Python 官方文档:入门教程 => 点击学习
直接上需求和代码 首先是需要爬取的链接和网页:http://211.81.31.34/uhtbin/cgisirsi/x/0/0/57/49?user_id=LIBSCI_ENGI&password
直接上需求和代码
首先是需要爬取的链接和网页:http://211.81.31.34/uhtbin/cgisirsi/x/0/0/57/49?user_id=LIBSCI_ENGI&password=LIBSC
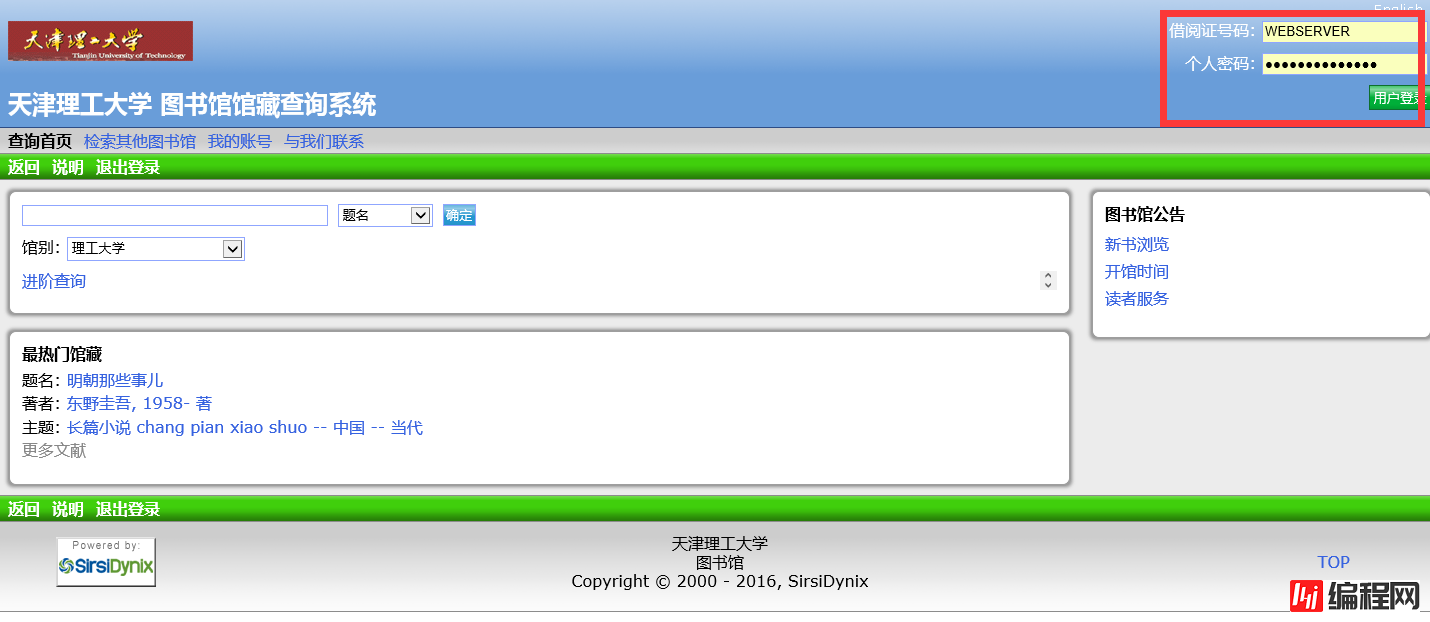
登陆进去之后进入我的账号——借阅、预约及申请记录——借阅历史就可以看到所要爬取的内容
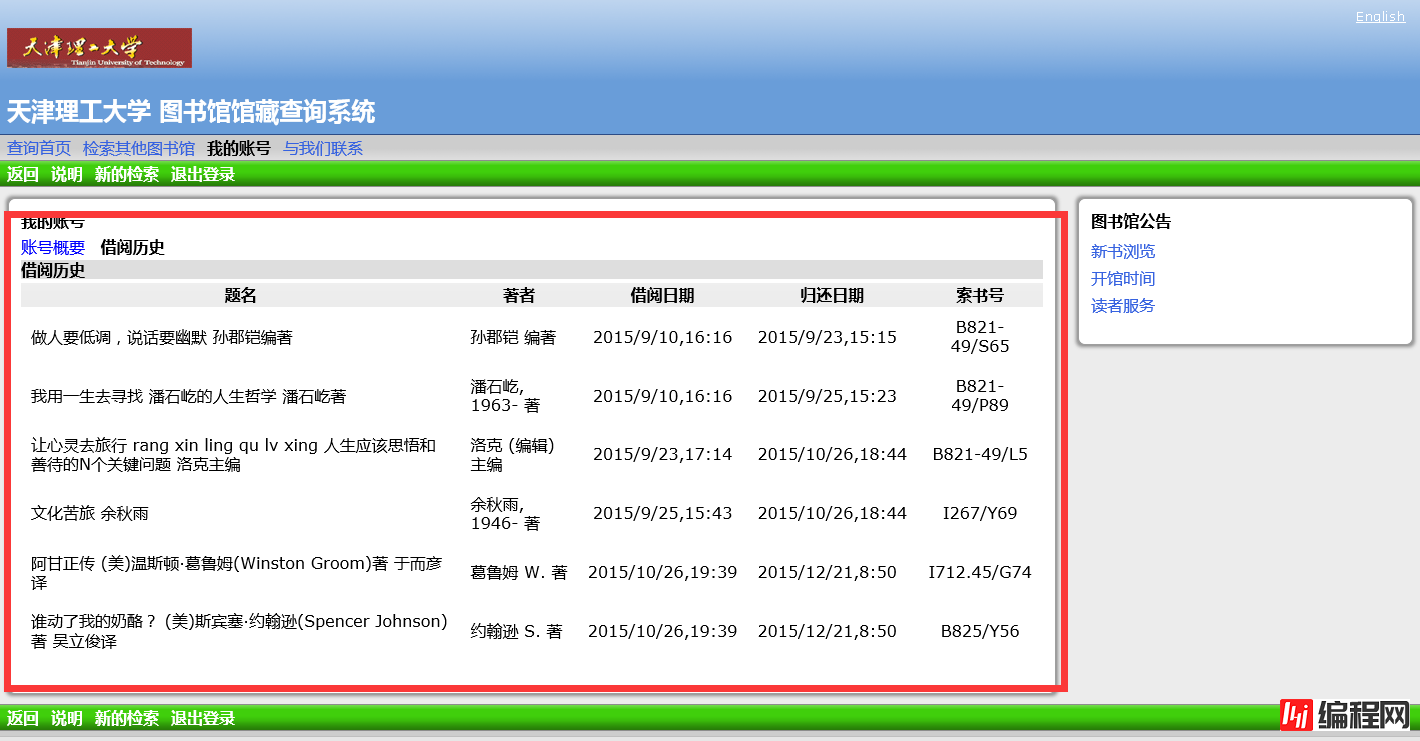
然后将借阅历史中的题名、著者、借阅日期、归还日期、索书号存入mongoDB数据库中,以上便是这次爬虫的需求。
下面开始:
各软件版本为:
python 2.7.11 MongoDb 3.2.1 Pycharm 5.0.4 MongoDb Management Studio 1.9.3 360极速浏览器 懒得查了一、登陆模块
python中的登陆一般都是用urllib和urllib2这两个模块,首先我们要查看网页的源代码:
<fORM name="loginform" method="post" action="/uhtbin/cGISirsi/?ps=npdfje4RP9/理工大学馆/125620449/303">
<!-- Copyright (c) 2004, Sirsi Corporation - myProfile login or view myFavorites -->
<!-- Copyright (c) 1998 - 2003, Sirsi Corporation - Sets the default values for USER_ID, ALT_ID, and PIN prompts. - The USER_ID, ALT_ID, and PIN page variables will be returned. -->
<!-- If the user has not logged in, first try to default to the ID based on the IP address - the $UO and $Uf will be set. If that fails, then default to the IDs in the config file. If the user has already logged in, default to the logged in user's IDs, unless the user is a shared login. -->
<!-- only user ID is used if both on -->
<div class="user_name">
<label for="user_id">借阅证号码:</label>
<input class="user_name_input" type="text" name="user_id" id="user_id" maxlength="20" value=""/>
</div>
<div class="passWord">
<label for="password">个人密码:</label>
<input class="password_input" type="password" name="password" id="password" maxlength="20" value=""/>
</div>
<input type="submit" value="用户登录" class="login_button"/>
查找网页中的form表单中的action,方法为post,但是随后我们发现,该网页中的action地址不是一定的,是随机变化的,刷新一下就变成了下面这样子的:
<form name="loginform" method="post" action="/uhtbin/cgisirsi/?ps=1Nimt5K1Lt/理工大学馆/202330426/303">
我们可以看到/?ps到/之间的字符串是随机变化的(加粗部分),于是我们需要用到另一个模块——BeautifulSoup实时获取该链接:
url = "Http://211.81.31.34/uhtbin/cgisirsi/x/0/0/57/49?user_id=LIBSCI_ENGI&password=LIBSC"
res = urllib2.urlopen(url).read()
soup = BeautifulSoup(res, "html.parser")
login_url = "http://211.81.31.34" + soup.findAll("form")[1]['action'].encode("utf8")
之后就可以正常使用urllib和urllib来模拟登陆了,下面列举一下BeautifulSoup的常用方法,之后的HTML解析需要:
