Python 官方文档:入门教程 => 点击学习
自定义函数 import requests from bs4 import BeautifulSoup headers={'User-Agent':'Mozilla/5.0 (w
import requests
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
def baidu(company):
url = 'https://www.baidu.com/s?rtt=4&tn=news&Word=' + company
print(url)
html = requests.get(url, headers=headers).text
s = BeautifulSoup(html, 'html.parser')
title=s.select('.news-title_1YtI1 a')
for i in title:
print(i.text)
# 批量调用函数
companies = ['腾讯', '阿里巴巴', '百度集团']
for i in companies:
baidu(i)
批量输出多个搜索结果的标题
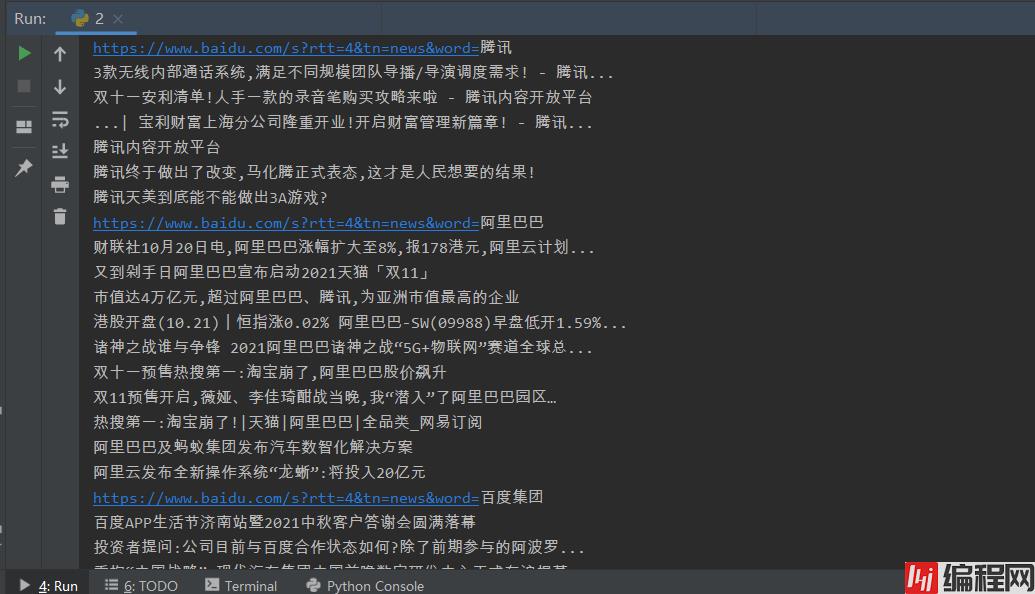
import requests
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
def baidu(company):
url = 'Https://www.baidu.com/s?rtt=4&tn=news&word=' + company
print(url)
html = requests.get(url, headers=headers).text
s = BeautifulSoup(html, 'html.parser')
title=s.select('.news-title_1YtI1 a')
fl=open('test.text','a', encoding='utf-8')
for i in title:
fl.write(i.text + '\n')
# 批量调用函数
companies = ['腾讯', '阿里巴巴', '百度集团']
for i in companies:
baidu(i)
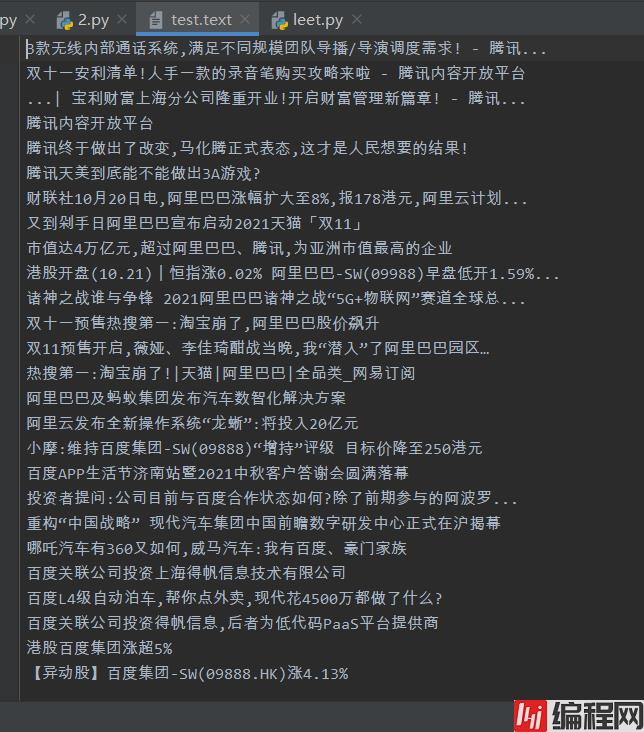
写入代码
fl=open('test.text','a', encoding='utf-8')
for i in title:
fl.write(i.text + '\n')
