Python 官方文档:入门教程 => 点击学习
目录一、Numpy实现网络二、PyTorch:Tensor三、自动求导1、PyTorch:Tensor和auto_grad总结Pytorch的核心是两个主要特征: 1.一个n维ten
Pytorch的核心是两个主要特征:
1.一个n维tensor,类似于numpy,但是tensor可以在GPU上运行
2.搭建和训练神经网络时的自动微分/求导机制
在总结Tensor之前,先使用numpy实现网络。numpy提供了一个n维数组对象,以及许多用于操作这些数组的函数。
import numpy as np
# n是批量大小,d_in是输入维度
# h是隐藏的维度,d_out是输出维度
n,d_in,h,d_out=64,1000,100,10
# 创建随机输入和输出数据
x=np.random.randn(n,d_in)
y=np.random.randn(n,d_out)
# 随机初始化权重
w1=np.random.randn(d_in,h)
w2=np.random.randn(h,d_out)
learning_rate=1e-6
for i in range(500):
#前向传播,计算预测值y
h=x.dot(w1)
h_relu=np.maximum(h,0)
y_pred=h_relu.dot(w2)
#计算损失值
loss=np.square(y_pred-y).sum()
print(i,loss)
#反向传播,计算w1和w2对loss的梯度
grad_y_pred=2.0*(y_pred-y)
grad_w2=h_relu.T.dot(grad_y_pred)
grad_h_relu=grad_y_pred.dot(w2.T)
grad_h=grad_h_relu.copy()
grad_h[h<0]=0
grad_w1=x.T.dot(grad_h)
# 更新权重
w1-=learning_rate*grad_w1
w2-=learning_rate*grad_w2
运行结果


可以明显看到loss逐渐减小。
此处解释一下上次发的一篇中,有猿友对其中的loss有疑问,其实我认为:损失值loss只是为了检测网络的学习情况(至少我在这几篇中的loss就只有这个功能),在前面那一篇中迭代没有清零,所以损失值是一直增加的,如果每次迭代以后置零,效果和现在是一样的。至于其中的除以2000只是为了便于显示,可以一目了然大小的变化所以那么写的,所以可以自己定义合理的写法。(仅个人的理解和看法)
Tensor 在概念上和numpy中的array相同,tensor也是一个n维数组,pytorch提供了许多函数用于操作这些张量。所有使用numpy执行的计算都可以使用pytorch的tensor完成。与numpy不同的是pytorch可以利用GPU加速数据的计算。实现和numpy相同的过程
#%%tensor实现网络
import torch
dtype=torch.float
device=torch.device('cpu')
# device=torch.device('cuda:0')#由GPU的可爱们享受吧,我不配,实验室没有给我高配置的电脑
# n是批量大小,d_in是输入维度
# h是隐藏的维度,d_out是输出维度
n,d_in,h,d_out=64,1000,100,10
# 创建随机输入和输出数据
x=torch.randn(n,d_in,device=device,dtype=dtype)
y=torch.randn(n,d_out,device=device,dtype=dtype)
# 随机初始化权重
w1=torch.randn(d_in,h,device=device,dtype=dtype)
w2=torch.randn(h,d_out,device=device,dtype=dtype)
learning_rate=1e-6
for i in range(500):
#前向传播,计算预测值y
h=x.mm(w1)
h_relu=h.clamp(min=0)
y_pred=h_relu.mm(w2)
#计算损失值
loss=(y_pred-y).pow(2).sum().item()
print(i,loss)
#反向传播,计算w1和w2对loss的梯度
grad_y_pred=2.0*(y_pred-y)
grad_w2=h_relu.t().mm(grad_y_pred)
grad_h_relu=grad_y_pred.mm(w2.T)
grad_h=grad_h_relu.clone()
grad_h[h<0]=0
grad_w1=x.t().mm(grad_h)
# 更新权重
w1-=learning_rate*grad_w1
w2-=learning_rate*grad_w2
运行结果