1.soup.contents 该属性可以将tag的子节点以列表的方式输出
2.soup.children 通过tag的.children生成器,可以对tag的子节点进行循环
3.soup.parent 获取某个元素的父节点
4.soup.find_all(name,attrs,recursive,text,**kwargs) 搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件
5.soup.find_all("a",class="xx") 按CSS搜索
6.find(name,attrs,recursive,text,**kwargs) 可以通过limit和find_all区分开
二、解析所获得的HTML
先看看需求中的HTML的特点:
<tbody id="tblSuspensions">
<!-- OCLN changed Listcode to Le to support charge history -->
<!-- SIRSI_List Listcode="LN" -->
<tr>
<td class="accountstyle" align="left">
<!-- SIRSI_Conditional IF List_DC_Exists="IB" AND NOT List_DC_Comp="IB^" -->
<!-- Start title here -->
<!-- Title -->
做人要低调,说话要幽默 孙郡铠编著
</td>
<td class="accountstyle author" align="left">
<!-- Author -->
孙郡铠 编著
</td>
<td class="accountstyle due_date" align="center">
<!-- Date Charged -->
2015/9/10,16:16
</td>
<td class="accountstyle due_date" align="left">
<!-- Date Returned -->
2015/9/23,15:15
</td>
<td class="accountstyle author" align="center">
<!-- Call Number -->
B821-49/S65
</td>
</tr>
<tr>
<td class="accountstyle" align="left">
<!-- SIRSI_Conditional IF List_DC_Exists="IB" AND NOT List_DC_Comp="IB^" -->
<!-- Start title here -->
<!-- Title -->
我用一生去寻找 潘石屹的人生哲学 潘石屹著
</td>
<td class="accountstyle author" align="left">
<!-- Author -->
潘石屹, 1963- 著
</td>
<td class="accountstyle due_date" align="center">
<!-- Date Charged -->
2015/9/10,16:16
</td>
<td class="accountstyle due_date" align="left">
<!-- Date Returned -->
2015/9/25,15:23
</td>
<td class="accountstyle author" align="center">
<!-- Call Number -->
B821-49/P89
</td>
</tr>
由所有代码,注意这行:
<tbody id="tblSuspensions">
该标签表示下面的内容将是借阅书籍的相关信息,我们采用遍历该网页所有子节点的方法获得id="tblSuspensions"的内容:
for i, k in enumerate(BeautifulSoup(detail, "html.parser").find(id='tblSuspensions').children):
# print i,k
if isinstance(k, element.Tag):
bookhtml.append(k)
# print type(k)
三、提取所需要的内容
这一步比较简单,bs4中的BeautifulSoup可以轻易的提取:
for i in bookhtml:
# p
# rint i
name = i.find(class_="accountstyle").getText()
author = i.find(class_="accountstyle author", align="left").getText()
Date_Charged = i.find(class_="accountstyle due_date", align="center").getText()
Date_Returned = i.find(class_="accountstyle due_date", align="left").getText()
