Python 官方文档:入门教程 => 点击学习
1.beautifulsoup4库安装 第一步:在控制台输入如下命令,安装beautifulsoup4库。 pip install beautifulsoup4 第三步:在Py
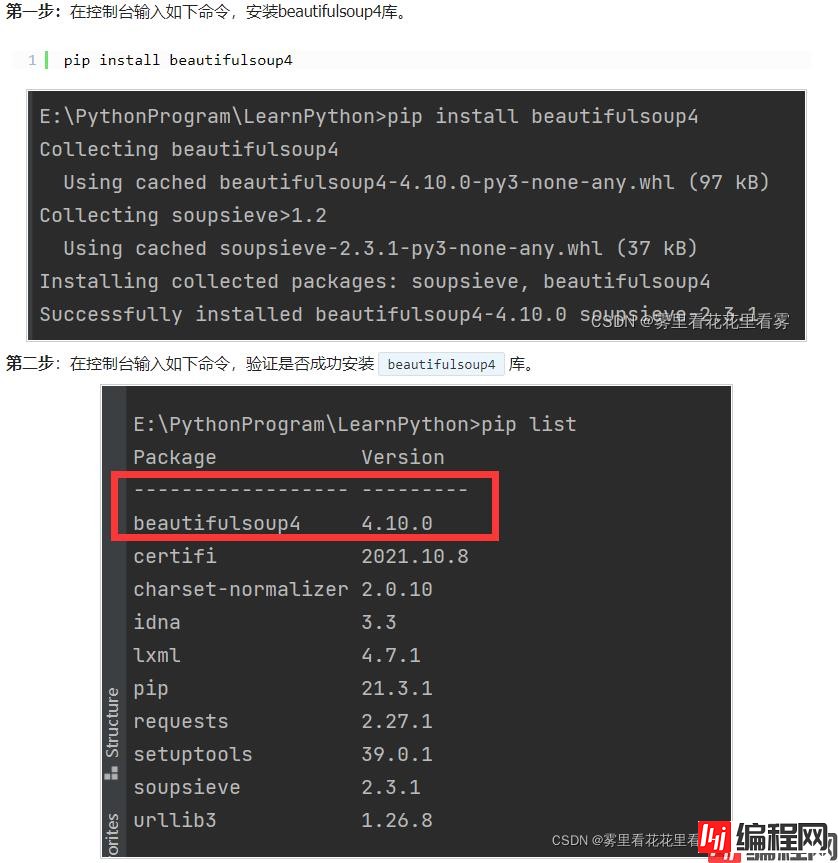
第一步:在控制台输入如下命令,安装beautifulsoup4库。
pip install beautifulsoup4
第三步:在PyCharm中,点击file——settings——project——python interpreter——点击+号——搜索beautifulsoup4——install package!

这样就可以在.py文件中导入模块了!
import requests
# 虽然库名叫做beautiful4 但是在导入时 使用的是其缩写bs4 其中BeautifulSoup是一个类名
from bs4 import BeautifulSoup
url = 'https://www.baidu.com/s?'
# 由于一般网站都是供用户访问 如果检测到User-Agent是黑客或者其他可能拒绝访问 故此处模拟浏览器
headers = {
'User-Agent': 'Mozilla/5.0 (windows NT 10.0; Win64; x64) AppleWEBKit/537.36 (Khtml, like Gecko) Chrome/97.0.4692.71 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# 以防乱码 此处将其编码设置为utf-8 因为有中文
response.encoding = 'utf-8'
# print(response.text)
# 使用的解析器是html.parser 注意是.奥
soup = BeautifulSoup(response.text, 'html.parser')
# 打印解析后的结果
print(soup.prettify())需要讲解的都在代码注释中了奥!
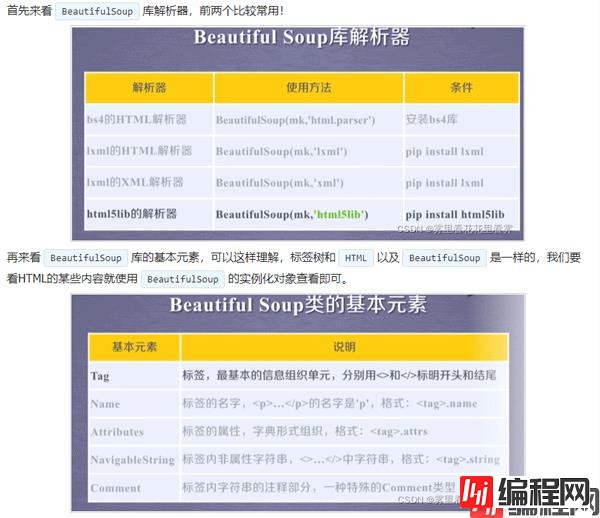
beautifulsoup4库是解析、遍历、维护“标签树”的功能库。
首先来看BeautifulSoup库解析器,前两个比较常用!
