Python 官方文档:入门教程 => 点击学习
目录一、前言二、准备工作1.需要用的模块2.驱动安装三、下载歌词四、词云图一、前言 一首歌热门了,参与评论的人也很多,那我们有时候想看看评论,也只能看看热门的评论,大部分人都说的什么
一首歌热门了,参与评论的人也很多,那我们有时候想看看评论,也只能看看热门的评论,大部分人都说的什么,咱也不知道呀~
那本次咱们就把歌词给自动下载保存到电脑上,做成词云图给它分析分析…
本次用到的模块和包:
re # 正则表达式 内置模块
selenium # 实现浏览器自动操作的
jieba # 中文分词库
Wordcloud # 词云图库
imageio # 图像模块
time # 内置模块
需要安装的模块安装方法:
以 selenium 为例,直接pip install selenium
下载速度慢就用镜像源下载
那么要实现浏览器自动操作,咱们得安装一个浏览器驱动。
网址我就不发了,网上直接搜谷歌浏览器驱动就可以找到,实在找不到的话在左侧扫一下,文章看不懂也有视频在左侧扫码。
建议用谷歌浏览器,以谷歌浏览器为例,首先看一下咱们浏览器的的版本。
浏览器右上角三个点,点开后点击设置。
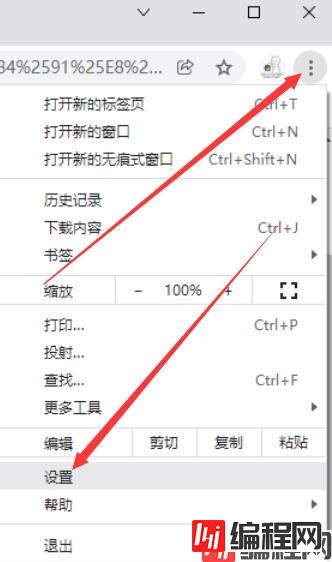
然后点击关于Chrome ,右边的那一串数字就是版本号了。
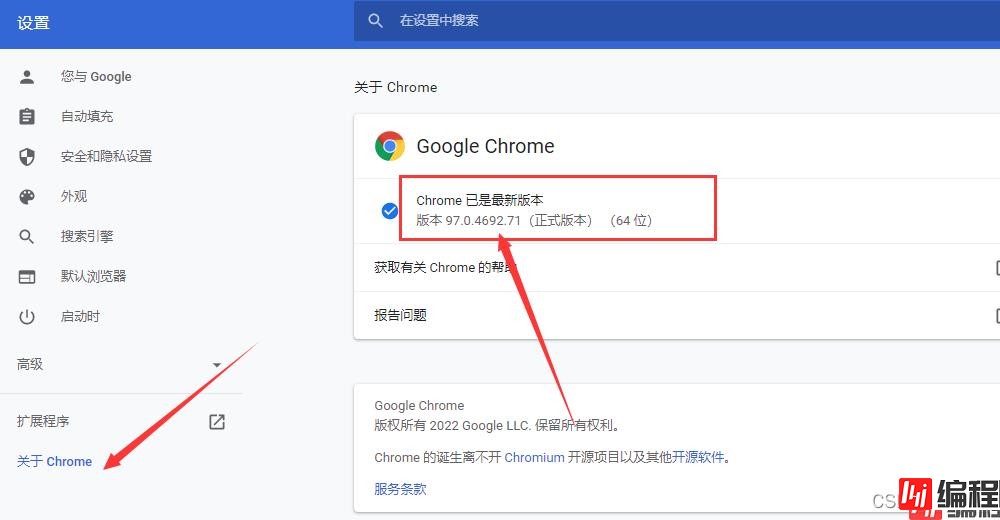
然后找到跟你的版本号相同的版本下载,没有相同的就下载最相近的版本也可以。
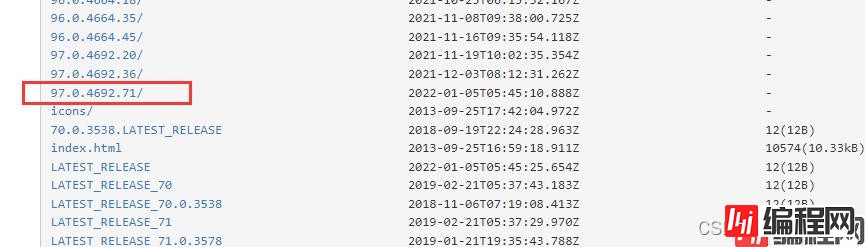
然后把驱动跟你的代码放到一起,跟代码放一起的话,缺点是你每次要使用,没保存的话都得去下载。
还有一种办法是直接放到你的python目录,这种的优点是一次搞定可以用很多次。缺点是每次版本更新,你还是得去下载新的。
我反正每次都是去下载新的,又不是经常用。
先把要用的模块给导入一下
from selenium import WEBdriver
import re
import time
Python文件名或者包名不要命名为selenium,会导致无法导入。
webdriver可以认为是浏览器的驱动器,要驱动浏览器必须用到webdriver,支持多种浏览器。
创建一个浏览器对象
driver = webdriver.Chrome()
请求页面
driver.get('https://music.163.com/#/song?id=569213220')
driver.implicitly_wait(10) # 隐式等待 浏览器渲染页面 智能化等待
driver.maximize_window() # 最大化浏览器
网页嵌套, 进入嵌套网页。
driver.switch_to.frame(0)
下拉页面 js 是一门可以直接运行在浏览器中的语言
# document.documentElement.scrollTop 指定页面的高度
# document.documentElement.scrollHeight 获取页面的高度
# document.documentElement.scrollTop 指定页面的高度
# document.documentElement.scrollHeight 获取页面的高度
js = 'document.documentElement.scrollTop = document.documentElement.scrollHeight'
