目录1. 插入被查询的结果2. 聚合查询2.1 介绍2.2 聚合函数2.3 group by 子句2.4 having3. 联合查询3.1 介绍3.2 内连接3.3 外连接
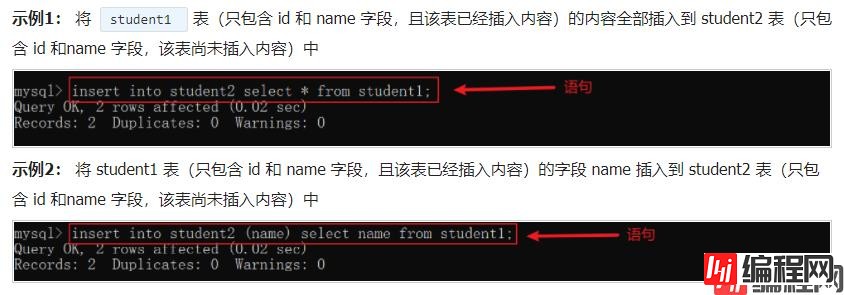
语法:
insert into 要插入的表 [(列1, ..., 列n)] select {* | (列1, ..., 列n)}from 要查询的表
上述语句可以将要查询的表的某些列插入到新的表中对应的某些列
聚合查询:是指对一个数据表中某个字段的数据进行部分或者全部统计查询的一种方式(即是在行的维度进行合并的查询)。比如所有全部书的平均价格或者是书籍的总数量等等,在这些时候就会使用到聚合查询这种方法。
聚合查询可以使用以下常用聚合函数,这些聚合函数就相当于 sql 提供的“库函数”
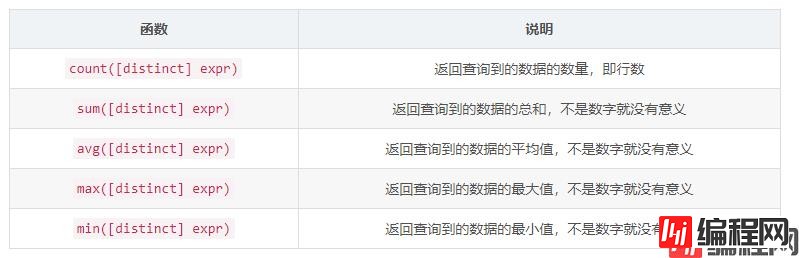
补充:
接下来以表名为 exam_result,具体数据如下的表,进行示例展示
| id | name | chinese | math | english |
|---|---|---|---|---|
| 1 | 唐三藏 | 67.0 | 98.0 | 56.0 |
| 2 | 孙悟空 | 87.5 | 78.0 | 77.0 |
| 3 | 猪悟能 | 88.0 | 98.5 | 90.0 |
| 4 | 曹孟德 | 82.0 | 84.0 | 67.0 |
| 5 | 刘玄德 | 55.5 | 85.0 | 45.0 |
| 6 | 孙权 | 70.0 | 73.0 | 78.5 |
| 7 | 宋公明 | null | null | null |
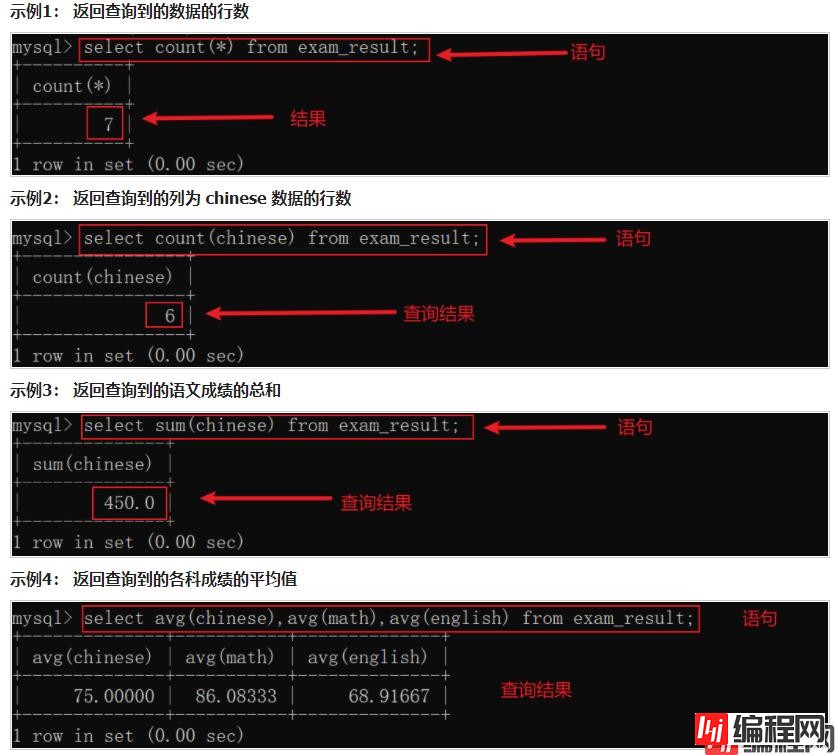

使用前面的聚合函数,实际上是把该表中的所有行结合起来。但还可以使用 group by 来进行分组聚合(在 group by 后面加上指定列名,那么该列中值相同的就将分成一组)
接下来我们将对表名为 emp,数据如下的表进行示例展示

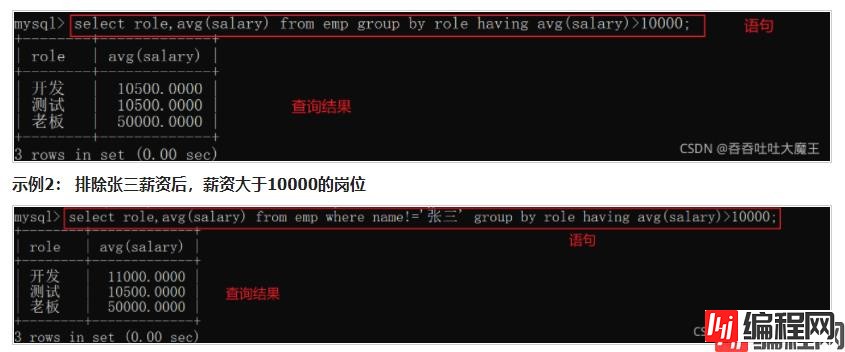
如果使用 group by 子句进行分组以后,需要对分组结果再进行条件过滤,这时就不能使用 where 语句了,而是使用 having 语句
注意:
where 语句是在分组之前进行筛选having 语句是在分组之后进行筛选where 语句和 having 语句可以同时使用示例1: 查询薪资大于10000的岗位
联合查询:是可合并多个相似的选择查询的结果集。 也就是进行多表查询,其核心思想是使用了笛卡尔积
笛卡尔积思想:
