Python 官方文档:入门教程 => 点击学习
目录一、KNN算法简介二、KNN算法实现思路三、KNN算法预测城市空气质量1. 获取数据2. 生成测试集和训练集3. 实现KNN算法一、KNN算法简介 KNN(K-Nearest N
KNN(K-Nearest Neighbor)最邻近分类算法是数据挖掘分类(classification)技术中常用算法之一,其指导思想是"近朱者赤,近墨者黑",即由你的邻居来推断出你的类别。
KNN最邻近分类算法的实现原理:为了判断未知样本的类别,以所有已知类别的样本作为参照,计算未知样本与所有已知样本的距离,从中选取与未知样本距离最近的 K 个已知样本,再根据少数服从多数的投票法则(majority-voting),将未知样本与 K 个最邻近样本中所属类别占比较多的归为一类。
KNN算法的核心思想:寻找最近的 k 个数据,推测新数据的分类
KNN算法的关键:
1.样本的所有特征都要做可比较的量化
若是样本特征中存在非数值的类型,必须采取方法将其量化为数值。例如样本特征中包含颜色,可通过将颜色转换为灰度值来实现距离计算。
2.样本特征要做归一化处理
样本有多个参数,每一个参数都有自己的定义域和取值范围,他们对距离计算的影响不一样,如取值较大的影响力会盖过取值较小的参数。所以样本参数必须做一些 scale 处理,最简单的方式就是所有特征的数值都采取归一化处理。
3.需要一个距离函数以计算两个样本之间的距离
通常使用的距离函数有:欧氏距离、余弦距离、汉明距离、曼哈顿距离等,一般选欧氏距离作为距离度量,但是这是只适用于连续变量。在文本分类这种非连续变量情况下,余弦距离可以用来作为度量。通常情况下,如果运用一些特殊的算法来计算度量的话,K近邻分类精度可显著提高,如运用大边缘最近邻法或者近邻成分分析法。
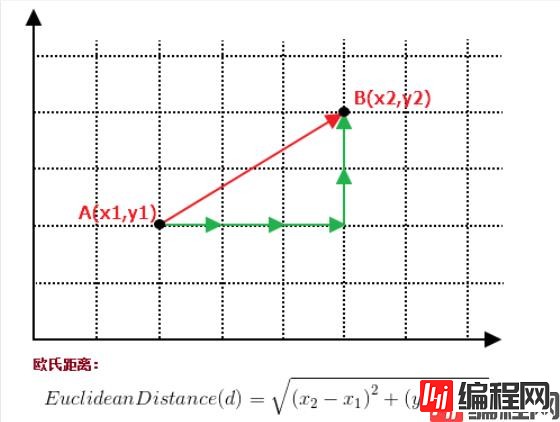
以计算二维空间中的A(x1,y1)、B(x2,y2)两点之间的距离为例,常用的欧氏距离的计算方法如下图所示:
确定K的值
K值选的太大易引起欠拟合,太小容易过拟合,需交叉验证确定 K 值。
KNN算法的优点:
简单,易于理解,易于实现,无需估计参数,无需训练;
适合对稀有事件进行分类;
特别适合于多分类问题(multi-modal,对象具有多个类别标签), KNN比 SVM 的表现要好。
KNN算法的缺点:
KNN算法在分类时有个主要的不足是:当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的 K 个邻居中大容量类的样本占多数。该算法只计算最近的邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的 K 个最近邻点。
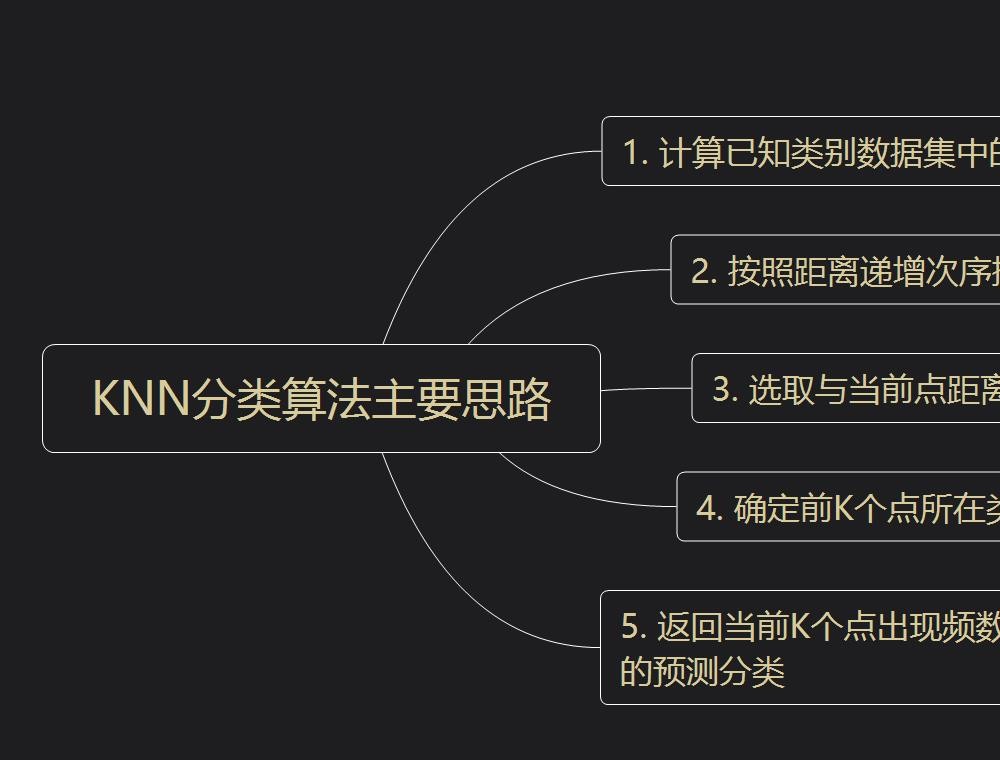
要自己动手用 python 实现 KNN 算法,主要有以下三个步骤:
数据来源:Http://www.tianqihoubao.com/aqi/chengdu-201901.html

对于这种 Table 表格型数据,可以直接用 pandas 的 read_html() 大法,将数据保存到csv,也就不用再写爬虫去解析网页和提取数据了。
# -*- coding: UTF-8 -*-
"""
@File :spider.py
@Author :叶庭云
@CSDN :https://yetingyun.blog.csdn.net/
@http://www.tianqihoubao.com/aqi/beijing-201901.html
"""
import pandas as pd
import logging
logging.basicConfig(level=logging.INFO, fORMat='%(asctime)s - %(levelname)s: %(message)s')
for page in range(1, 13): # 12个月
if page < 10:
url = f'http://www.tianqihoubao.com/aqi/guangzhou-20190{page}.html'
df = pd.read_html(url, encoding='gbk')[0]
if page == 1:
df.to_csv('2019年广州空气质量数据.csv', mode='a+', index=False, header=False)
else:
df.iloc[1:,::].to_csv('2019年广州空气质量数据.csv', mode='a+', index=False, header=False)
else:
url = f'http://www.tianqihoubao.com/aqi/guangzhou-2019{page}.html'
df = pd.read_html(url, encoding='gbk')[0]
df.iloc[1:,::].to_csv('2019年广州空气质量数据.csv', mode='a+', index=False, header=False)
logging.info(f'{page}月空气质量数据下载完成!')
多爬取几个城市 2019 年历史空气质量数据保存到本地
import pandas as pd
# 将2019年成都空气质量数据作为测试集
df = pd.read_csv('2019年成都空气质量数据.csv')
