目录1 sql去重2 distinct3 group by1. 查询根据名字去重后数据(名字相同取id值大的)2. 删除名字相同数据(名字相同保留id值大的)4 总结1 SQL去重
SQL中去除完全相同数据可以用distinct关键字,任意字段去重可以用group by,以下面的数据表为例。
存在两条完全相同的纪录,用关键字distinct就可以去掉
根据单个字段去重,能精确去重;
作用在多个字段时,只有当这几个字段的完全相同时,才能去重;
关键字distinct只能放在SQL语句中的第一个,才会起作用
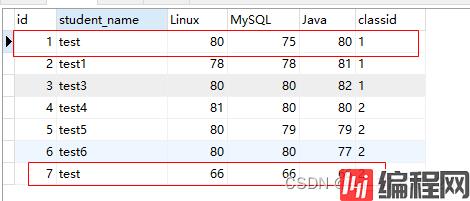

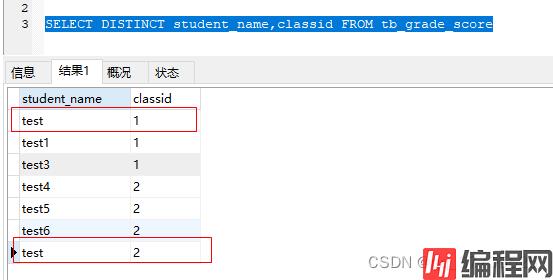
一般用来返回不重复的记录条数,返回不重复的条数(去掉test重复的,就剩下6条)

SELECT * FROM stu WHERE id IN (SELECT MAX(id) FROM stu GROUP BY `name`)

group by + count + max去掉重复数据
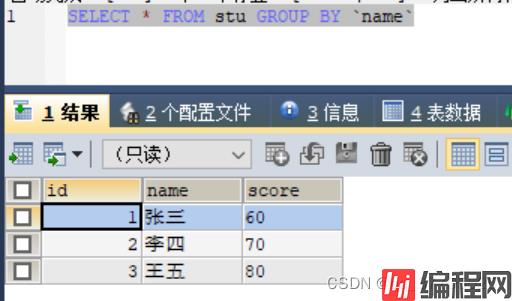
1)SELECT * FROM stu

2)加上group by 后,会将重复的数据去掉了
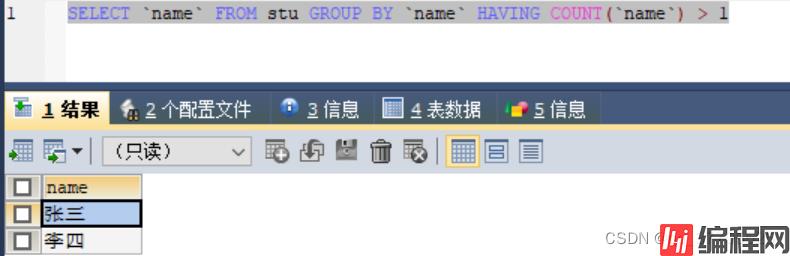
3) 条件(名字)是数量大于1的重复数据
SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(`name`) > 1
#条件是数量大于1的重复数据
SELECT * FROM stu WHERE `name` IN(
SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(`name`)>1
)
4)查看某字段重复数据的id
SELECT id, COUNT(*) FROM stu
GROUP BY NAME DESC HAVING(COUNT(*) > 0)
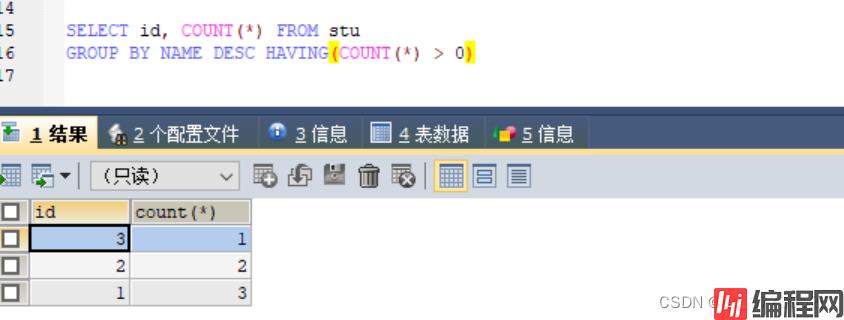
5)查询所有重复数据
SELECT * FROM stu WHERE NAME IN (SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(`name`) > 1)
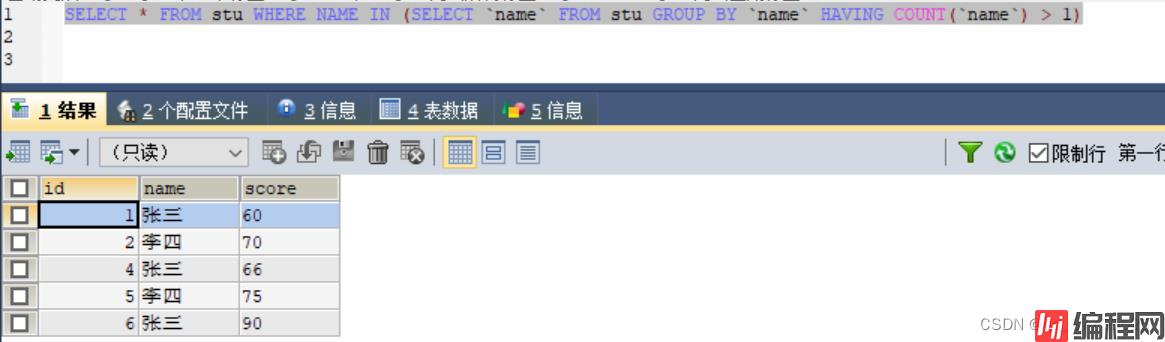
5) 去重
可以使用distinct去重(返回不重复的用户名)
删除多余的重复记录(name),只保留id最大的记录。
DELETE FROM stu
WHERE id NOT IN ( SELECT a.id FROM ( SELECT MAX( id ) AS id FROM stu GROUP BY `name` )a )
或者
DELETE FROM stu WHERE `name` IN (SELECT `name` FROM (SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(`name`)>1) e)
AND id NOT IN (SELECT id FROM (SELECT MAX(id) AS id FROM stu GROUP BY `name` HAVING COUNT(`name`)>1) t)
#查询显示重复的数据都是显示最前面的几条,因此不需要查询是否最小值
错误删除
DELETE FROM stu WHERE name IN (SELECT name FROM stu GROUP BY name HAVING COUNT(name)>1)
AND id NOT IN (SELECT MAX(id) FROM stu GROUP BY stu HAVING COUNT(name)>1)
原因是:不能将直接查处来的数据当做删除数据的条件,我们应该先把查出来的数据新建一个临时表,然后再把临时表作为条件进行删除功能
去重后名字记录
SELECT `name` FROM stu
GROUP BY NAME HAVING(COUNT(*) > 0)
2)
所有重复名字的记录
SELECT `name` FROM stu
GROUP BY NAME HAVING COUNT(*) > 1
3)把所有重复的记录都删了
DELETE FROM stu WHERE
nameIN
(SELECTnameFROM stu GROUP BYnameHAVING COUNT(*)>1)

