目录MyISAM和InnoDB性能下降sql慢的原因:Mysql执行顺序SQLJoin索引索引的优劣1.优势2.劣势索引分类创建删除查看mysql索引结构那些情况建索引哪些情况不要建
| 对比 | MyISAM | InnoDB |
|---|---|---|
| 主外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 行表锁 | 表锁,操作时即使操作一条记录也会锁住一整张表,不适合高并发的操作 | 行锁,操作时只锁住某一行,不会影响到其他行,适合高并发 |
| 缓存 | 只缓存索引,不缓存其他数据 | 缓存索引和真实数据,对内存要求较高,而且内存大小对性能有影响 |
| 表空间 | 小 | 大 |
| 关注点 | 性能 | 事务 |
| 默认安装 | Y | Y |



a表
mysql> select * from tbl_dept;
+----+----------+--------+
| id | deptName | locAdd |
+----+----------+--------+
| 1 | RD | 11 |
| 2 | HR | 12 |
| 3 | MK | 13 |
| 4 | MIS | 14 |
| 5 | FD | 15 |
+----+----------+--------+
5 rows in set (0.00 sec)b表
+----+------+--------+
| id | name | deptId |
+----+------+--------+
| 1 | z3 | 1 |
| 2 | z4 | 1 |
| 3 | z5 | 1 |
| 4 | w5 | 2 |
| 5 | w6 | 2 |
| 6 | s7 | 3 |
| 7 | s8 | 4 |
| 8 | s9 | 51 |
+----+------+--------+
8 rows in set (0.00 sec)mysql不支持全连接
使用以下方式可以实现全连接
mysql> select * from tbl_dept a right join tbl_emp b on a.id=b.deptId
-> uNIOn
-> select * from tbl_dept a left join tbl_emp b on a.id=b.deptId;
+------+----------+--------+------+------+--------+
| id | deptName | locAdd | id | name | deptId |
+------+----------+--------+------+------+--------+
| 1 | RD | 11 | 1 | z3 | 1 |
| 1 | RD | 11 | 2 | z4 | 1 |
| 1 | RD | 11 | 3 | z5 | 1 |
| 2 | HR | 12 | 4 | w5 | 2 |
| 2 | HR | 12 | 5 | w6 | 2 |
| 3 | MK | 13 | 6 | s7 | 3 |
| 4 | MIS | 14 | 7 | s8 | 4 |
| NULL | NULL | NULL | 8 | s9 | 51 |
| 5 | FD | 15 | NULL | NULL | NULL |
+------+----------+--------+------+------+--------+
9 rows in set (0.00 sec)a的独有和b的独有
mysql> select * from tbl_dept a left join tbl_emp b on a.id=b.deptId where b.id is null -> union -> select * from tbl_dept a right join tbl_emp b on a.id=b.deptId where a.id is null; +------+----------+--------+------+------+--------+ | id | deptName | locAdd | id | name | deptId | +------+----------+--------+------+------+--------+ | 5 | FD | 15 | NULL | NULL | NULL | | NULL | NULL | NULL | 8 | s9 | 51 | +------+----------+--------+------+------+--------+ 2 rows in set (0.01 sec)
索引的定义:
索引是帮助SQL高效获取数据的数据结构,索引的本质:数据结构
可以简单的理解为:排好序的快速查找数据结构
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式(引用)指向数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引,下图就是一种示例:

一般来说索引也很大,因此索引往往以索引文件的方式存储在磁盘上
我们平常所说的索引,如果没有特别指明,一般都是指B树(多路搜索树,不一定是二叉的)结构组织的索引,
其中聚集索引,次要索引,复合索引,前缀索引,唯一索引默认都是使用B+树索引,统称索引,当然除了B+树这种类型的索引之外,还有哈希索引。
类似大学图书馆图书编号建索引,提高了数据检索的效率,降低数据库的IO成本
通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗
实际上索引也是一张表,该表保存了主键与存在索引的字段,并指向实体表的记录,所以索引列也是占用空间的
虽然索引大大提高了查询速度,但是会降低更新表的速度,比如 update,insert,delete操作,因为更新表时,MySQL不仅要数据也要保存索引文件每次更新添加了索引的字段,都会调整因为更新所带来的键值变化后的索引信息
索引只是提高效率的一个因素,在一个大数据量的表上,需要建立最为优秀的索引或者写优秀的查询语句,而不是加了索引就能提高效率
create [unique] index indexName on mytable(cloumnname(length));
alter mytable add [unique] index [indexName] on (columnname(length));
drop index [indexName] on mytable
show index from table_name\G有四种方式来添加数据表的索引




explian重点

type显示的是访问类型排列,是较为重要的一个指标

从最好到最差依次是:
system > const > eq_ref> ref > range > index > ALL;
一般来说,得保证查询至少达到range级别,最好ref
----------------------------------------------type类型-------------------------------------------------------
----------------------------------------------type类型-------------------------------------------------------
key_len长度:13是因为char(4)*utf8(3)+允许为null(1)=13


没建立索引时查询t1 t2表 t1表对应t2表的id t2表 col1的值要为'ac'
对于Id这个字段t1表对t2表相当于 一对多