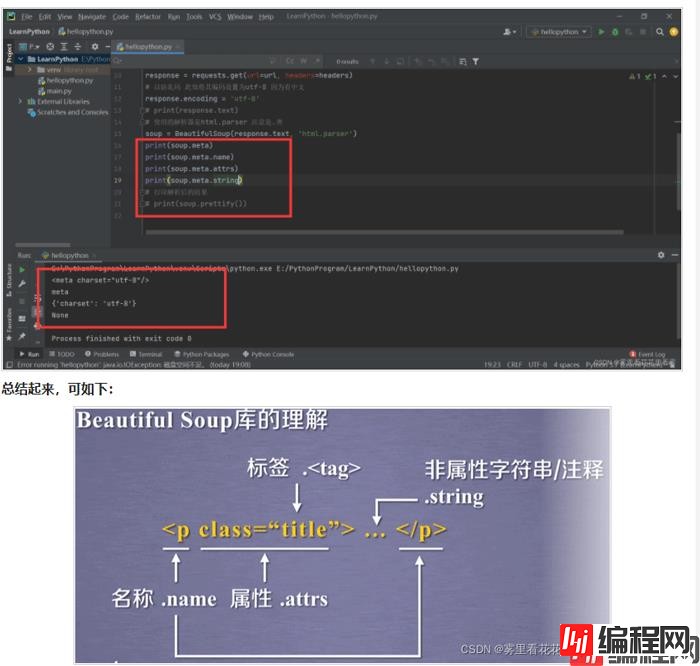
在上述代码的基础上,增加如下几行,结合基本元素的使用,可得到如图所示。
需要注意的是,.string可以跨标签,所以很有可能结果也为注释,为了区分是标签内的字符串还是注释,可以通过打印类型来判断。
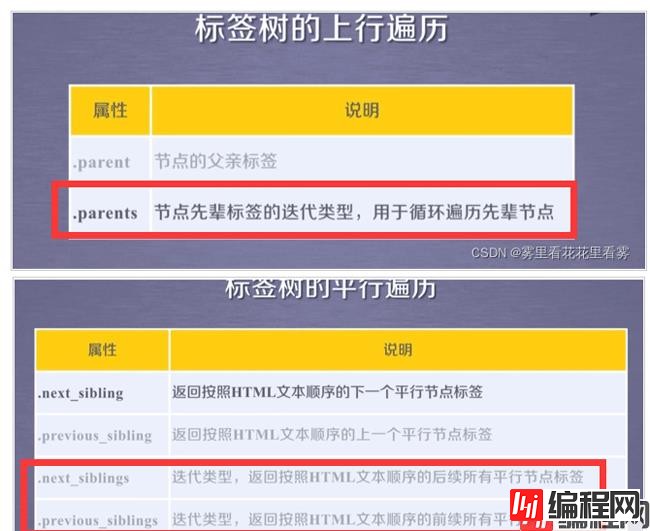
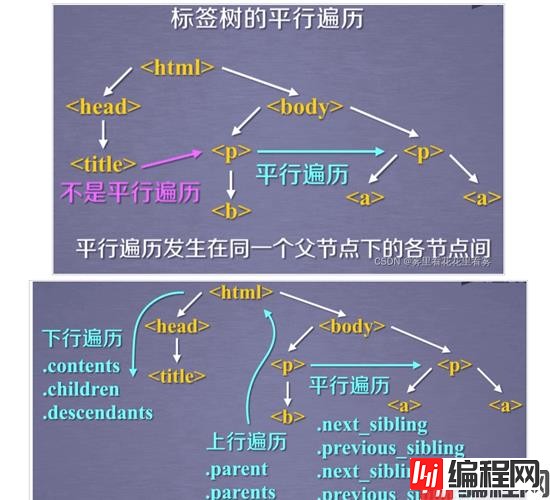
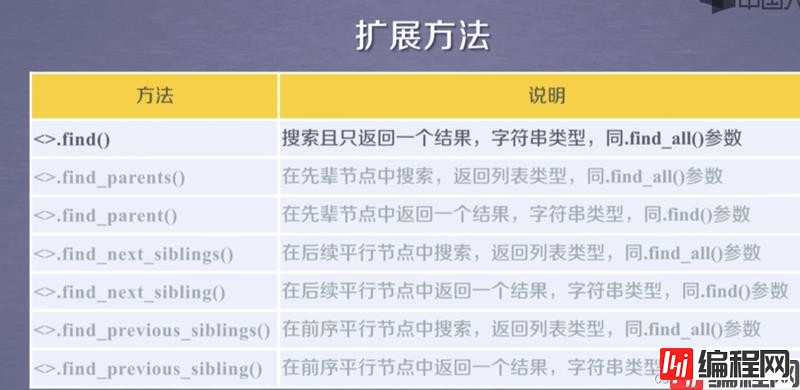
接下来,看一下BeautifulSoup库的遍历,其中画红框的迭代遍历,可以用于for in循环中。
find_all( name , attrs , recursive , string , **kwargs )
find_all() 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件。
name 参数可以对名字为 name 的标签进行检索。
attrs参数可以对标签属性值为attrs的标签进行检索。
recursive参数表示是否对子孙全部检索,默认是TRUE,如果只想搜索当前节点的儿子信息,可以置其为FALSE。
string 参数可以标签中的字符串内容进行检索。
我们学过js的或者java的,应该对Json不陌生吧!
Json是一种有类型的键值对!
需要注意的是,键和值都需要用"“括起来,如果值是整数,则可以不用”"!
如果值是多值,则可以用[,];如果值是键值对,则可以用{:,:,},可以嵌套使用。

JSON一般用于接口,而YAML是无类型键值对,一般用于配置文件。
到此这篇关于基于pycharm的beautifulsoup4库使用方法教程的文章就介绍到这了,更多相关pycharm的beautifulsoup4库使用内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 基于pycharm的beautifulsoup4库使用方法教程
本文链接: https://lsjlt.com/news/162573.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0