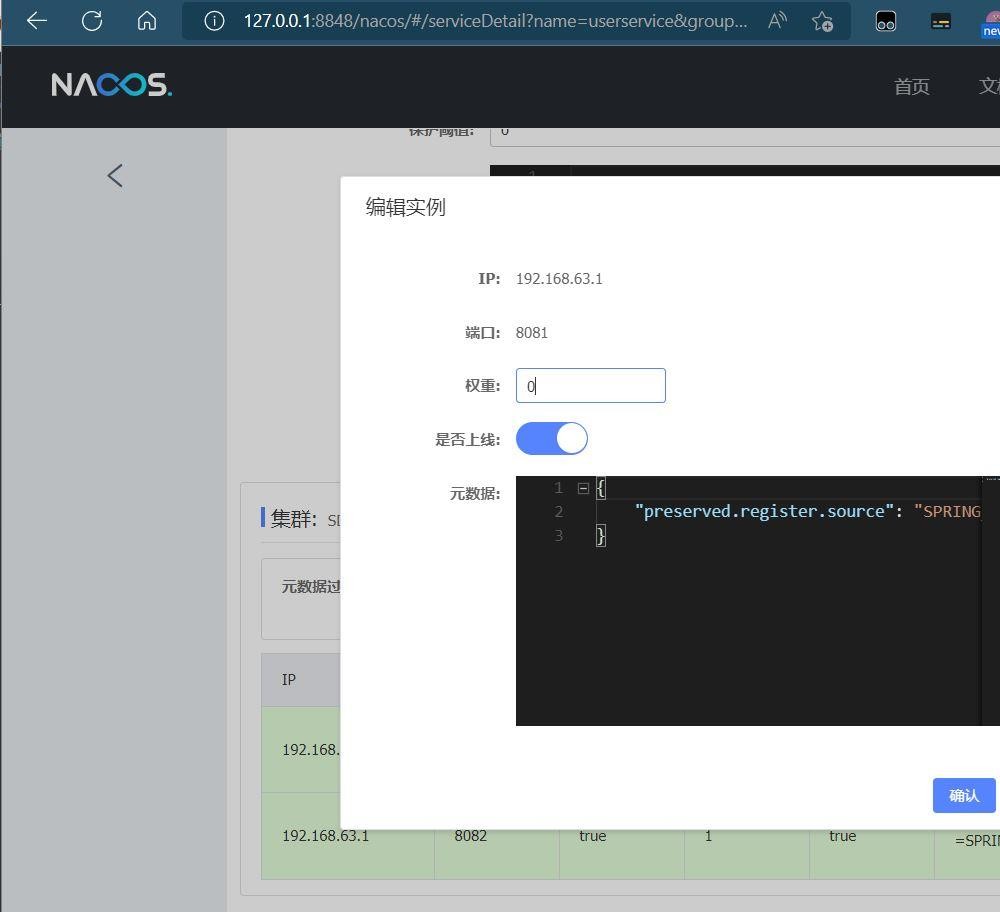
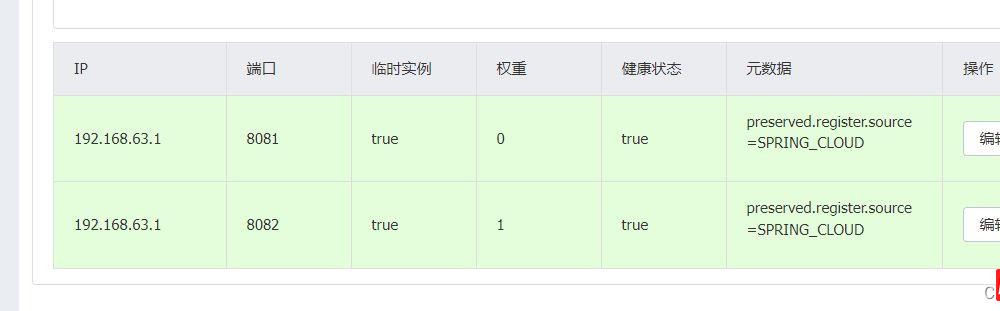
用postman进行测试

可以看到多次访问都没有访问到权值为0的服务实例,这样其实就实现了一个权值的负载均衡策略。
当然你可以指定其他的值。
其实还有可以进行环境隔离的操作。
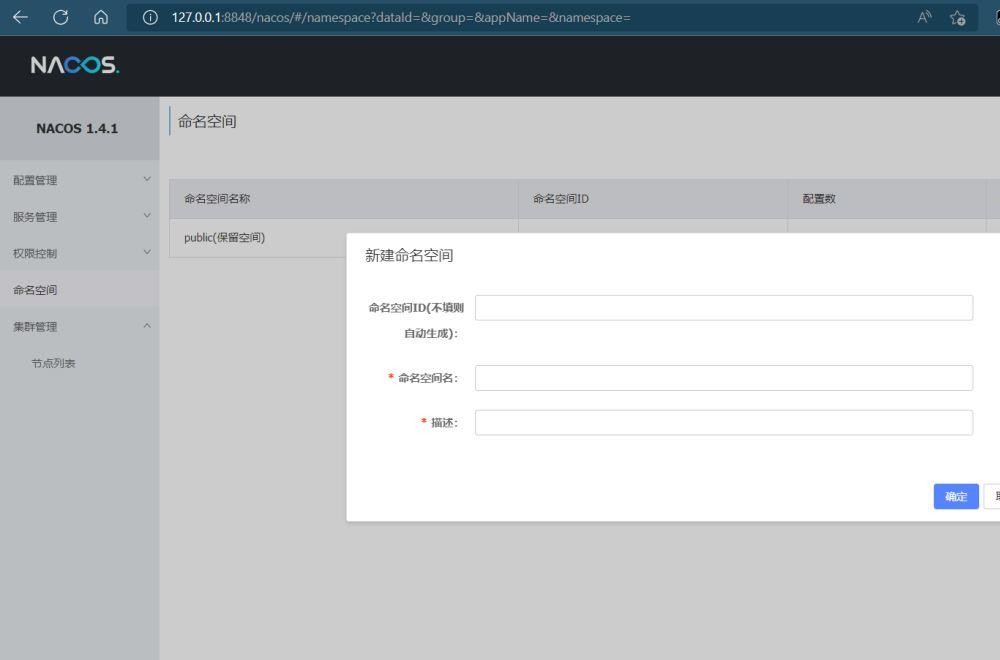
现在nacos操作平台进行生成新的命名空间。
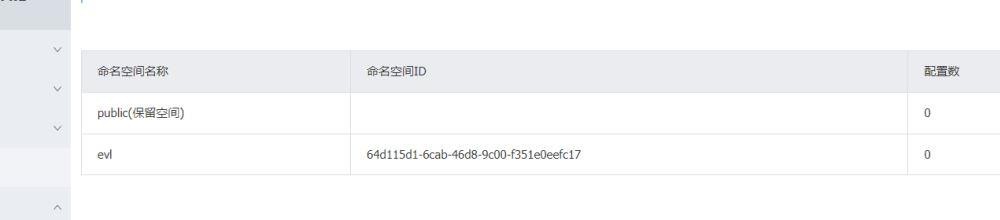
我们的之前的命名空间就是public类型,是一个保留空间。
我们可以自己去这里创建空间,然后自己在代码配置中指定给那个服务配置相应的空间。
