Python 官方文档:入门教程 => 点击学习
概率论啊概率论,差不多忘完了。 基于概率论的分类方法:朴素贝叶斯 1. 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本章首先介绍贝叶斯分类算法的基础——贝叶斯定理
概率论啊概率论,差不多忘完了。
基于概率论的分类方法:朴素贝叶斯
1. 概述
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。本章首先介绍贝叶斯分类算法的基础——贝叶斯定理。最后,我们通过实例来讨论贝叶斯分类的中最简单的一种: 朴素贝叶斯分类。
2. 贝叶斯理论 & 条件概率
2.1 贝叶斯理论
我们现在有一个数据集,它由两类数据组成,数据分布如下图所示:
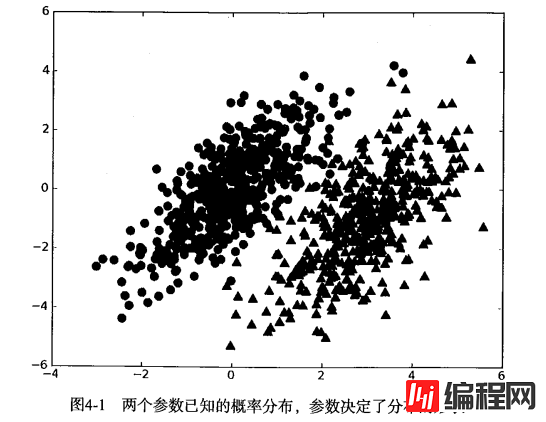
我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示的类别)的概率,用 p2(x,y) 表示数据点 (x,y) 属于类别 2(图中三角形表示的类别)的概率,那么对于一个新数据点 (x,y),可以用下面的规则来判断它的类别:
如果 p1(x,y) > p2(x,y) ,那么类别为1
如果 p2(x,y) > p1(x,y) ,那么类别为2也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
2.1.2 条件概率
如果你对 p(x,y|c1) 符号很熟悉,那么可以跳过本小节。
有一个装了 7 块石头的罐子,其中 3 块是白色的,4 块是黑色的。如果从罐子中随机取出一块石头,那么是白色石头的可能性是多少?由于取石头有 7 种可能,其中 3 种为白色,所以取出白色石头的概率为 3/7 。那么取到黑色石头的概率又是多少呢?很显然,是 4/7 。我们使用 P(white) 来表示取到白色石头的概率,其概率值可以通过白色石头数目除以总的石头数目来得到。
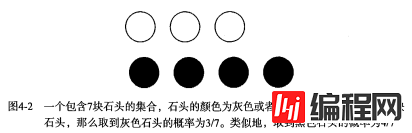
如果这 7 块石头如下图所示,放在两个桶中,那么上述概率应该如何计算?
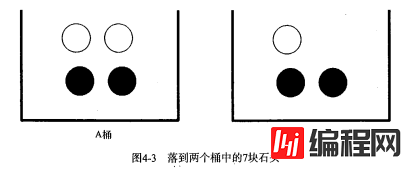
计算 P(white) 或者 P(black) ,如果事先我们知道石头所在桶的信息是会改变结果的。这就是所谓的条件概率(conditional probablity)。假定计算的是从 B 桶取到白色石头的概率,这个概率可以记作 P(white|bucketB) ,我们称之为“在已知石头出自 B 桶的条件下,取出白色石头的概率”。很容易得到,P(white|bucketA) 值为 2/4 ,P(white|bucketB) 的值为 1/3 。
条件概率的计算公式如下:
P(white|bucketB) = P(white and bucketB) / P(bucketB)
首先,我们用 B 桶中白色石头的个数除以两个桶中总的石头数,得到 P(white and bucketB) = 1/7 .其次,由于 B 桶中有 3 块石头,而总石头数为 7 ,于是 P(bucketB) 就等于 3/7 。于是又 P(white|bucketB) = P(white and bucketB) / P(bucketB) = (1/7) / (3/7) = 1/3 。
另外一种有效计算条件概率的方法称为贝叶斯准则。贝叶斯准则告诉我们如何交换条件概率中的条件与结果,即如果已知 P(x|c),要求 P(c|x),那么可以使用下面的计算方法:

使用条件概率来分类
上面我们提到贝叶斯决策理论要求计算两个概率 p1(x, y) 和 p2(x, y):
如果 p1(x, y) > p2(x, y), 那么属于类别 1;
如果 p2(x, y) > p1(X, y), 那么属于类别 2.这并不是贝叶斯决策理论的所有内容。使用 p1() 和 p2() 只是为了尽可能简化描述,而真正需要计算和比较的是 p(c1|x, y) 和 p(c2|x, y) .这些符号所代表的具体意义是: 给定某个由 x、y 表示的数据点,那么该数据点来自类别 c1 的概率是多少?数据点来自类别 c2 的概率又是多少?注意这些概率与概率 p(x, y|c1) 并不一样,不过可以使用贝叶斯准则来交换概率中条件与结果。具体地,应用贝叶斯准则得到:

使用上面这些定义,可以定义贝叶斯分类准则为:
如果 P(c1|x, y) > P(c2|x, y), 那么属于类别 c1;
如果 P(c2|x, y) > P(c1|x, y), 那么属于类别 c2.在文档分类中,整个文档(如一封电子邮件)是实例,而电子邮件中的某些元素则构成特征。我们可以观察文档中出现的词,并把每个词作为一个特征,而每个词的出现或者不出现作为该特征的值,这样得到的特征数目就会跟词汇表中的词的数目一样多。