# 取质量等级 AQI指数 当天AQI排名 PM2.5 。。。8列数据
# SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame 解决方法
df1 = df[['AQI指数', '当天AQI排名', 'PM2.5', 'PM10', 'So2', 'No2', 'Co', 'O3']].copy()
air_quality = []
# print(df['质量等级'].value_counts())
# 质量等级列数据为字符串 转为为标签 便于判断预测
for i in df['质量等级']:
if i == "优":
air_quality.append('1')
elif i == "良":
air_quality.append('2')
elif i == "轻度污染":
air_quality.append('3')
elif i == "中度污染":
air_quality.append('4')
elif i == "重度污染":
air_quality.append('5')
elif i == "严重污染":
air_quality.append('6')
print(air_quality)
df1['空气质量'] = air_quality
# 将数据写入test.txt
# print(df1.values, type(df1.values)) # <class 'numpy.ndarray'>
with open('test.txt', 'w') as f:
for x in df1.values:
print(x)
s = ','.join([str(i) for i in x])
# print(s, type(s))
f.write(s + '\n')
import pandas as pd
# 自定义其他几个城市空气质量数据作为训练集
df = pd.read_csv('2019年天津空气质量数据.csv', encoding='utf-8')
# 取质量等级 AQI指数 当天AQI排名 PM2.5 。。。8列数据
# SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame 解决方法
df1 = df[['AQI指数', '当天AQI排名', 'PM2.5', 'PM10', 'So2', 'No2', 'Co', 'O3']].copy()
air_quality = []
# print(df['质量等级'].value_counts())
# 质量等级列数据为字符串 转为为数字标识
for i in df['质量等级']:
if i == "优":
air_quality.append('1')
elif i == "良":
air_quality.append('2')
elif i == "轻度污染":
air_quality.append('3')
elif i == "中度污染":
air_quality.append('4')
elif i == "重度污染":
air_quality.append('5')
elif i == "严重污染":
air_quality.append('6')
print(air_quality)
df1['空气质量'] = air_quality
# 将数据写入追加写入到train.txt
# print(df1.values, type(df1.values)) # <class 'numpy.ndarray'>
with open('train.txt', 'a+') as f:
for x in df1.values:
print(x)
s = ','.join([str(i) for i in x])
# print(s, type(s))
f.write(s + '\n')
读取数据集
def read_dataset(filename1, filename2, trainingSet, testSet):
with open(filename1, 'r') as csvfile:
lines = csv.reader(csvfile) # 读取所有的行
dataset1 = list(lines) # 转化成列表
for x in range(len(dataset1)): # 每一行数据
for y in range(8):
dataset1[x][y] = float(dataset1[x][y]) # 8个参数转换为浮点数
testSet.append(dataset1[x]) # 生成测试集
with open(filename2, 'r') as csvfile:
lines = csv.reader(csvfile) # 读取所有的行
dataset2 = list(lines) # 转化成列表
for x in range(len(dataset2)): # 每一行数据
for y in range(8):
dataset2[x][y] = float(dataset2[x][y]) # 8个参数转换为浮点数
trainingSet.append(dataset2[x]) # 生成训练集
计算欧氏距离
def calculateDistance(testdata, traindata, length): # 计算距离
distance = 0 # length表示维度 数据共有几维