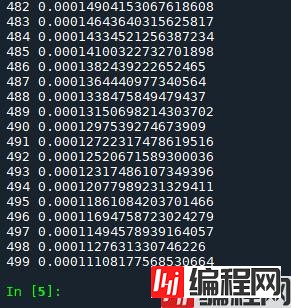
上面两个例子中,我们自己手动实现了神经网络的向前和向后传递。手动实现反向传递对小型双层网络来说没有问题,但是对于大型复杂的网络来说就会变得很繁琐。
但是Pytorch中的autograd包提供了自动微分可以用来计算神经网络中的后向传递。当使用autograd时候,网络前后想传播将定义一个计算图,图中的节点是tensor,边是函数,这些函数是输出tensor到输入tensor的映射。这张计算图使得在网络中反向传播时梯度的计算十分简单。
如果我们想要计算某些tensor的梯度,我们只需要在建立这个tensor时加上一句:requires_grad=True。这个tensor上的任何Pytorch的操作都将构造一个计算图,从而允许我们在图中执行反向传播。如果这个tensor的requires_grad=True,那么反向传播之后x.grad将会是另外一个张量,其为关于某个标量值得梯度。
有时不需要构建这样的计算图,例如:在训练神经网络的过程中,通常不希望通过权重更新步骤进行反向传播。在这种情况下,可以使用torch.no_grad()上下文管理器来防止构造计算图——————(其实这些在之前的文章中都有详细的写过[我在这里],就不再赘述了)
下面例子中,使用Pytorch的Tensor和autograd来实现两层的神经网络,不需要再手动执行网络的反向传播:
#%%使用tensor和auto_grad实现两层神经网络
import torch
dtype=torch.float
device=torch.device('cpu')
# device=torch.device('cuda:0')#由GPU的可爱们享受吧,我不配,实验室没有给我高配置的电脑
# n是批量大小,d_in是输入维度
# h是隐藏的维度,d_out是输出维度
n,d_in,h,d_out=64,1000,100,10
# 创建随机输入和输出数据,requires_grad默认设置为False,表示不需要后期微分操作
x=torch.randn(n,d_in,device=device,dtype=dtype)
y=torch.randn(n,d_out,device=device,dtype=dtype)
# 随机初始化权重,requires_grad默认设置为True,表示想要计算其微分
w1=torch.randn(d_in,h,device=device,dtype=dtype,requires_grad=True)
w2=torch.randn(h,d_out,device=device,dtype=dtype,requires_grad=True)
learning_rate=1e-6
for i in range(500):
#前向传播,使用tensor上的操作计算预测值y
# 由于w1和w2的requirea_grad=True,涉及这两个张量的操作可以使pytorch构建计算图
#即允许自动计算梯度,由于不需要手动实现反向传播,所以不需要保存中间值
y_pred=x.mm(w1).clamp(min=0).mm(w2)
#使用tensor中的操作计算损失值,loss.item()得到loss这个张量对应的数值
loss=(y_pred-y).pow(2).sum()
print(i,loss.item())
#使用autograd计算反向传播,这个调用将计算loss对所有的requires_grad=True的tensor梯度,
#调用之后,w1.grad和w2.grad将分别是loss对w1和w2的梯度张量
loss.backward()
#使用梯度下降更新权重,只想对w1和w2的值进行原地改变:不想更新构建计算图
#所以使用torch.no_grad()阻止pytorch更新构建计算图
with torch.no_grad():
w1-=learning_rate*w1.grad
w2-=learning_rate*w2.grad
#反向传播后手动将梯度置零
w1.grad.zero_()
w2.grad.zero_()
运行结果

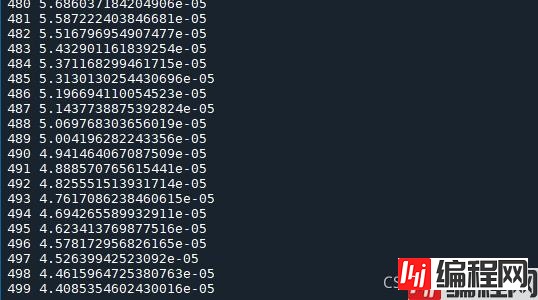
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注编程网的更多内容!
--结束END--
本文标题: Python Pytorch深度学习之核心小结
本文链接: https://lsjlt.com/news/155743.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0