我们假设特征之间 相互独立 。所谓 独立(independence) 指的是统计意义上的独立,即一个特征或者单词出现的可能性与它和其他单词相邻没有关系,比如说,“我们”中的“我”和“们”出现的概率与这两个字相邻没有任何关系。这个假设正是朴素贝叶斯分类器中 朴素(naive) 一词的含义。朴素贝叶斯分类器中的另一个假设是,每个特征同等重要。
Note: 朴素贝叶斯分类器通常有两种实现方式: 一种基于伯努利模型实现,一种基于多项式模型实现。这里采用前一种实现方式。该实现方式中并不考虑词在文档中出现的次数,只考虑出不出现,因此在这个意义上相当于假设词是等权重的。
2.2 朴素贝叶斯场景
机器学习的一个重要应用就是文档的自动分类。
在文档分类中,整个文档(如一封电子邮件)是实例,而电子邮件中的某些元素则构成特征。我们可以观察文档中出现的词,并把每个词作为一个特征,而每个词的出现或者不出现作为该特征的值,这样得到的特征数目就会跟词汇表中的词的数目一样多。
朴素贝叶斯是上面介绍的贝叶斯分类器的一个扩展,是用于文档分类的常用算法。下面我们会进行一些朴素贝叶斯分类的实践项目。
2.3 朴素贝叶斯 原理
朴素贝叶斯 工作原理
提取所有文档中的词条并进行去重
获取文档的所有类别
计算每个类别中的文档数目
对每篇训练文档:
对每个类别:
如果词条出现在文档中-->增加该词条的计数值(for循环或者矩阵相加)
增加所有词条的计数值(此类别下词条总数)
对每个类别:
对每个词条:
将该词条的数目除以总词条数目得到的条件概率(P(词条|类别))
返回该文档属于每个类别的条件概率(P(类别|文档的所有词条))
2.4 朴素贝叶斯开发流程
收集数据: 可以使用任何方法。
准备数据: 需要数值型或者布尔型数据。
分析数据: 有大量特征时,绘制特征作用不大,此时使用直方图效果更好。
训练算法: 计算不同的独立特征的条件概率。
测试算法: 计算错误率。
使用算法: 一个常见的朴素贝叶斯应用是文档分类。可以在任意的分类场景中使用朴素贝叶斯分类器,不一定非要是文本。
2.5 朴素贝叶斯算法特点
优点: 在数据较少的情况下仍然有效,可以处理多类别问题。
缺点: 对于输入数据的准备方式较为敏感。
适用数据类型: 标称型数据。
2.6 朴素贝叶斯 项目案例
2.6.1 项目案例1
屏蔽社区留言板的侮辱性言论
2.6.1.1 项目概述
构建一个快速过滤器来屏蔽在线社区留言板上的侮辱性言论。如果某条留言使用了负面或者侮辱性的语言,那么就将该留言标识为内容不当。对此问题建立两个类别: 侮辱类和非侮辱类,使用 1 和 0 分别表示。
2.6.1.2 开发流程
收集数据: 可以使用任何方法
准备数据: 从文本中构建词向量
分析数据: 检查词条确保解析的正确性
训练算法: 从词向量计算概率
测试算法: 根据现实情况修改分类器
使用算法: 对社区留言板言论进行分类
收集数据: 可以使用任何方法
2.6.1.3 构造词表
def loadDataSet():
"""
创建数据集
:return: 单词列表postingList, 所属类别classVec
"""
postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], #[0,0,1,1,1......]
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0, 1, 0, 1, 0, 1] # 1 is abusive, 0 not
return postingList, classVec2.6.1.4 准备数据: 从文本中构建词向量
def createVocabList(dataSet):
"""
获取所有单词的集合
:param dataSet: 数据集
:return: 所有单词的集合(即不含重复元素的单词列表)
"""
vocabSet = set([]) # create empty set
for document in dataSet:
# 操作符 | 用于求两个集合的并集
vocabSet = vocabSet | set(document) # uNIOn of the two sets
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
"""
遍历查看该单词是否出现,出现该单词则将该单词置1
:param vocabList: 所有单词集合列表
:param inputSet: 输入数据集
:return: 匹配列表[0,1,0,1...],其中 1与0 表示词汇表中的单词是否出现在输入的数据集中
"""
# 创建一个和词汇表等长的向量,并将其元素都设置为0
returnVec = [0] * len(vocabList)# [0,0......]