填写保留空间的名字和描述就可以,Id可以自动生成。

我们给具体的服务配置命名空间,就配置namespace,然后将id复制过去作为键的值。
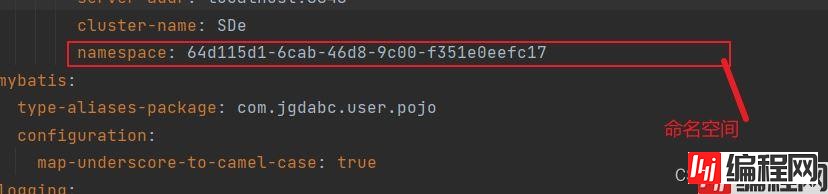
命名空间的作用就是相当于起到环境隔离的作用。
如果服务在不同的命名空间,那么这两个服务就无法互相访问。
现在我们重新启动userservice的一个实例,我们可以将,然后这个实例是必然不会和orderservive在同一个命名空间。是不会访问到的。
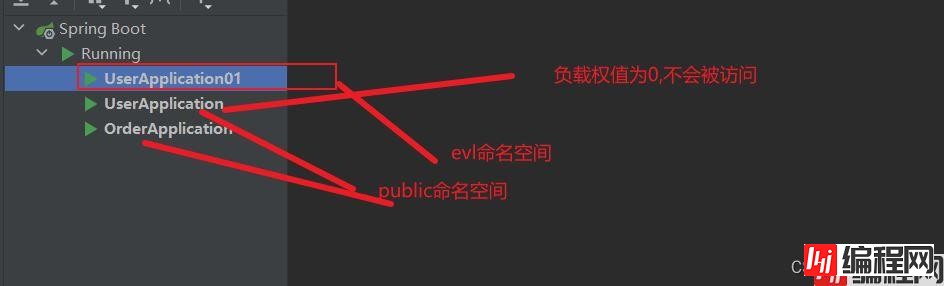