driver.execute_script(js)
获取评论数据/保存/点击下一页
for click in range(10):
divs = driver.find_elements_by_CSS_selector('.itm')
for div in divs:
cnt = div.find_element_by_css_selector('.cnt.f-brk').text
cnt = cnt.replace('\n', ' ') # 替换换行符
cnt = re.findall(':(.*)', cnt)[0]
with open('contend.txt', mode='a', encoding='utf-8') as f:
f.write(cnt + '\n')
# 找到下一页标签点击
driver.find_element_by_css_selector('.znxt').click()
time.sleep(1)
input('程序阻塞.')
退出浏览器
driver.quit()
来看看效果
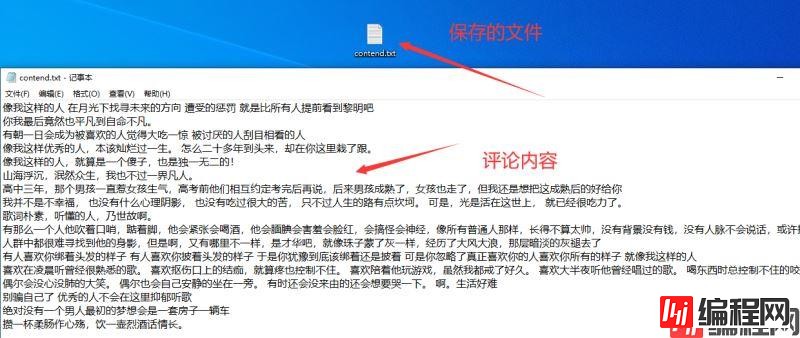
绘制词云图/大小设置
import jieba # 中文分词库
import wordcloud # 词云图库
import imageio # 图像模块
file = open('contend.txt', mode='r', encoding='utf-8')
txt = file.read()
# print(txt)
txt_list = jieba.lcut(txt)
print('分词结果',txt_list)
string = ' '.join(txt_list)
print('合并分词:', string)
"""制作词云图"""
# 读取图像
img = imageio.imread('音乐.png')
# 设置词云图
wc = wordcloud.WordCloud(
width=1000, # 词云图的宽
height=700, # 图片的高
background_color= 'black', # 词云图背景颜色
font_path='msyh.ttc', # 词云字体, 微软雅黑, 系统自带
scale=10, # 字体大小
# mask=img,
stopwords=set([line.strip() for line in open('cn_stopwords.txt', mode='r',
encoding='utf-8').readlines()])
)
print('正在绘制词云图')
wc.generate(string)
wc.to_file('output2.png')
print('词云图制作成功...')
效果展示

到此这篇关于Python控制浏览器自动下载歌词评论并生成词云图的文章就介绍到这了,更多相关Python自动下载歌词评论内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python控制浏览器自动下载歌词评论并生成词云图
本文链接: https://lsjlt.com/news/161995.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0