Python 官方文档:入门教程 => 点击学习
目录一、张量裁剪1.tf.maximum/minimum/clip_by_value()2.tf.clip_by_nORM()二、张量排序1.tf.sort/argsort()2.t
该方法按数值裁剪,传入tensor和阈值,maximum是把数据中小于阈值的变成阈值。minimum是把数据中大于阈值的变成阈值。clip_by_value需要传入两个阈值,会把数据裁剪到阈值中间。
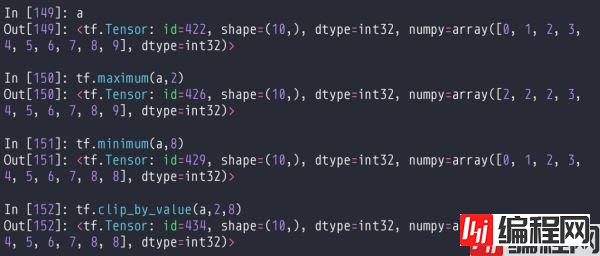
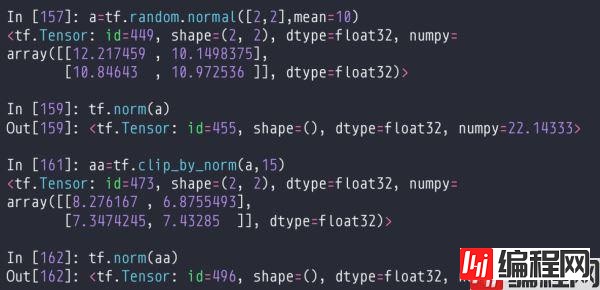
按范数裁剪,传入tensor和新的范数。通过裁剪范数,可以进行等比例放缩,使得梯度方向不变,但数值变小。通过这个方法可以对梯度进行裁剪,一次性对所有的参数的范数进行裁剪,并且保留方向。防止梯度爆炸,梯度弥散。
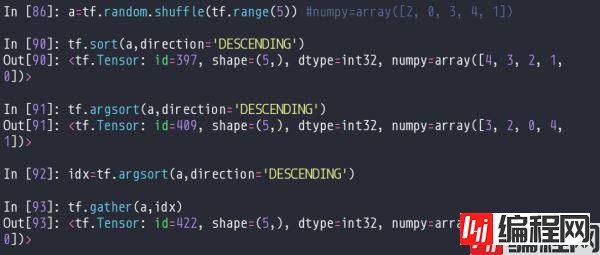
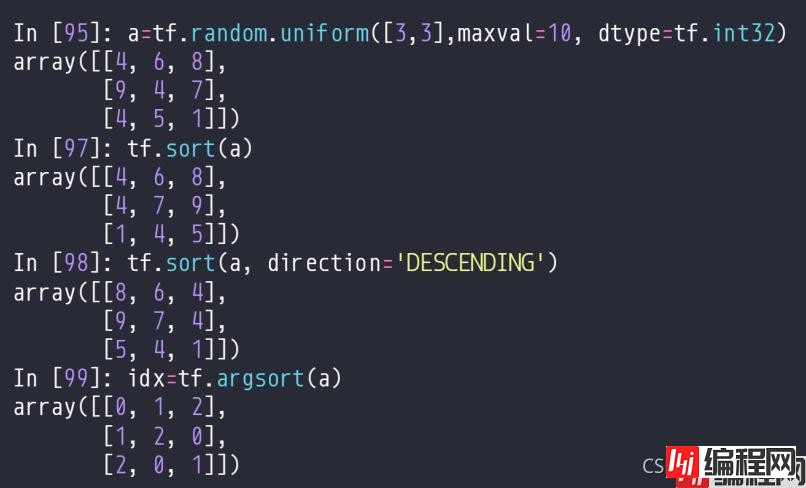
这两个方法分别返回排序后的值,排序后的索引。有索引之后,可以通过gather方法对数据排序。
对于多维tensor,不指定轴的时候,默认是对最后一个轴操作。
返回前k大的那些数据,以及索引。比如下面的例子,传入a,2的意思是前两个大的值。因此会对每一行,寻找前两大的数,以及对应的索引,存到返回值中。