我们测试orderservice能不能访问到userservice的服务端1。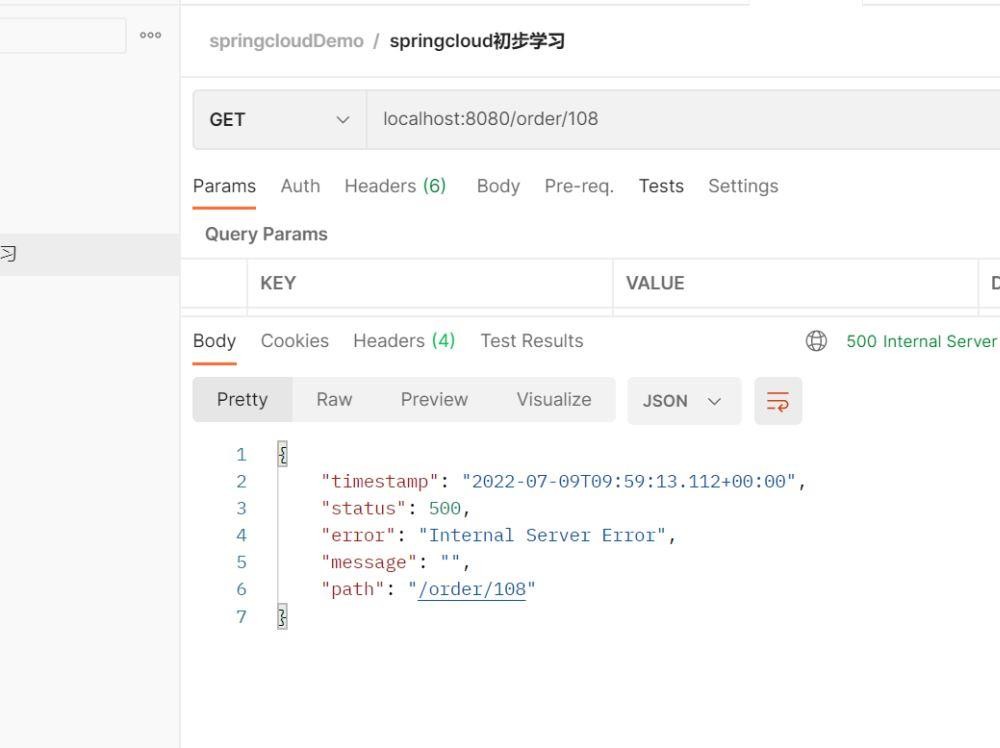
可以看到是不能访问到的。
临时实例和非临时实例(存在依赖的修改更正)
临时实例的服务在宕机后会从nacos的列表中被删除掉,而非临时实例不会被删掉。
到这里发现我之前导入的依赖是不能这样设置的。
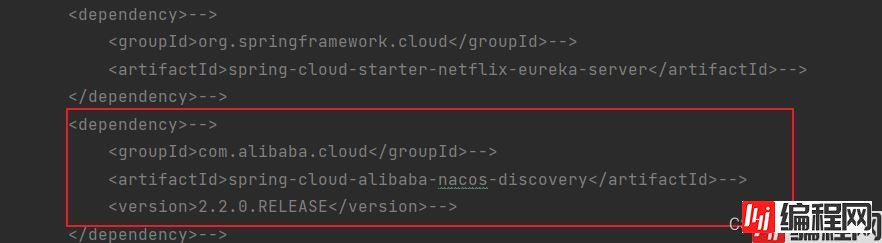
前面的设置都可以支持
想要支持实例的配置管理的话需要导入这个依赖
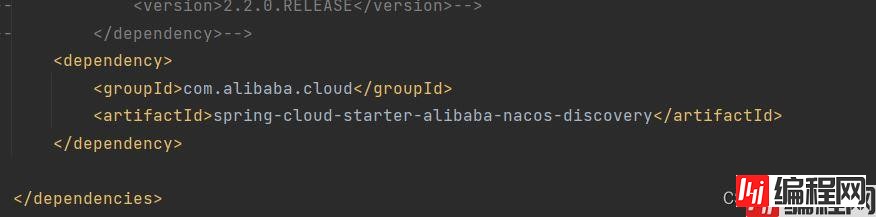
在自己需要的服务里面导入进来。我现在只在useservice这里进行验证临时实例和非临时实例的特点。