bookid = i.find(class_="accountstyle author", align="center").getText()
bookinfo.append(
[name.strip(), author.strip(), Date_Charged.strip(), Date_Returned.strip(), bookid.strip()])
这一步采用getText()的方法将text中内容提取出来;strip()方法是去掉前后空格,同时可以保留之间的空格,比如:s=" a a ",使用s.strip()之后即为"a a"
四、连接数据库
据说NoSQL以后会很流行,随后采用了MonGodb数据库图图新鲜,结果一折腾真是烦,具体安装方法在上一篇日记中记载了。
1.导入Python连接Mongodb的模块
import pymongo
2.创建python和Mongodb的链接:
# connection database
conn = pymongo.MongoClient("mongodb://root:root@localhost:27017")
db = conn.book
collection = db.book
3.将获得的内容保存到数据库:
user = {"_id": xuehao_ben,
"Bookname": name.strip(),
"Author": author.strip(),
"Rent_Day": Date_Charged.strip(),
"Return_Day": Date_Returned.strip()}
j += 1
collection.insert(user)
上面基本完成了,但是爬虫做到这个没有意义,重点在下面
五、获取全校学生的借阅记录
我们学校的图书馆的密码都是一样的,应该没有人闲得无聊改密码,甚至没有人用过这个网站去查询自己的借阅记录,所以,做个循环,就可以轻易的获取到全校的借阅记录了,然后并没有那么简单,str(0001)强制将int变成string,但是在cmd的python中是报错的(在1位置),在PyCharm前面三个0是忽略的,只能用傻瓜式的四个for循环了。好了,下面是所有代码:
# encoding=utf8
import urllib2
import urllib
import pymongo
import Socket
from bs4 import BeautifulSoup
from bs4 import element
# connection database
conn = pymongo.MongoClient("mongodb://root:root@localhost:27017")
db = conn.book
collection = db.book
# 循环开始
def xunhuan(xuehao):
try:
socket.setdefaulttimeout(60)
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(("127.0.0.1", 80))
url = "http://211.81.31.34/uhtbin/cgisirsi/x/0/0/57/49?user_id=LIBSCI_ENGI&password=LIBSC"
res = urllib2.urlopen(url).read()
soup = BeautifulSoup(res, "html.parser")
login_url = "http://211.81.31.34" + soup.findAll("form")[1]['action'].encode("utf8")
params = {
"user_id": "账号前缀你猜你猜" + xuehao,
"password": "密码你猜猜"
}
print params
params = urllib.urlencode(params)
req = urllib2.Request(login_url, params)
lianjie = urllib2.urlopen(req)
# print lianjie
jieyue_res = lianjie.read()
# print jieyue_res 首页的HTML代码
houmian = BeautifulSoup(jieyue_res, "html.parser").find_all('a', class_='rootbar')[1]['href']
# print houmian
houmian = urllib.quote(houmian.encode('utf8'))
url_myaccount = "http://211.81.31.34" + houmian
# print url_myaccount
# print urllib.urlencode(BeautifulSoup(jieyue_res, "html.parser").find_all('a',class_ = 'rootbar')[0]['href'])
lianjie2 = urllib.urlopen(url_myaccount)