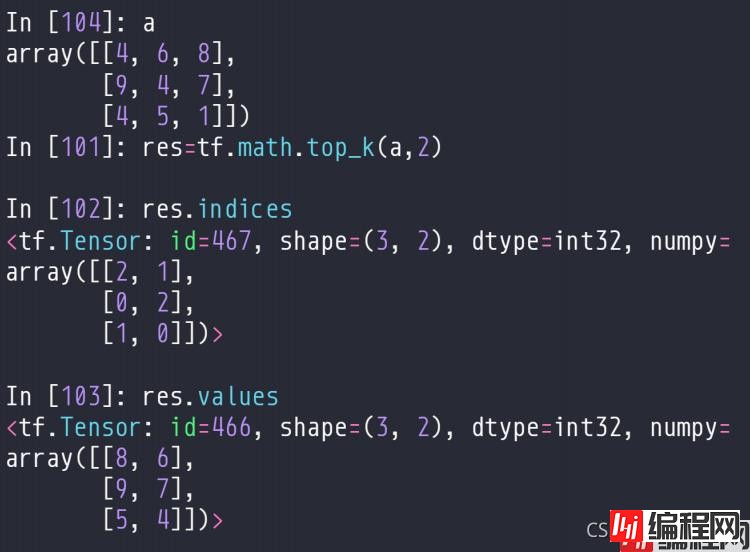
可以通过这个规则,求解topk的准确率。比如下面的例子,对于两条数据,预测概率是prob,根据预测概率,得到这两条数据最大值索引是2,1,而实际的值target是2,0。
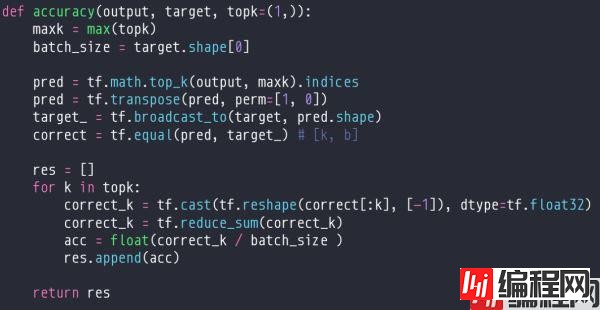
①通过tf.math.top_k方法,对预测的概率进行排序,让它返回前三大的值。并得到索引。
②将索引进行转置之后,可以方便地阅读:第一列就是第一条数据的预测值概率索引排序,第二列就是第二条数据的预测值概率索引排序。
③那么,对于两条数据top1的准确率,就是概率最大的索引,也就是第一行的两个数据,2,1,而实际值是2,0,那么top1准确率就是50%
④top2的准确率,意思就是,只要前两名的概率预测有对的,那就算预测对了。那么第一行,第一条预测对了,第二条预测错了。而第二行,第一条预测错了,第二条预测对了。
⑤那么,根据“只要前两个概率有一个对,那就算对”,top2的准确率就是100%

如果传入布尔型数据,会根据数据返回值为True的数值的索引。
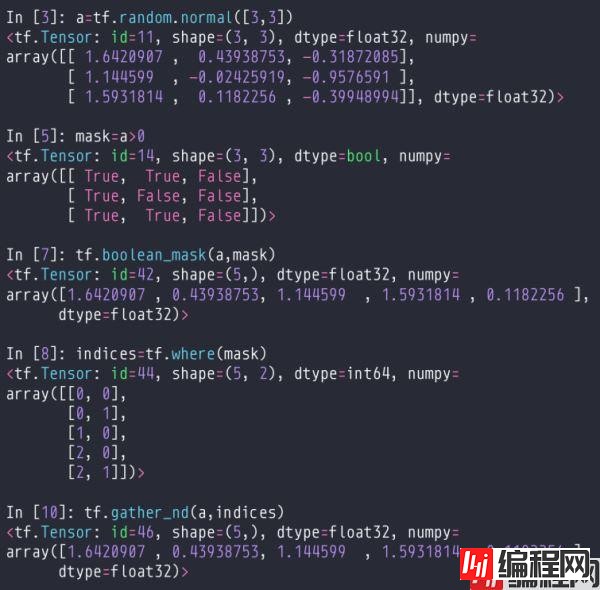
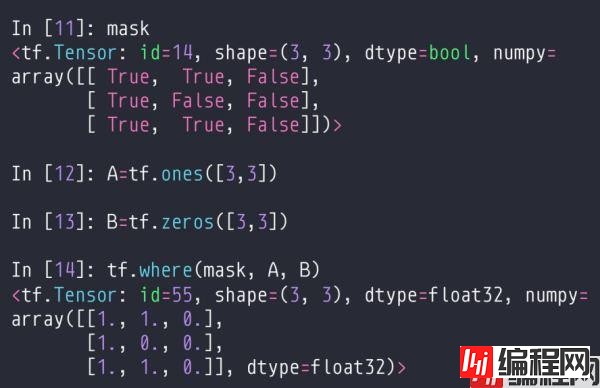