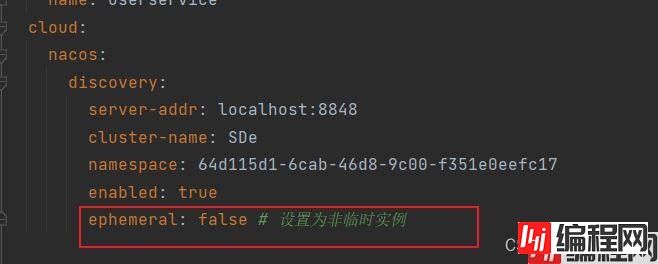
我现在的服务都重启
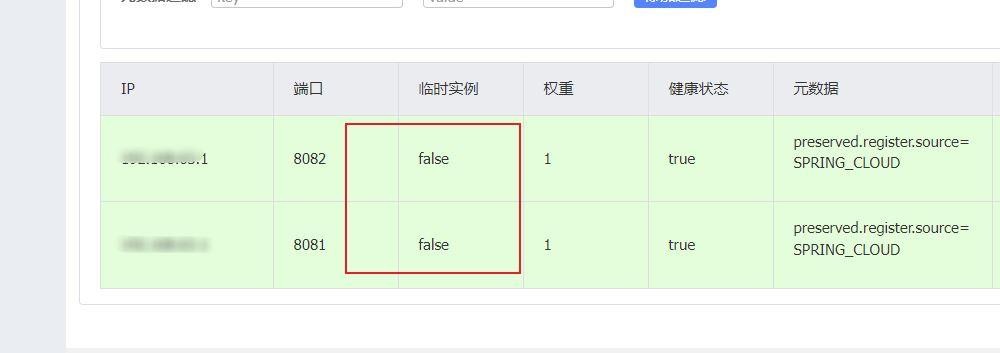
注意看这里,全部为false,然后现在为了对比做这样的操作。
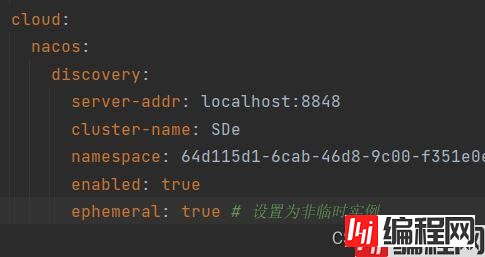
我将其中一个停掉。然后改为true
然后再启动
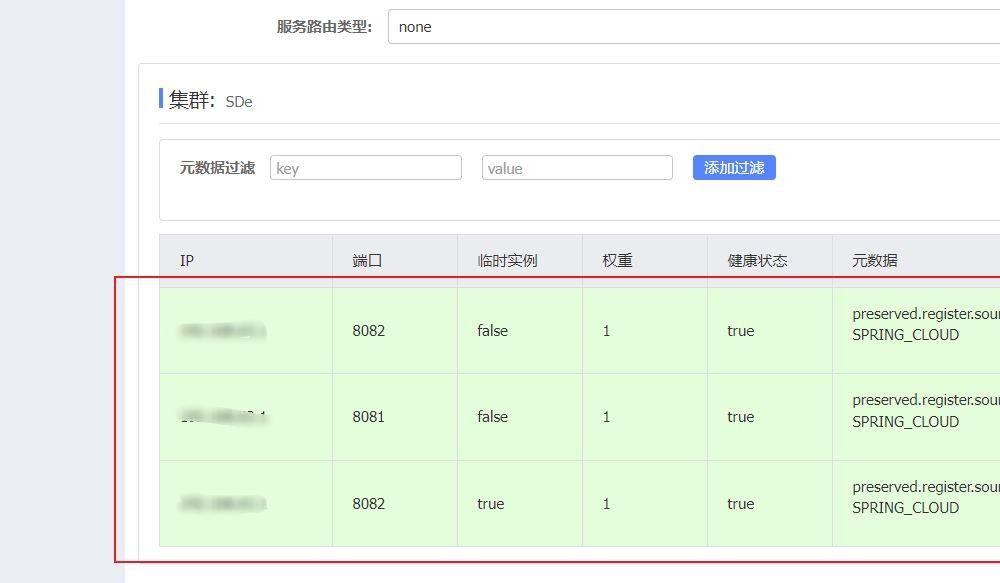
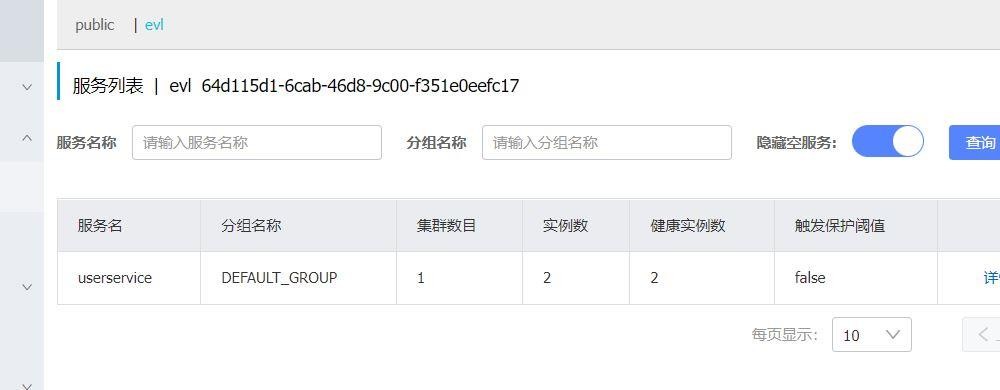
你看这里发生了什么。为什么会有两个8082的端口的实例服务呢?原因是我们之前给它设置为非临时实例,就算我们刚刚重启了服务,但是它不会被删除,现在我们关闭服务,看看设置为true的这个实例会不会被删掉。
