Python 官方文档:入门教程 => 点击学习
在XML解析方面,python贯彻了自己“开箱即用”(batteries included)的原则。在自带的标准库中,Python提供了大量可以用于处理XML语言的包和工具,数量之多,甚至让Python编程
在XML解析方面,python贯彻了自己“开箱即用”(batteries included)的原则。在自带的标准库中,Python提供了大量可以用于处理XML语言的包和工具,数量之多,甚至让Python编程新手无从选择。
本文将介绍深入解读利用Python语言解析XML文件的几种方式,并以笔者推荐使用的ElementTree模块为例,演示具体使用方法和场景。文中所使用的Python版本为2.7。
一、什么是XML?
XML是可扩展标记语言(Extensible Markup Language)的缩写,其中的 标记(markup)是关键部分。您可以创建内容,然后使用限定标记标记它,从而使每个单词、短语或块成为可识别、可分类的信息。

标记语言从早期的私有公司和政府制定形式逐渐演变成标准通用标记语言(Standard Generalized Markup Language,SGML)、超文本标记语言(Hypertext Markup Language,html),并且最终演变成 XML。XML有以下几个特点。
XML的设计宗旨是传输数据,而非显示数据。 XML标签没有被预定义。您需要自行定义标签。 XML被设计为具有自我描述性。 XML是W3C的推荐标准。目前,XML在WEB中起到的作用不会亚于一直作为Web基石的HTML。 XML无所不在。XML是各种应用程序之间进行数据传输的最常用的工具,并且在信息存储和描述领域变得越来越流行。因此,学会如何解析XML文件,对于web开发来说是十分重要的。
二、有哪些可以解析XML的Python包?
Python的标准库中,提供了6种可以用于处理XML的包。
xml.dom
xml.dom实现的是W3C制定的DOM api。如果你习惯于使用DOM API或者有人要求这这样做,可以使用这个包。不过要注意,在这个包中,还提供了几个不同的模块,各自的性能有所区别。
DOM解析器在任何处理开始之前,必须把基于XML文件生成的树状数据放在内存,所以DOM解析器的内存使用量完全根据输入资料的大小。
xml.dom.minidom
xml.dom.minidom是DOM API的极简化实现,比完整版的DOM要简单的多,而且这个包也小的多。那些不熟悉DOM的朋友,应该考虑使用xml.etree.ElementTree模块。据lxml的作者评价,这个模块使用起来并不方便,效率也不高,而且还容易出现问题。
xml.dom.pulldom
与其他模块不同,xml.dom.pulldom模块提供的是一个“pull解析器”,其背后的基本概念指的是从XML流中pull事件,然后进行处理。虽然与SAX一样采用事件驱动模型(event-driven processing model),但是不同的是,使用pull解析器时,使用者需要明确地从XML流中pull事件,并对这些事件遍历处理,直到处理完成或者出现错误。
pull解析(pull parsing)是近来兴起的一种XML处理趋势。此前诸如SAX和DOM这些流行的XML解析框架,都是push-based,也就是说对解析工作的控制权,掌握在解析器的手中。xml.sax

xml.sax模块实现的是SAX API,这个模块牺牲了便捷性来换取速度和内存占用。SAX是Simple API for XML的缩写,它并不是由W3C官方所提出的标准。它是事件驱动的,并不需要一次性读入整个文档,而文档的读入过程也就是SAX的解析过程。所谓事件驱动,是指一种基于回调(callback)机制的程序运行方法。
xml.parser.expat
xml.parser.expat提供了对C语言编写的expat解析器的一个直接的、底层API接口。expat接口与SAX类似,也是基于事件回调机制,但是这个接口并不是标准化的,只适用于expat库。
expat是一个面向流的解析器。您注册的解析器回调(或handler)功能,然后开始搜索它的文档。当解析器识别该文件的指定的位置,它会调用该部分相应的处理程序(如果您已经注册的一个)。该文件被输送到解析器,会被分割成多个片断,并分段装到内存中。因此expat可以解析那些巨大的文件。
xml.etree.ElementTree(以下简称ET)
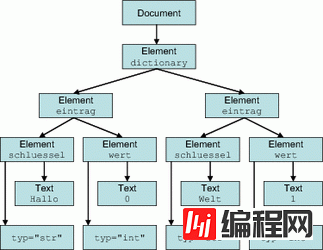
xml.etree.ElementTree模块提供了一个轻量级、Pythonic的API,同时还有一个高效的C语言实现,即xml.etree.cElementTree。与DOM相比,ET的速度更快,API使用更直接、方便。与SAX相比,ET.iterparse函数同样提供了按需解析的功能,不会一次性在内存中读入整个文档。ET的性能与SAX模块大致相仿,但是它的API更加高层次,用户使用起来更加便捷。
笔者建议,在使用Python进行XML解析时,首选使用ET模块,除非你有其他特别的需求,可能需要另外的模块来满足。
解析XML的这几种API并不是Python独创的,Python也是通过借鉴其他语言或者直接从其他语言引入进来的。例如expat就是一个用C语言开发的、用来解析XML文档的开发库。而SAX最初是由DavidMegginson采用java语言开发的,DOM可以以一种独立于平台和语言的方式访问和修改一个文档的内容和结构,可以应用于任何编程语言。下面,我们以ElementTree模块为例,介绍在Python中如何解析lxml。
三、利用ElementTree解析XML
Python标准库中,提供了ET的两种实现。一个是纯Python实现的xml.etree.ElementTree,另一个是速度更快的C语言实现xml.etree.cElementTree。请记住始终使用C语言实现,因为它的速度要快很多,而且内存消耗也要少很多。如果你所使用的Python版本中没有cElementTree所需的加速模块,你可以这样导入模块:
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
如果某个API存在不同的实现,上面是常见的导入方式。当然,很可能你直接导入第一个模块时,并不会出现问题。请注意,自Python 3.3之后,就不用采用上面的导入方法,因为ElemenTree模块会自动优先使用C加速器,如果不存在C实现,则会使用Python实现。因此,使用Python 3.3+的朋友,只需要import xml.etree.ElementTree即可。
1、将XML文档解析为树(tree)
我们先从基础讲起。XML是一种结构化、层级化的数据格式,最适合体现XML的数据结构就是树。ET提供了两个对象:ElementTree将整个XML文档转化为树,Element则代表着树上的单个节点。对整个XML文档的交互(读取,写入,查找需要的元素),一般是在ElementTree层面进行的。对单个XML元素及其子元素,则是在Element层面进行的。下面我们举例介绍主要使用方法。
我们使用下面的XML文档,作为演示数据:
<?xml version="1.0"?>
<doc>
<branch name="codingpy.com" hash="1cdf045c">
text,source
</branch>
<branch name="release01" hash="f200013e">
<sub-branch name="subrelease01">
xml,sgml
</sub-branch>
</branch>
<branch name="invalid">
</branch>
</doc>
接下来,我们加载这个文档,并进行解析:
>>> import xml.etree.ElementTree as ET
>>> tree = ET.ElementTree(file='doc1.xml')然后,我们获取根元素(root element):
>>> tree.getroot()
<Element 'doc' at 0x11eb780>正如之前所讲的,根元素(root)是一个Element对象。我们看看根元素都有哪些属性:
>>> root = tree.getroot()
>>> root.tag, root.attrib
('doc', {})没错,根元素并没有属性。与其他Element对象一样,根元素也具备遍历其直接子元素的接口:
>>> for child_of_root in root:
... print child_of_root.tag, child_of_root.attrib
...
branch {'hash': '1cdf045c', 'name': 'codingpy.com'}
branch {'hash': 'f200013e', 'name': 'release01'}
branch {'name': 'invalid'}
我们还可以通过索引值来访问特定的子元素:
>>> root[0].tag, root[0].text
('branch', 'n text,sourcen ')
2、查找需要的元素
从上面的示例中,可以明显发现我们能够通过简单的递归方法(对每一个元素,递归式访问其所有子元素)获取树中的所有元素。但是,由于这是十分常见的工作,ET提供了一些简便的实现方法。
Element对象有一个iter方法,可以对某个元素对象之下所有的子元素进行深度优先遍历(DFS)。ElementTree对象同样也有这个方法。下面是查找XML文档中所有元素的最简单方法:
>>> for elem in tree.iter():
... print elem.tag, elem.attrib
...
doc {}
branch {'hash': '1cdf045c', 'name': 'codingpy.com'}
branch {'hash': 'f200013e', 'name': 'release01'}
sub-branch {'name': 'subrelease01'}
branch {'name': 'invalid'}
在此基础上,我们可以对树进行任意遍历——遍历所有元素,查找出自己感兴趣的属性。但是ET可以让这个工作更加简便、快捷。iter方法可以接受tag名称,然后遍历所有具备所提供tag的元素:
>>> for elem in tree.iter(tag='branch'):
... print elem.tag, elem.attrib
...
branch {'hash': '1cdf045c', 'name': 'codingpy.com'}
branch {'hash': 'f200013e', 'name': 'release01'}
branch {'name': 'invalid'}
3、支持通过XPath查找元素
使用XPath查找感兴趣的元素,更加方便。Element对象中有一些find方法可以接受Xpath路径作为参数,find方法会返回第一个匹配的子元素,findall以列表的形式返回所有匹配的子元素, iterfind则返回一个所有匹配元素的迭代器(iterator)。ElementTree对象也具备这些方法,相应地它的查找是从根节点开始的。
下面是一个使用XPath查找元素的示例:
>>> for elem in tree.iterfind('branch/sub-branch'):
... print elem.tag, elem.attrib
...
sub-branch {'name': 'subrelease01'}
上面的代码返回了branch元素之下所有tag为sub-branch的元素。接下来查找所有具备某个name属性的branch元素:
>>> for elem in tree.iterfind('branch[@name="release01"]'):
... print elem.tag, elem.attrib
...