t1表的type为 eq_ref代表唯一性索引扫描,表中只有一条记录与之匹配,t2表对应t1的这个id对应的col值只有一个,根据t2表的主键id索引查询,t1表读取了一行,t2表读取了640行
建立索引后

t1读取一行,t2读取142行,ref非唯一性索引扫描,返回匹配某个单独值的所有行,返回t2对应id的col所有行,而t1对应id的col只有一行,所以type为eq_ref
包含不适合在其他列展现但十分重要的信息
\G :竖直显示排序


案例

CREATE TABLE IF NOT EXISTS `article`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`author_id` INT (10) UNSIGNED NOT NULL,
`cateGory_id` INT(10) UNSIGNED NOT NULL ,
`views` INT(10) UNSIGNED NOT NULL ,
`comments` INT(10) UNSIGNED NOT NULL,
`title` VARBINARY(255) NOT NULL,
`content` TEXT NOT NULL
);
INSERT INTO `article`(`author_id`,`category_id` ,`views` ,`comments` ,`title` ,`content` )VALUES
(1,1,1,1,'1','1'),
(2,2,2,2,'2','2'),
(1,1,3,3,'3','3');
SELECT * FROM ARTICLE;
mysql> select id,author_id from article where category_id = 1 and comments > 1 order by views desc limit 1;
+----+-----------+
| id | author_id |
+----+-----------+
| 3 | 1 |
+----+-----------+
1 row in set (0.00 sec)
mysql> explain select author_id from article where category_id = 1 and comments > 1 order by views desc li
imit 1;
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
| 1 | SIMPLE | article | NULL | ALL | NULL | NULL | NULL | NULL | 3 | 33.33 | Using where; Using filesort |
+----+-------------+---------+------------+------+---------------+------+---------+------+------+----------+-----------------------------+
1 row in set, 1 warning (0.00 sec)可以看出虽然查询出来了 但是 type是all,Extra里面出现了using filesort证明查询效率很低
需要优化
建立索引
create index idx_article_ccv on article(category_id,comments,views);查询
mysql> explain select author_id from article where category_id = 1 and comments > 1 order by views desc limit 1;
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+
| 1 | SIMPLE | article | NULL | range | inx_article_ccv | inx_article_ccv | 8 | NULL | 1 | 100.00 | Using index condition; Using filesort |
+----+-------------+---------+------------+-------+-----------------+-----------------+---------+------+------+----------+---------------------------------------+
1 row in set, 1 warning (0.00 sec)这里发现type 变为了 range 查询全表变为了 范围查询 优化了一点
但是 extra 仍然 有 using filesort 证明 索引优化并不成功

所以我们删除索引
drop index idx_article_ccv on article;建立新的索引,排除掉range
create index idx_article_cv on article(category_id,views);
mysql> explain select author_id from article where category_id = 1 and comments > 1 order by views desc limit 1;
+----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | article | NULL | ref | idx_article_cv | idx_article_cv | 4 | const | 2 | 33.33 | Using where |
+----+-------------+---------+------------+------+----------------+----------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
这时候会发现 优化成功 type 变为了ref extra变为了 using where
在这次实验中我又加入了一次试验 发现当建立索引时comments放在最后也是可行的
mysql> create index idx_article_cvc on article(category_id,views,comments);
Query OK, 0 rows affected (0.02 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> explain select author_id from article where category_id = 1 and comments > 1 order by views desc limit 1;
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | article | NULL | ref | idx_article_cvc | idx_article_cvc | 4 | const | 2 | 33.33 | Using where |
+----+-------------+---------+------------+------+-----------------+-----------------+---------+-------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)这时候会发现 优化成功 type 变为了ref extra变为了 using where
在这次实验中我又加入了一次试验 发现当建立索引时comments放在最后也是可行的
这里发现了 type仍然是ref,extra也是usingwhere,而只是把索引建立的位置换了一换,把范围查询的字段挪到了最后!!!!