使用笛卡尔积的思想,其实就是把两个表的结果进行一个排列组合,接下来我们将两个表 A、B 通过笛卡尔积的思想得到一个新的表 C
学生表 A:
| 学号 | 姓名 | 班级id |
|---|---|---|
| 1 | 张三 | 2001 |
| 2 | 李四 | 2001 |
| 3 | 王五 | 2002 |
班级表 B:
| 班级id | 班级名 |
|---|---|
| 2001 | 高二(1)班 |
| 2002 | 高二(2)班 |
新表 C:
| 学号 | 姓名 | 班级id | 班级id | 班级名 |
|---|---|---|---|---|
| 1 | 张三 | 2001 | 2001 | 高二(1)班 |
| 1 | 张三 | 2001 | 2002 | 高二(2)班 |
| 2 | 李四 | 2001 | 2001 | 高二(1)班 |
| 2 | 李四 | 2001 | 2002 | 高二(2)班 |
| 3 | 王五 | 2002 | 2001 | 高二(1)班 |
| 3 | 王五 | 2002 | 2002 | 高二(2)班 |
补充:
通过新得到的 C 表,我们就可以将 A、B 两张表联系起来,而联系的纽带在上面的示例中就是班级id。到此时,虽然将两个表联系起来了,但是不是新表中的每条数据都是合理的,例如第2行的信息其实就是不正确的。因此将两表联系起来后,还需要加上一些条件的限制,如 A 和 B 表的班级id应该相同,此时就可以得到一个数据更合理的表 D
新表 D:
| 学号 | 姓名 | 班级id | 班级id | 班级名 |
|---|---|---|---|---|
| 1 | 张三 | 2001 | 2001 | 高二(1)班 |
| 2 | 李四 | 2001 | 2001 | 高二(1)班 |
| 3 | 王五 | 2002 | 2001 | 高二(2)班 |
此时我们就可以进行一个多表查询
注意:
联合查询由于使用了笛卡尔积,那么新表的行数就是所有表联合的乘积。因此使用联合查询结果的数据可能很大,要谨慎使用
以下示例都是通过下面 SQL 语句建的表来进行操作学习的,如果你想在后面的内容进行操作,可以直接复制使用
drop table if exists classes;
drop table if exists student;
drop table if exists course;
drop table if exists score;
create table classes (id int primary key auto_increment, name varchar(20), `desc` varchar(100));