# 遍历文档中的所有单词,如果出现了词汇表中的单词,则将输出的文档向量中的对应值设为1
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print "the word: %s is not in my Vocabulary!" % word
return returnVec2.6.1.5 分析数据: 检查词条确保解析的正确性
检查函数执行情况,检查词表,不出现重复单词,需要的话,可以对其进行排序。
>>> listOPosts, listClasses = bayes.loadDataSet()
>>> myVocabList = bayes.createVocabList(listOPosts)
>>> myVocabList
['cute', 'love', 'help', 'garbage', 'quit', 'I', 'problems', 'is', 'park',
'stop', 'flea', 'dalmation', 'licks', 'food', 'not', 'him', 'buying', 'posting', 'has', 'worthless', 'ate', 'to', 'maybe', 'please', 'dog', 'how',
'stupid', 'so', 'take', 'mr', 'steak', 'my']检查函数有效性。例如:myVocabList 中索引为 2 的元素是什么单词?应该是是 help 。该单词在第一篇文档中出现了,现在检查一下看看它是否出现在第四篇文档中。
>>> bayes.setOfWords2Vec(myVocabList, listOPosts[0])
[0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1]
>>> bayes.setOfWords2Vec(myVocabList, listOPosts[3])
[0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0]2.6.1.6 训练算法: 从词向量计算概率
现在已经知道了一个词是否出现在一篇文档中,也知道该文档所属的类别。接下来我们重写贝叶斯准则,将之前的 x, y 替换为 w. 粗体的 w 表示这是一个向量,即它由多个值组成。在这个例子中,数值个数与词汇表中的词个数相同。

我们使用上述公式,对每个类计算该值,然后比较这两个概率值的大小。
首先可以通过类别 i (侮辱性留言或者非侮辱性留言)中的文档数除以总的文档数来计算概率 p(ci) 。接下来计算 p(w | ci) ,这里就要用到朴素贝叶斯假设。如果将 w 展开为一个个独立特征,那么就可以将上述概率写作 p(w0, w1, w2…wn | ci) 。这里假设所有词都互相独立,该假设也称作条件独立性假设(例如 A 和 B 两个人抛骰子,概率是互不影响的,也就是相互独立的,A 抛 2点的同时 B 抛 3 点的概率就是 1/6 * 1/6),它意味着可以使用 p(w0 | ci)p(w1 | ci)p(w2 | ci)…p(wn | ci) 来计算上述概率,这样就极大地简化了计算的过程。
2.6.1.7 朴素贝叶斯分类器训练函数
def _trainNB0(trainMatrix, trainCateGory):
"""
训练数据原版
:param trainMatrix: 文件单词矩阵 [[1,0,1,1,1....],[],[]...]
:param trainCategory: 文件对应的类别[0,1,1,0....],列表长度等于单词矩阵数,其中的1代表对应的文件是侮辱性文件,0代表不是侮辱性矩阵
:return:
"""
# 文件数
numTrainDocs = len(trainMatrix)
# 单词数
numWords = len(trainMatrix[0])
# 侮辱性文件的出现概率,即trainCategory中所有的1的个数,
# 代表的就是多少个侮辱性文件,与文件的总数相除就得到了侮辱性文件的出现概率
pAbusive = sum(trainCategory) / float(numTrainDocs)
# 构造单词出现次数列表
p0Num = zeros(numWords) # [0,0,0,.....]
p1Num = zeros(numWords) # [0,0,0,.....]
# 整个数据集单词出现总数
p0Denom = 0.0
p1Denom = 0.0
for i in range(numTrainDocs):
# 是否是侮辱性文件
if trainCategory[i] == 1:
# 如果是侮辱性文件,对侮辱性文件的向量进行加和
p1Num += trainMatrix[i] #[0,1,1,....] + [0,1,1,....]->[0,2,2,...]
# 对向量中的所有元素进行求和,也就是计算所有侮辱性文件中出现的单词总数
p1Denom += sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Denom += sum(trainMatrix[i])
# 类别1,即侮辱性文档的[P(F1|C1),P(F2|C1),P(F3|C1),P(F4|C1),P(F5|C1)....]列表
# 即 在1类别下,每个单词出现的概率
p1Vect = p1Num / p1Denom# [1,2,3,5]/90->[1/90,...]
# 类别0,即正常文档的[P(F1|C0),P(F2|C0),P(F3|C0),P(F4|C0),P(F5|C0)....]列表
# 即 在0类别下,每个单词出现的概率
p0Vect = p0Num / p0Denom
return p0Vect, p1Vect, pAbusive总结
以上就是本文关于python编程之基于概率论的分类方法:朴素贝叶斯的全部内容,希望对大家有所帮助。感兴趣的朋友可以参阅本站:Python内存管理方式和垃圾回收算法解析、Python基础练习之几个简单的游戏、python使用邻接矩阵构造图代码示例等,有什么问题可以随时留言,小编会及时回复大家的。感谢朋友们对编程网网站的支持!
--结束END--
本文标题: Python编程之基于概率论的分类方法:朴素贝叶斯
本文链接: https://lsjlt.com/news/16119.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0