CREATE TABLE IF NOT EXISTS `class`(
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`card` INT (10) UNSIGNED NOT NULL
);
CREATE TABLE IF NOT EXISTS `book`(
`bookid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`card` INT (10) UNSIGNED NOT NULL
);
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO class(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO book(card)VALUES(FLOOR(1+(RAND()*20)));
mysql> create index Y on book(card);
explain select * from book left join class on book.card=class.card;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | book | NULL | index | NULL | Y | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
2 rows in set, 1 warning (0.00 sec)会发现并无多大区别 还是全表查询 这是因为俩表查询左连接把左表必须全查询 这时候只有对右表建立索引才有用
相反的右链接必须对左表建立索引才有用
对右表建立索引
create index Y on class;
explain select * from book left join class on book.card=class.card;
+----+-------------+-------+------------+-------+---------------+------+---------+----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------+------+----------+-------------+
| 1 | SIMPLE | book | NULL | index | NULL | Y | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | class | NULL | ref | Y | Y | 4 | db01.book.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------+---------+----------------+------+----------+-------------+
2 rows in set, 1 warning (0.00 sec)会发现 右表只查询了一次。。type为ref
CREATE TABLE IF NOT EXISTS `phone`(
`phoneid` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`card` INT (10) UNSIGNED NOT NULL
)ENGINE = INNODB;
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));
INSERT INTO phone(card)VALUES(FLOOR(1+(RAND()*20)));先删除所有索引
drop index Y on book;
drop index Y on class;
explain select * from class left join book on class.card=book.card left join phone on book.card=phone.card;
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
| 1 | SIMPLE | phone | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | Using where; Using join buffer (Block Nested Loop) |
+----+-------------+-------+------------+------+---------------+------+---------+------+------+----------+----------------------------------------------------+
3 rows in set, 1 warning (0.00 sec)建立索引
create index y on book(card);
create index z on phone(card);
explain select * from class left join book on class.card=book.card left join phone on book.card=phone.card;
+----+-------------+-------+------------+------+---------------+------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | class | NULL | ALL | NULL | NULL | NULL | NULL | 20 | 100.00 | NULL |
| 1 | SIMPLE | book | NULL | ref | y | y | 4 | db01.class.card | 1 | 100.00 | Using index |
| 1 | SIMPLE | phone | NULL | ref | z | z | 4 | db01.book.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+------+---------------+------+---------+-----------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)会发现索引建立的非常成功。。 但是left join 最左表必须全部查询 建立索引
create index x on class(card);
explain select * from class left join book on class.card=book.card left join phone on book.card=phone.card;
+----+-------------+-------+------------+-------+---------------+------+---------+-----------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+-----------------+------+----------+-------------+
| 1 | SIMPLE | class | NULL | index | NULL | x | 4 | NULL | 20 | 100.00 | Using index |
| 1 | SIMPLE | book | NULL | ref | y | y | 4 | db01.class.card | 1 | 100.00 | Using index |
| 1 | SIMPLE | phone | NULL | ref | z | z | 4 | db01.book.card | 1 | 100.00 | Using index |
+----+-------------+-------+------------+-------+---------------+------+---------+-----------------+------+----------+-------------+
3 rows in set, 1 warning (0.00 sec)结果仍然一样
建立表
CREATE TABLE staffs(
id INT PRIMARY KEY AUTO_INCREMENT,
`name` VARCHAR(24)NOT NULL DEFAULT'' COMMENT'姓名',
`age` INT NOT NULL DEFAULT 0 COMMENT'年龄',
`pos` VARCHAR(20) NOT NULL DEFAULT'' COMMENT'职位',
`add_time` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT'入职时间'
)CHARSET utf8 COMMENT'员工记录表';
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('z3',22,'manager',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('July',23,'dev',NOW());