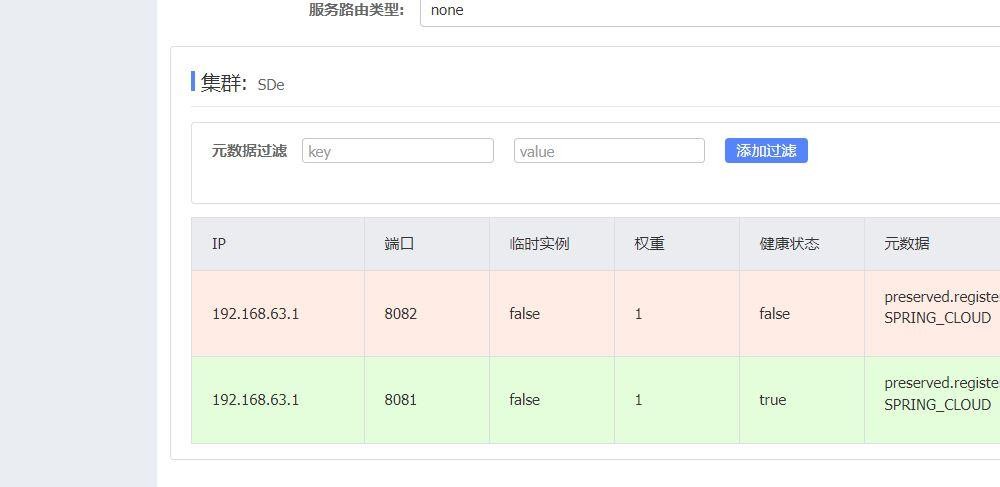
看吧已经删掉,还有一点这里的健康状态和这个颜色我们之前的这个都变了。
对于临时实例和非临时实例的区别,nacos也做出了不同的检测
临时 实例:nacos会在超过15秒未收到心跳后将实例设置为不健康状态;
超过30秒将实例删除;
非临时实例:nacos主动探知客户端健康状态,默认间隔为20秒;
健康检查失败后实例会被标记为不健康,不会被立即删除。
我们先了解nacos是如何加载配置的
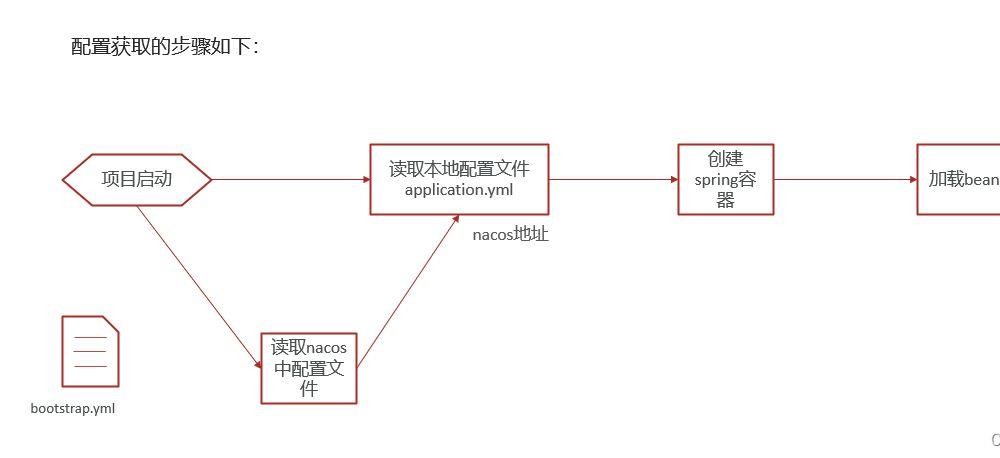