无法在删除时同时查询这张表,这个问题只在Mysql中出现,oracle没有。怎么解决?我们只需要在查出结果以后加一张中间表。让执行器认为我们要查的数据不是来自正在删的这张表就可以了。
DELETE FROM stu WHERE `name` IN
(SELECT a.name FROM
(SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(*)>1) a)
所有重复数据都删除, 就剩王五一条数据了
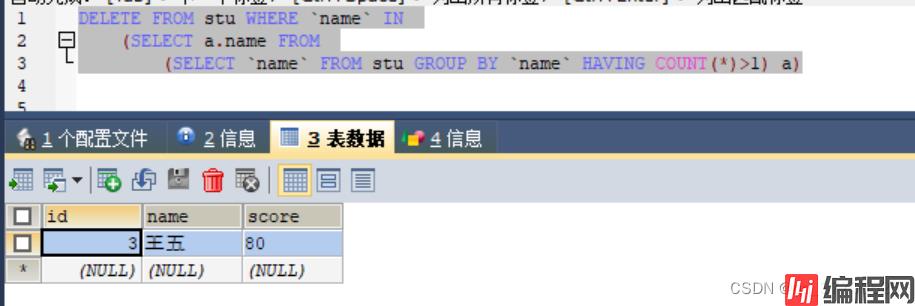
4) 现在删除所有重复数据数据做完了,考虑怎么保留重复数据中id最小的。只需要在删除时让删除该条的记录id不在重复数据id最小的当中就可以了。
DELETE FROM stu WHERE `name` IN
(SELECT a.name FROM
(SELECT `name` FROM stu GROUP BY `name` HAVING COUNT(*)>1) a)
AND id NOT IN
(SELECT b.id FROM
(SELECT MIN(id) id FROM stu
GROUP BY `name` HAVING COUNT(*)>1) b);

还有简单办法 算出去重后所有数据(保留最小ID),然后删除id不在该数组里的
DELETE FROM stu WHERE id NOT IN (SELECT t.id FROM (SELECT MIN(id) AS id FROM stu GROUP BY `name`)t)
到此这篇关于SQL删除重复数据的文章就介绍到这了,更多相关SQL删除重复数据内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: SQL删除重复数据的实例教程
本文链接: https://lsjlt.com/news/153507.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0