INSERT INTO staffs(`name`,`age`,`pos`,`add_time`) VALUES('2000',23,'dev',NOW());
建立索引
ALTER TABLE staffs ADD INDEX index_staffs_nameAgePos(`name`,`age`,`pos`);
可以从上图看出 跳过name的都用不了索引
mysql> explain select * from staffs where name='july';
+----+-------------+--------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-------+
| 1 | SIMPLE | staffs | NULL | ref | index_staffs_nameAgePos | index_staffs_nameAgePos | 74 | const | 1 | 100.00 | NULL |
+----+-------------+--------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)
mysql> explain select * from staffs where name='july' and pos='dev';
+----+-------------+--------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-----------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+--------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-----------------------+
| 1 | SIMPLE | staffs | NULL | ref | index_staffs_nameAgePos | index_staffs_nameAgePos | 74 | const | 1 | 33.33 | Using index condition |
+----+-------------+--------+------------+------+-------------------------+-------------------------+---------+-------+------+----------+-----------------------+
1 row in set, 1 warning (0.00 sec)可以从语句中看出跳过中间的索引后 key_len 不变 证明第索引pos没有被用到
假设index(a,b,c)
Y代表索引全部使用了 N全没使用
| where语句 | 索引是否被使用 |
|---|---|
| where a=3 and c=5 | (中间b断掉了)使用了a 没使用c |
| where a=3 and b=4 andc=5 | Y |
| where a=3 and c=5 and b=4 | Y这里mysql自动做了优化对语句排序 |
| where a=3 and b>4 and c=5 | a,b被使用 |
| where a=3 and b like 'k%' and c=5 | Y like后面常量开头索引全用 |
| where b=3 and c=4 | N |
| where a=3 and c>5 and b=4 | Y:mysql自动做了优化对语句排序 范围c之后索引才会失效 |
| where b=3 and c=4 and a=2 | Y :mysql自动做了优化对语句排序 |
| where c=5 and b=4 and a=3 | Y :mysql自动做了优化对语句排序 |
假设index(a,b,c, d)
create table test03(
id int primary key not null auto_increment,
a int(10),
b int(10),
c int(10),
d int(10),
insert into test03(a,b,c,d) values (3,4,5,6);
insert into test03(a,b,c,d) values (3,4,5,6);
insert into test03(a,b,c,d) values (3,4,5,6);
insert into test03(a,b,c,d) values (3,4,5,6);
create index idx_test03_abcd on test03(a,b,c,d);###
| where a=3 and b>4 and c=5 | 使用了a和b ,b后面的索引全失效 |
|---|---|
| where a=3 and b=4 and d=6 order by c | 使用了a和b,c其实也用了但是是用在排序,没有统计到mysql中 |
| where a=3 and b=4 order by c | 使用了a和b,c其实也用了但是是用在排序,没有统计到mysql中 |
| where a=3 and b=4 order by d | 使用了a和b, 这里跳过c 会导致using filesort |
| where a=3 and d=6 order by b ,c | 使用了a, 排序用到了b,c索引 |
| where a=3 and d=6 order by c ,b | 使用了 a,会产生using filesort,因为跳过了b对c进行排序 |
| where a=3 and b=4 order by b ,c | Y 全使用 |
| where a=3 and b=4 and d&##61;6 order by c , b | 使用了a,b,不会产生using filesort 因为在对c,b排序前对b进行了查询,查询时b已经确定了(常量),这样就没有跳过b对c进行排序了,而是相当于直接对c排序 相当于第三格的查询语句 |
group by 更严重group by先分组再排序 把order by换为 group by 甚至会产生using temporary,与order by差不多,但是更严重 而且与group by产生的效果差不多就不做演示了
| orderBy 条件 | Extra |
|---|---|
| where a>4 order by a | using where using index |
| where a>4 order by a,b | using where using index |
| where a>4 order by b | using where, using index ,using filesort(order by 后面带头大哥不在) |
| where a>4 order by b,a | using where, using index ,using filesort(order by 后面顺序) |
| where a=const order by b,c | 如果where使用索引的最左前缀定义为常量,则order by能使用索引 |
| where a=const and b=const order by c | where使用索引的最左前缀定义为常量,则order by能使用索引 |
| where a=const and b>3 order by b c | using where using index |
| order by a asc, b desc ,c desc | 排序不一致 升降机 |


select a.* from A a where exists(select 1 from B b where a.id=b.id)
以上查询使用了exists语句,exists()会执行A.length次,它并不缓存exists()结果集,因为exists()结果集的内容并不重要,重要的是结果集中是否有记录,如果有则返回true,没有则返回false. 它的查询过程类似于以下过程
List resultSet=[]; Array A=(select * from A)
for(int i=0;i<A.length;i++) { if(exists(A[i].id) { //执行select 1 from B b where b.id=a.id是否有记录返回 resultSet.add(A[i]); } } return resultSet;
当B表比A表数据大时适合使用exists(),因为它没有那么遍历操作,只需要再执行一次查询就行. 如:A表有10000条记录,B表有1000000条记录,那么exists()会执行10000次去判断A表中的id是否与B表中的id相等. 如:A表有10000条记录,B表有100000000条记录,那么exists()还是执行10000次,因为它只执行A.length次,可见B表数据越多,越适合exists()发挥效果. 再如:A表有10000条记录,B表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历比较,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快.