我们想要做的的是在nacos的管理界面进行配置,然后这个配置首先可以被加载,然后这样的加载配置在我们发布以后会自动生效,而不需要我们重启服务器,这样的配置更新方法也叫做热更新。
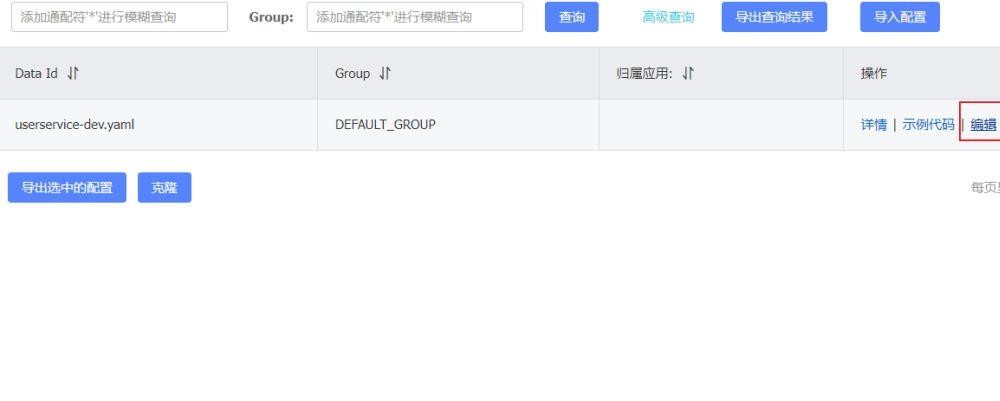
具体怎么做呢?我们先去nacos的配置管理界面。在这里我发布了一个新的配置。

我们来看具体的详情
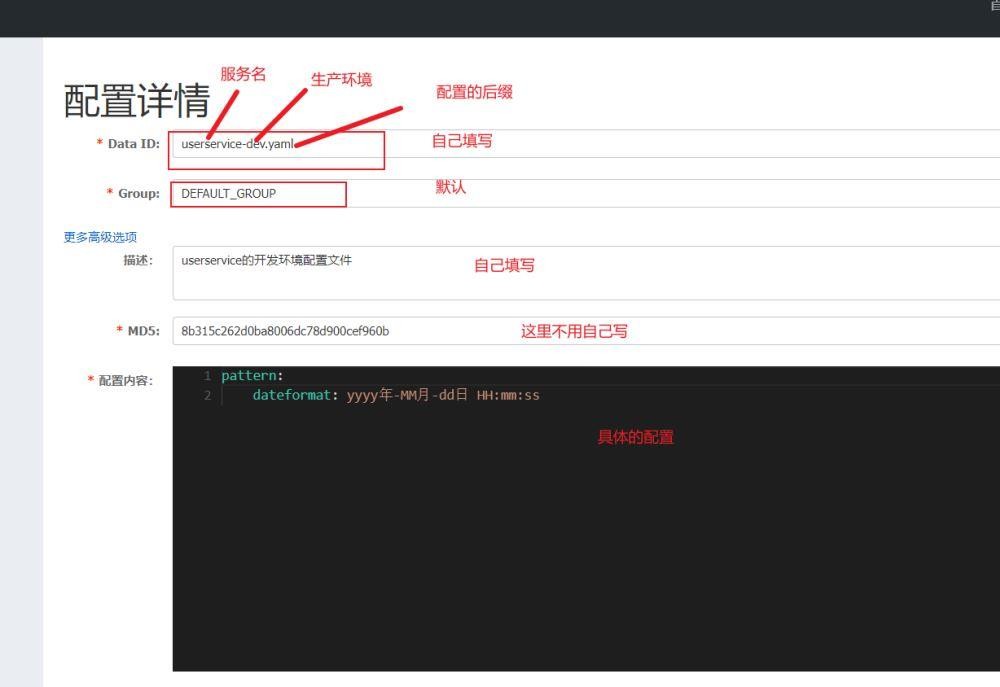
这样配置后然后发布就可以了,当然这只是在nacos的配置列表进行的配置。我们还需要在idea里面操作一些东西。
我们还需要引入一个依赖。nacos的配置管理依赖
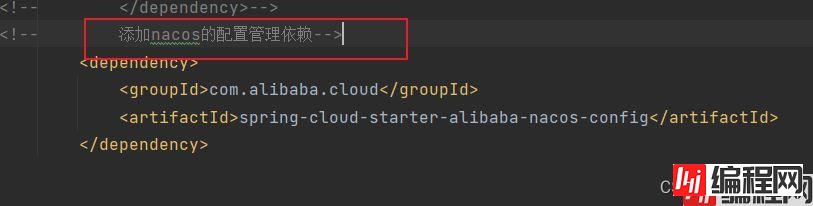
这个配置依赖需要在你想要进行统一配置和热部署操作的服务的pom中添加。
然后我们需要创建一个配置文件

这个配置文件的优先级别高,nacos会先加载这个配置文件,然后会加载application.yml文件,将着两个配置文件的配置合并一起。
要记得在原来的配置文件中注释掉一些可能重复的配置或者非必要的配置。
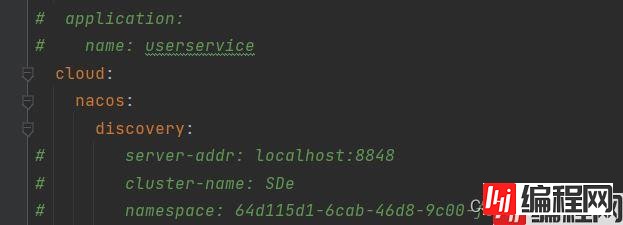
服务名,还有地址,集群的话不需要,命名空间的话,因为我的nacos添加的配置在public下面,所以我把之前指定的也注释掉了。
在nacos管理配置列表配置的一些东西和这里是对应的,所以一定要细心注意。

这样的话我们如何知道配置生效,或者如何去验证热部署成功?