create table student (id int primary key auto_increment, sn varchar(20), name varchar(20), qq_mail varchar(20) ,
classes_id int);
create table course(id int primary key auto_increment, name varchar(20));
create table score(score decimal(3, 1), student_id int, course_id int);
insert into classes(name, `desc`) values
('计算机系2019级1班', '学习了计算机原理、C和Java语言、数据结构和算法'),
('中文系2019级3班','学习了中国传统文学'),
('自动化2019级5班','学习了机械自动化');
insert into student(sn, name, qq_mail, classes_id) values
('09982','黑旋风李逵','xuanfeng@qq.com',1),
('00835','菩提老祖',null,1),
('00391','白素贞',null,1),
('00031','许仙','xuxian@qq.com',1),
('00054','不想毕业',null,1),
('51234','好好说话','say@qq.com',2),
('83223','tellme',null,2),
('09527','老外学中文','foreigner@qq.com',2);
insert into course(name) values
('Java'),('中国传统文化'),('计算机原理'),('语文'),('高阶数学'),('英文');
insert into score(score, student_id, course_id) values
-- 黑旋风李逵
(70.5, 1, 1),(98.5, 1, 3),(33, 1, 5),(98, 1, 6),
-- 菩提老祖
(60, 2, 1),(59.5, 2, 5),
-- 白素贞
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- 许仙
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- 不想毕业
(81, 5, 1),(37, 5, 5),
-- 好好说话
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- tellme
(80, 7, 2),(92, 7, 6);
语法:
-- 方法一:
select 展示的列名 from 表1 [表1别名],表2 [表2别名] where 连接条件;
-- 方式二:使用 [inner] join on
select 展示的列名 from 表1 [表1别名] [inner] join 表2 [表2别名] on 连接条件;
补充:
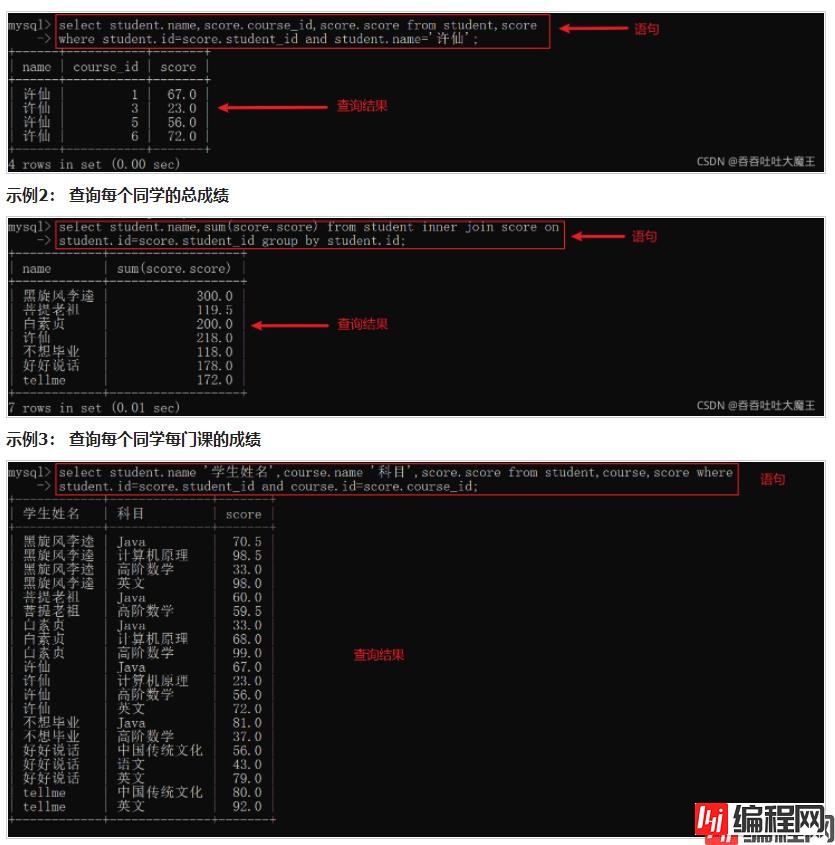
示例1: 查询许仙同学每门课的成绩
外连接:分为左外连接和右外连接。如果使用联合查询,左侧的表完全显示就是用了左外连接;右侧的表完全显示就是用了右外连接
外连接其实和内连接差不多,都是使用了笛卡尔积。内连接是针对的两个表中的每一条数据都是一一对应的,那怎么就不是一一对应了呢?例如下面两个表 A、B
A 表:
| id | name |
|---|---|
| 1 | 张三 |
| 2 | 李四 |
| 3 | 王五 |
B 表:
| student_id | score |
|---|---|
| 1 | 90 |
| 2 | 80 |
| 4 | 70 |
我们发现经过笛卡尔积后建立的新表时,A 表的 id 为3的记录和 B 表中没有对应的数据,B 表中 student_id 为4的记录和 A 表中也没有对应的数据,因此这两个表就不能使用内连接的方式去查询,要使用外连接
如果使用左连接的方式,新表 C 为:
| id | name | student_id | score |
|---|---|---|---|
| 1 | 张三 | 1 | 90 |
| 2 | 李四 | 2 | 80 |
| 3 | 王五 | null | null |
如果使用右连接的方式,新表 D 为:
| id | name | student_id | score |
|---|---|---|---|
| 1 | 张三 | 1 | 90 |
| 2 | 李四 | 2 | 80 |
| null | null | 4 | 70 |
补充:
语法:
-- 左连接,表1完全显示
select 展示的列名 from 表1 [表1别名] [left] join 表2 [表2别名] on 连接条件;
-- 右连接,表2完全显示
select 展示的列名 from 表1 [表1别名] [right] join 表2 [表2别名] on 连接条件;
自连接:是指在同一张表中连接自身进行查询,使用自连接其实可以将”行转换成列“来进行操作
为什么自连接可以将行转换成列来进行操作呢?假设有一张表 A
| student_id | course_id | score |
|---|---|---|
| 1 | 1 | 70 |
| 1 | 2 | 90 |
| 1 | 3 | 80 |