show VARIABLES like '%slow_query_log%';显示是否开启mysql慢查询日志
set global slow_query_log=0;关闭mysql慢查询日志
set global slow_query_log=1;开启mysql慢查询日志
show VARIABLES like '%long_query_time%';显示超过多长时间即为 慢查询
set global long_quert_time=10;修改慢查询时间为10秒,当查询语句时间超过10秒即为慢查询
show global status like '%Slow_queries%';显示一共有几条慢查询语句
[root@iZ0jlh1zn42cgftmrf6p6sZ data]# cat mysql-slow.loglinux查询慢sql
CREATE TABLE dept(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,
dname VARCHAR(20) NOT NULL DEFAULT '',
loc VARCHAR(13) NOT NULL DEFAULT ''
)ENGINE=INNODB DEFAULT CHARSET=GBK;
CREATE TABLE emp(
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, #编号
enname VARCHAR(20) NOT NULL DEFAULT '', #名字
job VARCHAR(9) NOT NULL DEFAULT '', #工作
mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, #上级编号
hiredate DATE NOT NULL, #入职时间
sal DECIMAL(7,2) NOT NULL, #薪水
comm DECIMAL(7,2) NOT NULL, #红利
deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 #部门编号
)ENGINE=INNODB DEFAULT CHARSET=GBK;
show variables like 'log_bin_trust_function_creators';
set global log_bin_trust_function_creators=1;创建函数:随机产生部门编号 随机产生字符串
DELIMITER $$是因为sql都是;进行结尾但是创建函数过程要多次使用;所以改变sql执行结束的条件为输入$$,相当于代替了分号' ;'
//定义函数1
DELIMITER $$
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_set VARCHAR(100) DEFAULT 'abcdefghigklmnopqrstuvwxyzABCDEFGHIGKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str = CONCAT(return_str,SUBSTRING(chars_set,FLOOR(1 + RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
//定义函数2
DELIMITER $$
CREATE FUNCTION rand_num() RETURNS INT(5)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(100 + RAND()*10);
RETURN i;
END $$
//定义存储过程1
DELIMITER $$
CREATE PROCEDURE insert_emp(IN start INT(10), IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO emp(empno, enname, job, mgr, hiredate, sal, comm, deptno) VALUES((start + i),rand_string(6),'SALESMAN',0001,CURDATE(),2000,400,rand_num());
UNTIL i = max_num
END REPEAT;
COMMIT;
END $$
//定义存储过程2
DELIMITER $$
CREATE PROCEDURE insert_dept(IN start INT(10), IN max_num INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO dept(deptno,dname,loc) VALUES((start + i),rand_string(10),rand_string(8));
UNTIL i = max_num
END REPEAT;
COMMIT;
END $$
//开始插入数据
DELIMITER ;
call insert_dept(100,10);
call insert_emp(100001,500000);
mysql> show variables like 'profiling';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| profiling | OFF |
+---------------+-------+
1 row in set (0.00 sec)
mysql> set profiling=on;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show variables like 'profiling';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| profiling | ON |
+---------------+-------+
1 row in set (0.01 sec)随便写几条插入语句‘
显示查询操作语句的速度
mysql> show profiles;
+----------+------------+----------------------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+----------------------------------------------------------------+
| 1 | 0.00125325 | show variables like 'profiling' |
| 2 | 0.00018850 | select * from dept |
| 3 | 0.00016825 | select * from tb1_emp e inner join tbl_dept d on e.deptId=d.id |
| 4 | 0.00023900 | show tables |
| 5 | 0.00031125 | select * from tbl_emp e inner join tbl_dept d on e.deptId=d.id |
| 6 | 0.00024775 | select * from tbl_emp e inner join tbl_dept d on e.deptId=d.id |
| 7 | 0.00023725 | select * from tbl_emp e inner join tbl_dept d on e.deptId=d.id |
| 8 | 0.00023825 | select * from tbl_emp e left join tbl_dept d on e.deptId=d.id |
| 9 | 0.35058075 | select * from emp group by id%10 limit 15000 |