for x in range(length):
distance += pow((int(testdata[x]) - int(traindata[x])), 2)
return round(math.sqrt(distance), 3) # 保留3位小数
找 K 个相邻最近的邻居
def getNeighbors(self, trainingSet, test_instance, k): # 返回最近的k个边距
distances = []
length = len(test_instance)
# 对训练集的每一个数计算其到测试集的实际距离
for x in range(len(trainingSet)):
dist = self.calculateDistance(test_instance, trainingSet[x], length)
print('训练集:{} --- 距离:{}'.format(trainingSet[x], dist))
distances.append((trainingSet[x], dist))
distances.sort(key=operator.itemgetter(1)) # 按距离从小到大排列
# print(distances)
neighbors = []
# 排序完成后取距离最小的前k个
for x in range(k):
neighbors.append(distances[x][0])
print(neighbors)
return neighbors
计算比例最大的分类
def getResponse(neighbors): # 根据少数服从多数,决定归类到哪一类
class_votes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1] # 统计每一个分类的多少 空气质量的数字标识
if response in class_votes:
class_votes[response] += 1
else:
class_votes[response] = 1
print(class_votes.items())
sortedVotes = sorted(class_votes.items(), key=operator.itemgetter(1), reverse=True) # 按分类大小排序 降序
return sortedVotes[0][0] # 分类最大的 少数服从多数 为预测结果
预测准确率计算
def getAccuracy(test_set, predictions):
correct = 0
for x in range(len(test_set)):
# predictions预测的与testset实际的比对 计算预测的准确率
if test_set[x][-1] == predictions[x]:
correct += 1
else:
# 查看错误预测
print(test_set[x], predictions[x])
print('有{}个预测正确,共有{}个测试数据'.format(correct, len(test_set)))
return (correct / (len(test_set))) * 100.0
run函数调用
# -*- coding: UTF-8 -*-
"""
@Author :叶庭云
@公众号 :修炼Python
@CSDN :https://yetingyun.blog.csdn.net/
"""
def run(self):
training_set = [] # 训练集
test_set = [] # 测试集
self.read_dataset('./train_4/test.txt', './train_4/train.txt', training_set, test_set) # 数据划分
print('Train set: ' + str(len(training_set)))
print('Test set: ' + str(len(test_set)))
# generate predictions
predictions = []
k = 7 # 取最近的6个数据
for x in range(len(test_set)): # 对所有的测试集进行测试
neighbors = self.getNeighbors(training_set, test_set[x], k) # 找到8个最近的邻居
result = self.getResponse(neighbors) # 找这7个邻居归类到哪一类
predictions.append(result)
accuracy = self.getAccuracy(test_set, predictions)
print('预测准确度为: {:.2f}%'.format(accuracy)) # 保留2位小数
运行效果如下:

可以通过增加训练集城市空气质量数据量,调节找邻居的数量k,提高预测准确率。

以上就是Python机器学习之手写KNN算法预测城市空气质量的详细内容,更多关于Python KNN 预测空气质量的资料请关注编程网其它相关文章!
--结束END--
本文标题: Python机器学习之手写KNN算法预测城市空气质量
本文链接: https://lsjlt.com/news/159648.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0