如果我想找到原表中 student_id 为1,且其课程2成绩高于课程3的同学的信息时,就是要对行与行之间进行比较,但是一张表是不能进行该操作的
通过对自己进行笛卡尔积之后,得到新的表 B
| student_id | course_id | score | student_id | course_id | score |
|---|---|---|---|---|---|
| 1 | 1 | 70 | 1 | 1 | 70 |
| 1 | 2 | 90 | 1 | 2 | 90 |
| 1 | 3 | 80 | 1 | 3 | 80 |
此时我们发现,如果将原表进行笛卡尔积后,有了两张一样的表,就可以实施行与行之间操作
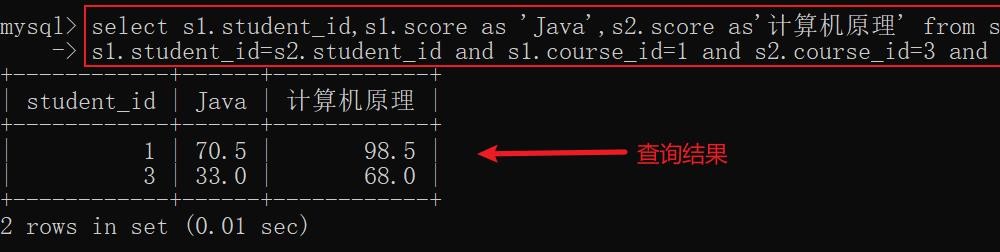
示例: 查询 Java 成绩高于计算机原理成绩的同学
子查询:是指嵌入在其它 SQL 语句中的 select 语句,也叫嵌套查询
分类:
补充:
in 进行多行查询过程: 使用子查询时,先执行子查询,将查询的结果存放在内存里,再执行外层查询,根据内存里的结果进行筛选exists 进行多行查询过程: 先执行外层循环,这样就会得到很多记录,在针对每行记录将它带入到子查询中,符合条件的就保留(exists 就是检测子查询结果是否为空集合)综上所述:
基于 in 的写法,速度快,适合子查询结果集合比较小的情况(较大内存装不下)
基于 exists 的写法,速度慢,适合子查询结果集合比较大,且外层查询结果数量比较少的情况
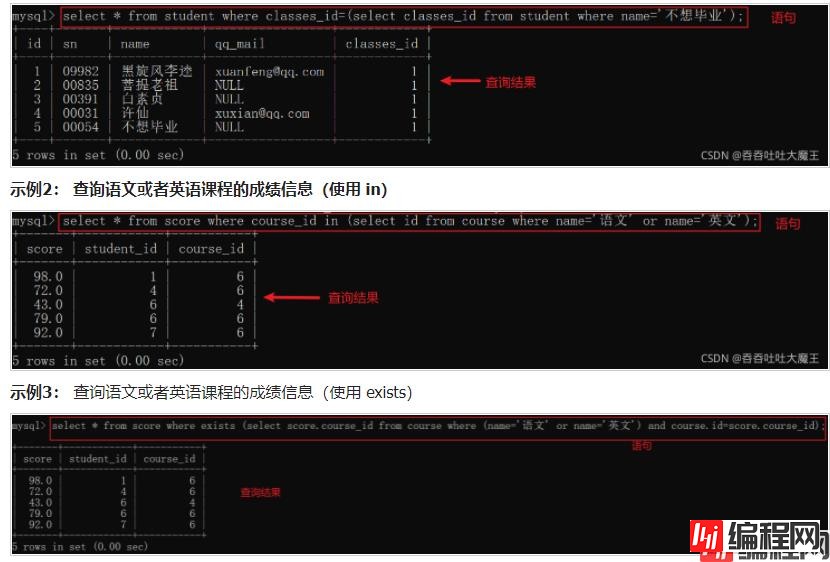
示例1: 查询不想毕业同学的同班同学(首先要知道不想毕业同学的班级,然后通过班级筛选学生)
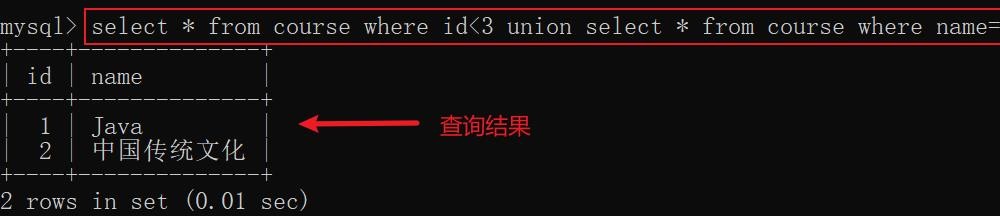
合并查询:是使用集合操作符 uNIOn 或 union all 来合并多个 select 的执行结果。使用合并查询时,前后查询的结果集中,字段需要一致
补充:
union 操作符不会对结果集的数据进行去重,union all 会进行去重示例: 查看 id 小于3,或者课程为 Java 的信息
--结束END--
本文标题: MySQL 数据库聚合查询和联合查询操作
本文链接: https://lsjlt.com/news/159334.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-10-23
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
2024-10-22
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0