| 10 | 0.35542250 | select * from emp group by id%10 limit 15000 |
| 11 | 0.00024550 | select * from tbl_emp e left join tbl_dept d on e.deptId=d.id |
| 12 | 0.36441850 | select * from emp group by id%20 order by 5 |
+----------+------------+----------------------------------------------------------------+
12 rows in set, 1 warning (0.00 sec)显示查询过程 sql生命周期
mysql> show profile cpu,block io for query 3;
+----------------------+----------+----------+------------+--------------+---------------+
| Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out |
+----------------------+----------+----------+------------+--------------+---------------+
| starting | 0.000062 | 0.000040 | 0.000021 | 0 | 0 |
| checking permissions | 0.000004 | 0.000003 | 0.000001 | 0 | 0 |
| checking permissions | 0.000015 | 0.000006 | 0.000003 | 0 | 0 |
| Opening tables | 0.000059 | 0.000039 | 0.000020 | 0 | 0 |
| query end | 0.000004 | 0.000002 | 0.000001 | 0 | 0 |
| closing tables | 0.000002 | 0.000001 | 0.000000 | 0 | 0 |
| freeing items | 0.000014 | 0.000010 | 0.000005 | 0 | 0 |
| cleaning up | 0.000009 | 0.000006 | 0.000003 | 0 | 0 |
+----------------------+----------+----------+------------+--------------+---------------+
8 rows in set, 1 warning (0.00 sec)
mysql> show profile cpu,block io for query 12;
+----------------------+----------+----------+------------+--------------+---------------+
| Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out |
+----------------------+----------+----------+------------+--------------+---------------+
| starting | 0.000063 | 0.000042 | 0.000021 | 0 | 0 |
| checking permissions | 0.000006 | 0.000003 | 0.000002 | 0 | 0 |
| Opening tables | 0.000013 | 0.000009 | 0.000004 | 0 | 0 |
| init | 0.000028 | 0.000017 | 0.000008 | 0 | 0 |
| System lock | 0.000007 | 0.000004 | 0.000002 | 0 | 0 |
| optimizing | 0.000004 | 0.000002 | 0.000002 | 0 | 0 |
| statistics | 0.000014 | 0.000010 | 0.000004 | 0 | 0 |
| preparing | 0.000008 | 0.000005 | 0.000003 | 0 | 0 |
| Creating tmp table | 0.000028 | 0.000018 | 0.000009 | 0 | 0 |
| Sorting result | 0.000003 | 0.000002 | 0.000001 | 0 | 0 |
| executing | 0.000002 | 0.000002 | 0.000001 | 0 | 0 |
| Sending data | 0.364132 | 0.360529 | 0.002426 | 0 | 0 |
| Creating sort index | 0.000053 | 0.000034 | 0.000017 | 0 | 0 |
| end | 0.000004 | 0.000002 | 0.000002 | 0 | 0 |
| query end | 0.000007 | 0.000005 | 0.000002 | 0 | 0 |
| removing tmp table | 0.000005 | 0.000003 | 0.000002 | 0 | 0 |
| query end | 0.000003 | 0.000002 | 0.000001 | 0 | 0 |
| closing tables | 0.000006 | 0.000004 | 0.000002 | 0 | 0 |
| freeing items | 0.000023 | 0.000016 | 0.000007 | 0 | 0 |
| cleaning up | 0.000012 | 0.000007 | 0.000004 | 0 | 0 |
+----------------------+----------+----------+------------+--------------+---------------+
20 rows in set, 1 warning (0.00 sec)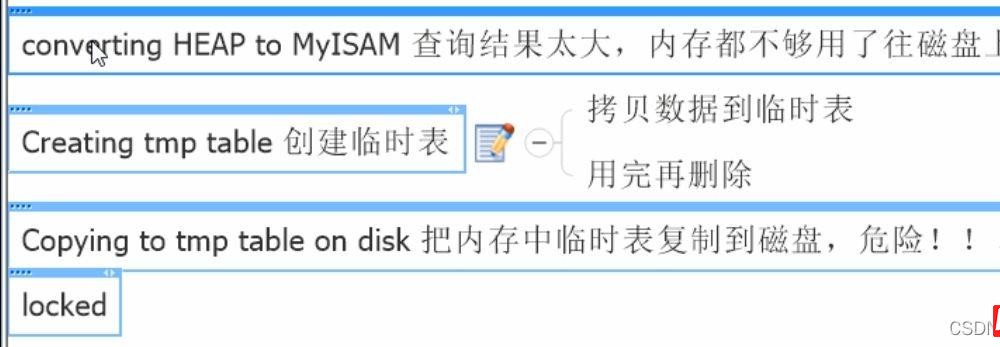
如果出现以上这四个 中的任何一个就需要 优化查询语句
set global general_log=1;
set global log_output='TABLE';此后你编写的sql语句将会记录到mysql库里的general_log表,可以用下面的命令查看
select * from mysql.general_log;
mysql> select * from mysql.general_log;
+----------------------------+---------------------------+-----------+-----------+--------------+---------------------------------+
| event_time | user_host | thread_id | server_id | command_type | argument |
+----------------------------+---------------------------+-----------+-----------+--------------+---------------------------------+