myaccounthtml = lianjie2.read()
detail_url = ''
# print (BeautifulSoup(myaccounthtml).find_all('ul',class_='gatelist_table')[0]).children
print "连接完成,开始爬取数据"
for i in (BeautifulSoup(myaccounthtml, "html.parser").find_all('ul', class_='gatelist_table')[0]).children:
if isinstance(i, element.NavigableString):
continue
for ii in i.children:
detail_url = ii['href']
break
detail_url = "http://211.81.31.34" + urllib.quote(detail_url.encode('utf8'))
detail = urllib.urlopen(detail_url).read()
# print detail
bookhtml = []
bookinfo = []
# 解决没有借书
try:
for i, k in enumerate(BeautifulSoup(detail, "html.parser").find(id='tblSuspensions').children):
# print i,k
if isinstance(k, element.Tag):
bookhtml.append(k)
# print type(k)
print "look here!!!"
j = 1
for i in bookhtml:
# p
# rint i
name = i.find(class_="accountstyle").getText()
author = i.find(class_="accountstyle author", align="left").getText()
Date_Charged = i.find(class_="accountstyle due_date", align="center").getText()
Date_Returned = i.find(class_="accountstyle due_date", align="left").getText()
bookid = i.find(class_="accountstyle author", align="center").getText()
bookinfo.append(
[name.strip(), author.strip(), Date_Charged.strip(), Date_Returned.strip(), bookid.strip()])
xuehao_ben = str(xuehao) + str("_") + str(j)
user = {"_id": xuehao_ben,
"Bookname": name.strip(),
"Author": author.strip(),
"Rent_Day": Date_Charged.strip(),
"Return_Day": Date_Returned.strip()}
j += 1
collection.insert(user)
except Exception, ee:
print ee
print "此人没有借过书"
user = {"_id": xuehao,
"Bookname": "此人",
"Author": "没有",
"Rent_Day": "借过",
"Return_Day": "书"}
collection.insert(user)
print "********" + str(xuehao) + "_Finish"+"**********"
except Exception, e:
s.close()
print e
print "socket超时,重新运行"
xunhuan(xuehao)
# with contextlib.closing(urllib.urlopen(req)) as A:
# print A
# print xuehao
# print req
for i1 in range(0, 6):
for i2 in range(0, 9):
for i3 in range(0, 9):
for i4 in range(0, 9):
xueha = str(i1) + str(i2) + str(i3) + str(i4)
chushi = '0000'
if chushi == xueha:
print "=======爬虫开始=========="
else:
print xueha + "begin"
xunhuan(xueha)
conn.close()
print "End!!!"