for i in companies:
try:
baidu(i)
print('运行成功')
except:
print('运行失败')
写在循环中 不会让程序停止运行 而会输出运行失败
import time
for i in companies:
try:
baidu(i)
print('运行成功')
except:
print('运行失败')
time.sleep(5)
time.sleep(5)
括号里的单位是秒
放在什么位置 则在什么位置休眠(暂停)
百度搜索腾讯
切换到第二页
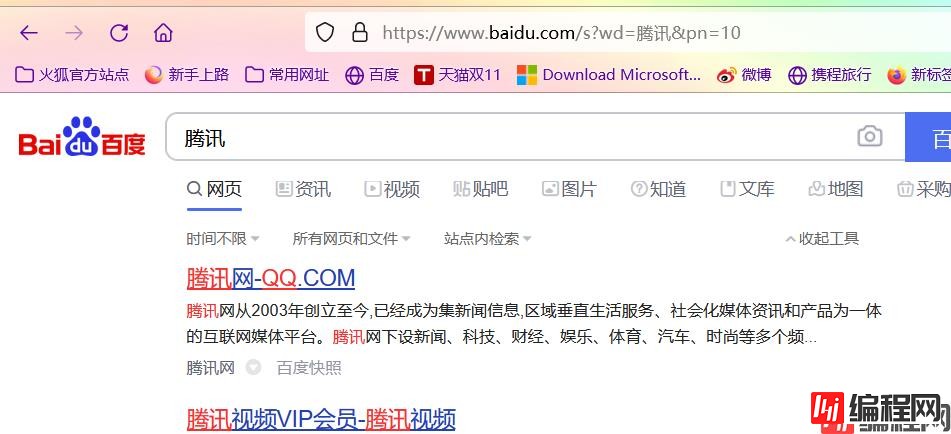
去掉多多余的
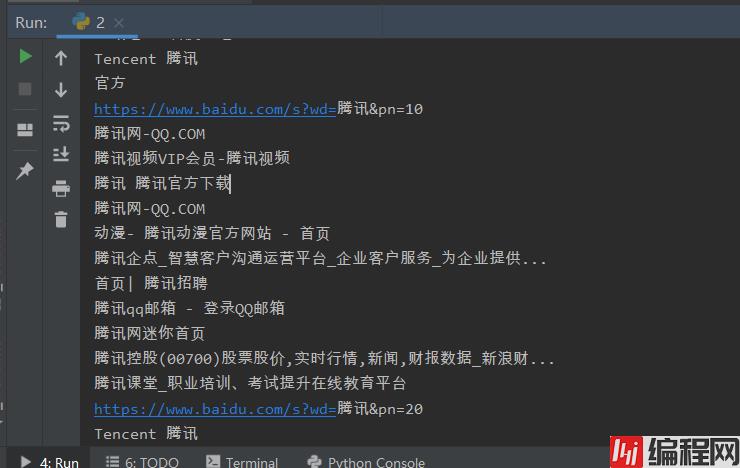
https://www.baidu.com/s?wd=腾讯&pn=10
分析出
https://www.baidu.com/s?wd=腾讯&pn=0 为第一页
https://www.baidu.com/s?wd=腾讯&pn=10 为第二页
https://www.baidu.com/s?wd=腾讯&pn=20 为第三页
https://www.baidu.com/s?wd=腾讯&pn=30 为第四页
..........
from bs4 import BeautifulSoup
import time
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0'}
def baidu(c):
url = 'https://www.baidu.com/s?wd=腾讯&pn=' + str(c)+'0'
print(url)
html = requests.get(url, headers=headers).text
s = BeautifulSoup(html, 'html.parser')
title=s.select('.t a')
for i in title:
print(i.text)
for i in range(10):
baidu(i)
time.sleep(2)
到此这篇关于python爬虫必备技巧详细总结的文章就介绍到这了,更多相关python 爬虫技巧内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python爬虫必备技巧详细总结
本文链接: https://lsjlt.com/news/155121.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0