我们可以通过value读取,将这个数据读到Controller里面,给这个值配置一个访问路径。我们可以这样去做。

这里有个坑,就是如果你的nacos无法解析的话,就需要升级一下。升级到1.4.2.。
还有一点就是需要配置自动热更新。

我现在的服务已经启动,我们去访问。
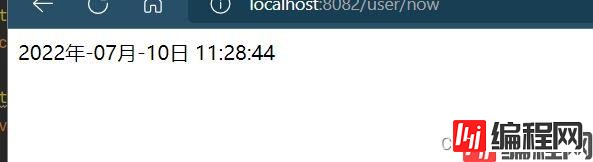
你看这样搜先加载到了。
现在我们在nacos配置管理那里稍微改动一下。
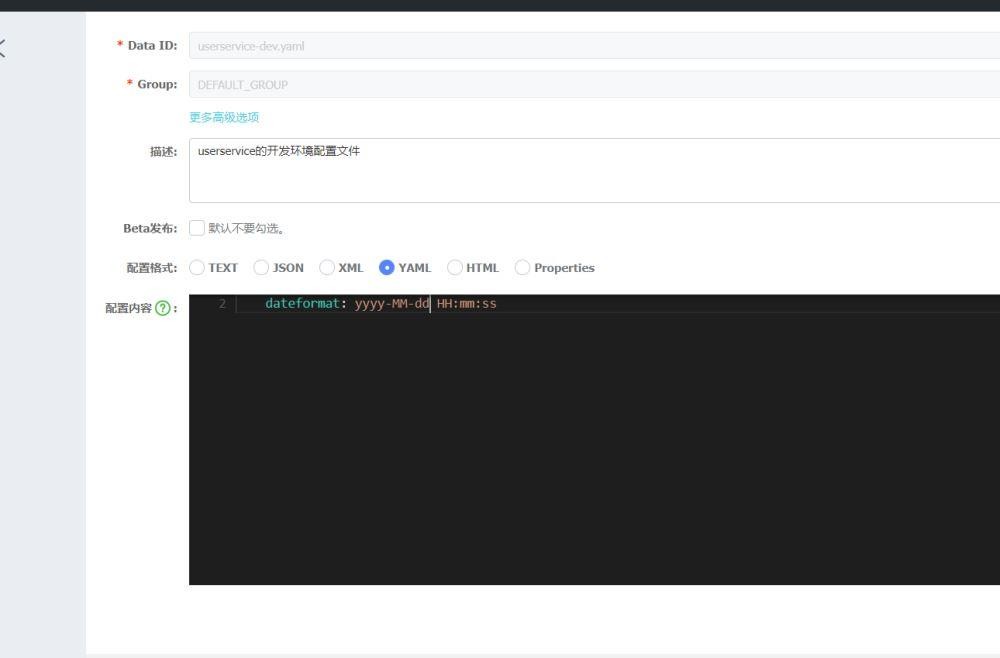
发布的时候会告诉你原始值和你修改的。
现在我们再去访问

这样就验证成功了。热部署成功·。
还有一种属性注入方式
我们需要去写一个配置类

然后在Controller里面这样做

还有这种方法不需要去添加这个注解

需要注意的是,可能存在bean无法注入的问题。那么我们可以去给他扫描。

------未完续更,等待
到此这篇关于SpringCloud 分布式微服务架构的文章就介绍到这了,更多相关SpringCloud微服务架构内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: SpringCloud 分布式微服务架构操作步骤
本文链接: https://lsjlt.com/news/164138.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0