下面是Mongodb Management Studio的显示内容(部分):
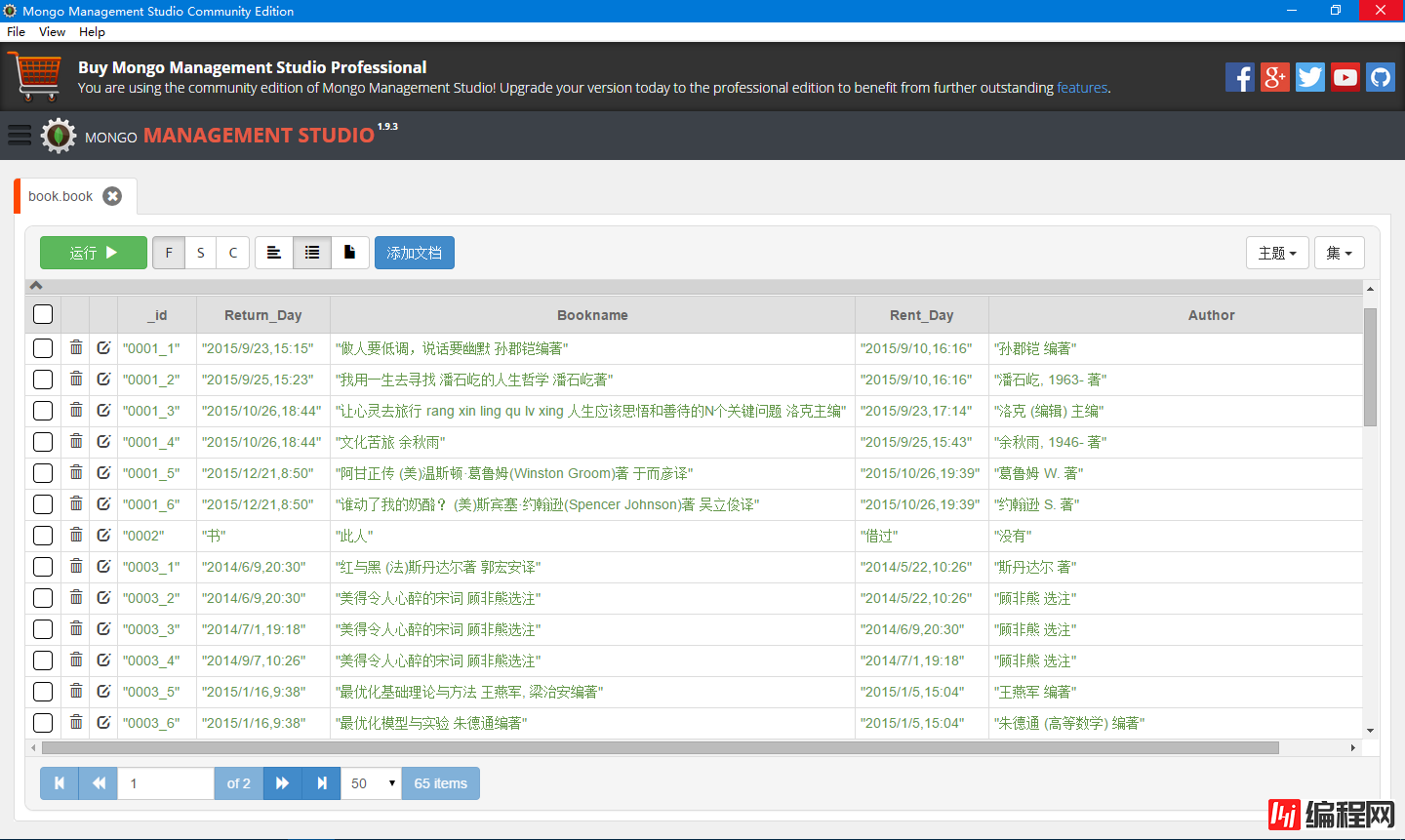
总结:这次爬虫遇到了很多问题,问了很多人,但是最终效果还不是很理想,虽然用了try except语句,但是还是会报错10060,连接超时(我只能质疑学校的服务器了TT),还有就是,你可以看到数据库中列的顺序不一样=。=这个我暂时未理解,希望大家可以给出解决方法。
以上就是本文的全部内容,希望对大家的学习有所帮助。
--结束END--
本文标题: python&MongoDB爬取图书馆借阅记录
本文链接: https://lsjlt.com/news/15426.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0