branch {'hash': 'f200013e', 'name': 'release01'}
4、构建XML文档
利用ET,很容易就可以完成XML文档构建,并写入保存为文件。ElementTree对象的write方法就可以实现这个需求。
一般来说,有两种主要使用场景。一是你先读取一个XML文档,进行修改,然后再将修改写入文档,二是从头创建一个新XML文档。
修改文档的话,可以通过调整Element对象来实现。请看下面的例子:
>>> root = tree.getroot()
>>> del root[2]
>>> root[0].set('foo', 'bar')
>>> for subelem in root:
... print subelem.tag, subelem.attrib
...
branch {'foo': 'bar', 'hash': '1cdf045c', 'name': 'codingpy.com'}
branch {'hash': 'f200013e', 'name': 'release01'}
在上面的代码中,我们删除了root元素的第三个子元素,为第一个子元素增加了新属性。这个树可以重新写入至文件中。最终的XML文档应该是下面这样的:
>>> import sys
>>> tree.write(sys.stdout)
<doc>
<branch foo="bar" hash="1cdf045c" name="codingpy.com">
text,source
</branch>
<branch hash="f200013e" name="release01">
<sub-branch name="subrelease01">
xml,sgml
</sub-branch>
</branch>
</doc>
请注意,文档中元素的属性顺序与原文档不同。这是因为ET是以字典的形式保存属性的,而字典是一个无序的数据结构。当然,XML也不关注属性的顺序。
从头构建一个完整的文档也很容易。ET模块提供了一个SubElement工厂函数,让创建元素的过程变得很简单:
>>> a = ET.Element('elem')
>>> c = ET.SubElement(a, 'child1')
>>> c.text = "some text"
>>> d = ET.SubElement(a, 'child2')
>>> b = ET.Element('elem_b')
>>> root = ET.Element('root')
>>> root.extend((a, b))
>>> tree = ET.ElementTree(root)
>>> tree.write(sys.stdout)
<root><elem><child1>some text</child1><child2 /></elem><elem_b /></root>
5、利用iterparse解析XML流
XML文档通常都会比较大,如何直接将文档读入内存的话,那么进行解析时就会出现问题。这也就是为什么不建议使用DOM,而是SAX API的理由之一。
我们上面谈到,ET可以将XML文档加载为保存在内存里的树(in-memory tree),然后再进行处理。但是在解析大文件时,这应该也会出现和DOM一样的内存消耗大的问题吧?没错,的确有这个问题。为了解决这个问题,ET提供了一个类似SAX的特殊工具——iterparse,可以循序地解析XML。
接下来,笔者为大家展示如何使用iterparse,并与标准的树解析方式进行对比。我们使用一个自动生成的XML文档,下面是该文档的开头部分:
<?xml version="1.0" standalone="yes"?>
<site>
<regions>
<africa>
<item id="item0">
<location>United States</location> <!-- Counting locations -->
<quantity>1</quantity>
<name>duteous nine eighteen </name>
<payment>Creditcard</payment>
<description>
<parlist>
[...]
我们来统计一下文档中出现了多少个文本值为Zimbabwe的location元素。下面是使用ET.parse的标准方法:
tree = ET.parse(sys.argv[2])
count = 0
for elem in tree.iter(tag='location'):
if elem.text == 'Zimbabwe':
count += 1
print count
上面的代码会将全部元素载入内存,逐一解析。当解析一个约100MB的XML文档时,运行上面脚本的Python进程的内存使用峰值为约560MB,总运行时间问2.9秒。
请注意,我们其实不需要讲整个树加载到内存里。只要检测出文本为相应值得location元素即可。其他数据都可以废弃。这时,我们就可以用上iterparse方法了:
count = 0
for event, elem in ET.iterparse(sys.argv[2]):
if event == 'end':
if elem.tag == 'location' and elem.text == 'Zimbabwe':
count += 1
elem.clear() # 将元素废弃
print count
上面的for循环会遍历iterparse事件,首先检查事件是否为end,然后判断元素的tag是否为location,以及其文本值是否符合目标值。另外,调用elem.clear()非常关键:因为iterparse仍然会生成一个树,只是循序生成的而已。废弃掉不需要的元素,就相当于废弃了整个树,释放出系统分配的内存。
当利用上面这个脚本解析同一个文件时,内存使用峰值只有7MB,运行时间为2.5秒。速度提升的原因,是我们这里只在树被构建时,遍历一次。而使用parse的标准方法是先完成整个树的构建后,才再次遍历查找所需要的元素。
iterparse的性能与SAX相当,但是其API却更加有用:iterparse会循序地构建树;而利用SAX时,你还得自己完成树的构建工作。
以上就是为大家分享的Python解析XML的几种方式,希望对大家的学习有所帮助。
--结束END--
本文标题: 深入解读Python解析XML的几种方式
本文链接: https://lsjlt.com/news/15386.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0