| 2021-12-06 11:53:53.457242 | root[root] @ localhost [] | 68 | 1 | Query | select * from mysql.general_log |
+----------------------------+---------------------------+-----------+-----------+--------------+---------------------------------+
1 row in set (0.00 sec)在下面进行表锁的测试
use big_data;
create table mylock (
id int not null primary key auto_increment,
name varchar(20) default ''
) engine myisam;
insert into mylock(name) values('a');
insert into mylock(name) values('b');
insert into mylock(name) values('c');
insert into mylock(name) values('d');
insert into mylock(name) values('e');
select * from mylock;
lock table mylock read,book write;## 读锁锁mylock 写锁锁book
show open tables; ##显示哪些表被加锁了
unlock tables;##取消锁
##添加读锁后不可修改
mysql> lock table mylock read;##1
Query OK, 0 rows affected (0.00 sec)
mysql> select * from mylock;##1
+----+------+
| id | name |
+----+------+
| 1 | a |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
+----+------+
5 rows in set (0.00 sec)
mysql> update mylock set name='a2' where id=1; ##1
ERROR 1099 (HY000): Table 'mylock' was locked with a READ lock and can't be updated
##改不了当前读锁锁住的表
##读不了其他表
mysql> select * from book;##1
ERROR 1100 (HY000): Table 'book' was not locked with LOCK TABLES为了区分两个命令 把1当作原有的mysql命令终端上的操作,2当作新建的mysql终端

新建一个mysql终端命令操作
##新建一个mysql终端命令操作
mysql> update mylock set name='a3' where id=1; ##2发现会出现阻塞操作
在原有的mysql命令终端上取消锁
unlock tables;##1
Query OK, 1 row affected (2 min 1.46 sec) ##2
Rows matched: 1 Changed: 1 Warnings: 0 ##2会发现阻塞了两分钟多
总结 :当读锁锁表mylock之后:1.查询操作:当前client(终端命令操作1)可以进行查询表mylock
其他client(终端命令操作2)也可以查询表mylock 2.DML操作(增删改)当前client会失效报错 ERROR 1099 (HY000): Table 'mylock' was locked with a READ lock and can't be updated 其他client进行DML操作会让mysql陷入阻塞状态直到当前session释放锁
mysql> lock table mylock write;
Query OK, 0 rows affected (0.00 sec)
给当前session mylock表加上写锁
mysql> update mylock set name='a4'where id=1 ;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from mylock;
+----+------+
| id | name |
+----+------+
| 1 | a4 |
| 2 | b |
| 3 | c |
| 4 | d |
| 5 | e |
+----+------+
mysql> select * from book;
ERROR 1100 (HY000): Table 'book' was not locked with LOCK TABLES会发现无法操其他表但是可以操作加上锁的表
再开启一个新的客户端测试被锁住的表
mysql> select * from mylock;
5 rows in set (2 min 30.92 sec)发现新的客户端上操作(增删改查)被写锁锁住的表会陷入阻塞状态

作
分析表锁定
mysql> show status like 'table%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Table_locks_immediate | 194 |
| Table_locks_waited | 0 |
| Table_open_cache_hits | 18 |
| Table_open_cache_misses | 2 |
| Table_open_cache_overflows | 0 |
+----------------------------+-------+
5 rows in set (0.00 sec)
InnoDB 的行锁模式
InnoDB 实现了以下两种类型的行锁。
对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);
对于普通SELECT语句,InnoDB不会加任何锁;
可以通过以下语句显示给记录集加共享锁或排他锁 。
共享锁(S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE
排他锁(X) :SELECT * FROM table_name WHERE ... FOR UPDATE由于行锁支持事务,在此复习一下
事务是一组由SQL语句组成的逻辑处理单元,事务具有四个属性:ACID
并发事务带来的问题:
更新丢失,脏读,不可重复读,幻读
| ACID属性 | 含义 |
|---|---|
| 原子性(Atomicity) | 事务是一个原子操作单元,其对数据的修改,要么全部成功,要么全部失败。 |
| 一致性(Consistent) | 在事务开始和完成时,数据都必须保持一致状态。 |
| 隔离性(Isolation) | 数据库系统提供一定的隔离机制,保证事务在不受外部并发操作影响的 “独立” 环境下运行。 |
| 持久性(Durable) | 事务完成之后,对于数据的修改是永久的。 |
并发事务处理带来的问题
| 问题 | 含义 |
|---|---|
| 丢失更新(Lost Update) | 当两个或多个事务选择同一行,最初的事务修改的值,会被后面的事务修改的值覆盖。 |
| 脏读(Dirty Reads) | 当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。 |
| 不可重复读(Non-Repeatable Reads) | 一个事务在读取某些数据后的某个时间,再次读取以前读过的数据,却发现和以前读出的数据不一致。 |
| 幻读(Phantom Reads) | 一个事务按照相同的查询条件重新读取以前查询过的数据,却发现其他事务插入了满足其查询条件的新数据。 |
事务隔离级别