如果传入条件数据,比如where(condition, A, B),condition是一个布尔tensor,会从A里面选择condition为true的位置所对应的数据,从B里面选择conditon为false的位置所对应的数据。
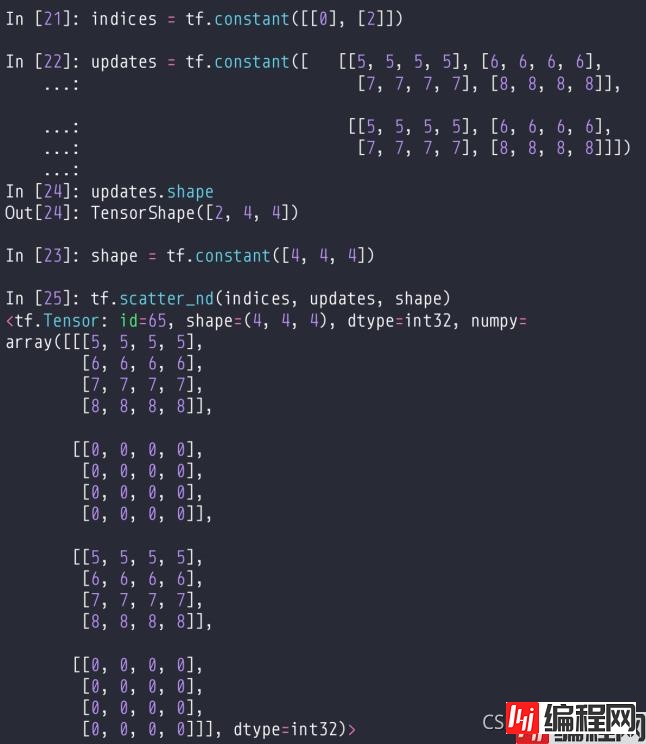
该方法中,传入索引,数据,底板。
底板通常是全0的tensor,索引是和数据一一对应的,并且索引的长度不超过底板。
传入的每一个数据都对应一个索引,然后把数据更新到底板上面索引对应的位置。

如果底板已经有数据了,就需要全部清零,再更新。
在二维上面举例如下:
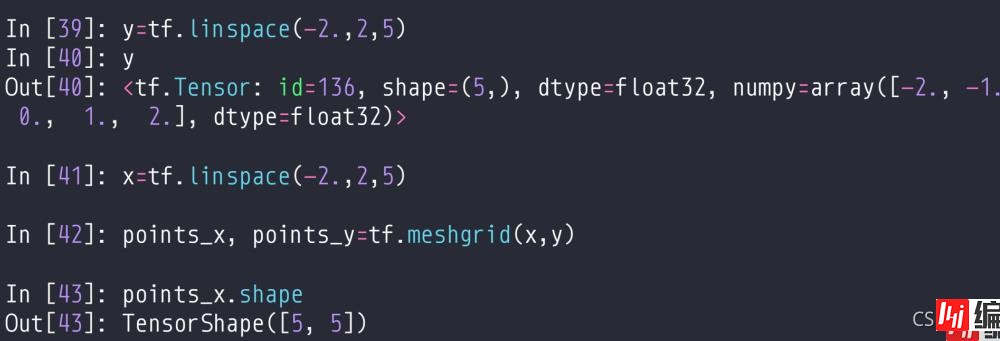
和numpy里面的meshgrid用法一样,分别生成的是网格中x和y的数据。例子如下:
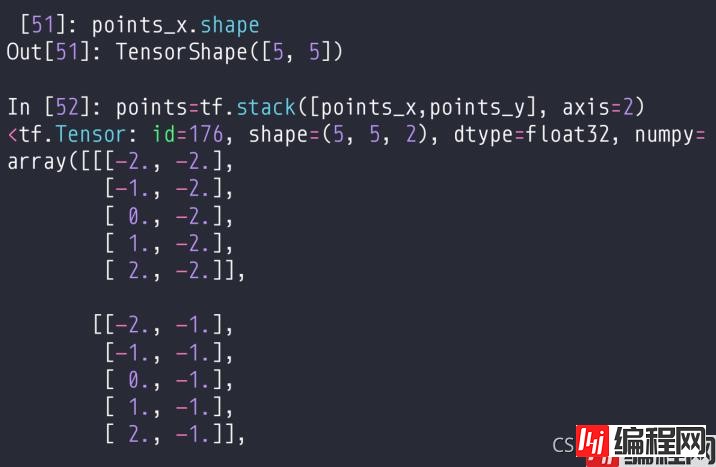
然后使用stack进行一个堆叠,就可以得到所有25个点的坐标。
以上就是TensorFlow人工智能学习张量及高阶操作示例详解的详细内容,更多关于TensorFlow张量高阶操作的资料请关注编程网其它相关文章!
--结束END--
本文标题: TensorFlow人工智能学习张量及高阶操作示例详解
本文链接: https://lsjlt.com/news/157012.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0