为了解决上述提到的事务并发问题,数据库提供一定的事务隔离机制来解决这个问题。数据库的事务隔离越严格,并发副作用越小,但付出的代价也就越大,因为事务隔离实质上就是使用事务在一定程度上“串行化” 进行,这显然与“并发” 是矛盾的。
数据库的隔离级别有4个,由低到高依次为Read uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决脏写、脏读、不可重复读、幻读这几类问题。
| 隔离级别 | 丢失更新 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| Read uncommitted | × | √ | √ | √ |
| Read committed | × | × | √ | √ |
| Repeatable read(默认) | × | × | × | √ |
| Serializable | × | × | × | × |
备注 : √ 代表可能出现 , × 代表不会出现 。
Mysql 的数据库的默认隔离级别为 Repeatable read , 查看方式:
show variables like 'tx_isolation';行锁测试建表, 案例准备工作
create table test_innodb_lock(
id int(11),
name varchar(16),
sex varchar(1)
)engine = innodb default charset=utf8;
insert into test_innodb_lock values(1,'100','1');
insert into test_innodb_lock values(3,'3','1');
insert into test_innodb_lock values(4,'400','0');
insert into test_innodb_lock values(5,'500','1');
insert into test_innodb_lock values(6,'600','0');
insert into test_innodb_lock values(7,'700','0');
insert into test_innodb_lock values(8,'800','1');
insert into test_innodb_lock values(9,'900','1');
insert into test_innodb_lock values(1,'200','0');
create index idx_test_innodb_lock_id on test_innodb_lock(id);
create index idx_test_innodb_lock_name on test_innodb_lock(name);还是开俩个终端测试,关闭事自动事务提交,因为自动事务提交会自动加锁释放锁;
mysql> set autocommit=0;
mysql> set autocommit=0;
会发现查询无影响
对左边进行更新操作
mysql> update test_innodb_lock set name='100' where id=3;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 1 Changed: 0 Warnings: 0对左边进行更新操作
对右边进行更新操作后停止操作
mysql> update test_innodb_lock set name='340' where id=3;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction会发现进行阻塞了 直到锁释放或者提交事务(commit)为止
对于innodb引擎来说,对某一行数据进行DML(增删改)操作会对操作的那行添加排它锁
别的事务就不能执行这行语句了,但是可以操作其他行的数据
无索引行锁会升级成表锁:如果不通过索引条件检索数据,那么innodb会对表中所有记录加锁,实际效果和表锁一样
记住进行操作时使用索引:innodb引擎索引失效时时行锁会升级为表锁
mysql> update test_innodb_lock set sex='2' where name=400;
Query OK, 0 rows affected (0.00 sec)
Rows matched: 2 Changed: 0 Warnings: 0注意这里name没有加单引号 索引失效
mysql> update test_innodb_lock set sex='3' where id=3;
Query OK, 1 row affected (23.20 sec)
Rows matched: 1 Changed: 1 Warnings: 0发现了对其他行操作也陷入了阻塞状态,这是没加索引导致的行锁升级为表锁
本来只对一行数据加锁 但是由于忘记给name字段加单引号导致索引失效给全表都加上了锁;
当我们使用范围条件而不是想等条件进行检索数据,并请求共享或排它锁,在那个范围条件中有不存在的记录,叫做间隙,innodb也会对这个间隙进行加锁,这种锁机制就叫做间隙锁
mysql> select * from test_innodb_lock;
+------+------+------+
| id | name | sex |
+------+------+------+
| 1 | 100 | 2 |
| 3 | 100 | 3 |
| 4 | 400 | 0 |
| 5 | 500 | 1 |
| 6 | 600 | 0 |
| 7 | 700 | 3 |
| 8 | 800 | 1 |
| 9 | 900 | 2 |
| 1 | 200 | 0 |
+------+------+------+
没有id为2的数据
行锁征用情况查看
mysql> show status like 'innodb_row_lock%';
+-------------------------------+--------+
| Variable_name | Value |
+-------------------------------+--------+
| Innodb_row_lock_current_waits | 0 |
| Innodb_row_lock_time | 284387 |
| Innodb_row_lock_time_avg | 21875 |
| Innodb_row_lock_time_max | 51003 |
| Innodb_row_lock_waits | 13 |
+-------------------------------+--------+
5 rows in set (0.00 sec)
Innodb_row_lock_current_waits: 当前正在等待锁定的数量
Innodb_row_lock_time: 从系统启动到现在锁定总时间长度
Innodb_row_lock_time_avg:每次等待所花平均时长
Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花的时间
Innodb_row_lock_waits: 系统启动后到现在总共等待的次数InnoDB存储引擎由于实现了行级锁定,虽然在锁定机制的实现方面带来了性能损耗可能比表锁会更高一些,但是在整体并发处理能力方面要远远由于MyISAM的表锁的。当系统并发量较高的时候,InnoDB的整体性能和MyISAM相比就会有比较明显的优势。
但是,InnoDB的行级锁同样也有其脆弱的一面,当我们使用不当的时候,可能会让InnoDB的整体性能表现不仅不能比MyISAM高,甚至可能会更差。
优化建议:
--结束END--
本文标题: 超全MySQL学习笔记
本文链接: https://lsjlt.com/news/160862.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0