目录前言什么是浏览器缓存优点强缓存ExpiresCache-Control协商缓存Last-Modified、If-Modified-SinceETag、If-None-Matchn
浏览器缓存是性能优化非常重要的一个方案,合理地使用缓存可以提高用户体验,还能节省服务器的开销。掌握好缓存的原理和并合理地使用无论对前端还是运维都是相当重要的。
浏览器缓存(Http 缓存) 是指浏览器在本地磁盘对用户最近请求过的文档进行存储,当访问者再次访问同一页面时,浏览器就可以直接从本地磁盘加载文档。
减少了冗余的数据传输,节省带宽,减少服务器压力
加快了客户端加载速度,提升用户体验。
强缓存不会向服务器发送请求,而是直接从缓存中读取资源,强缓存可以通过设置两种 HTTP Header 实现:Expires 和 Cache-Control,这两个头部分别是HTTP1.0和HTTP1.1的实现。
Expires是HTTP1.0提出的一个表示资源过期时间的header,它描述的是一个绝对时间,由服务器返回。
Expires 受限于本地时间,如果修改了本地时间,就会造成缓存失效。
Cache-Control 出现于 HTTP/1.1,常见字段是max-age,单位是秒,很多WEB服务器都有默认配置,优先级高于Expires,表示的是相对时间。
例如Cache-Control:max-age=3600 代表资源的有效期是 3600 秒。取的是响应头中的 Date,请求发送的时间,表示当前资源在 Date ~ Date +3600s 这段时间里都是有效的。Cache-Control 还拥有多个值:
要注意的就是no-cache和no-store的区别,no-cache是跳过强缓存,还是会走协商缓存的步骤,而no-store是真正的完全不走缓存,所有资源都不会缓存在本地
当浏览器对某个资源的请求没有命中强缓存,就会发一个请求到服务器,验证协商缓存是否命中,如果协商缓存命中,请求响应返回的http状态为304并且会显示一个Not Modified的字符串。
协商缓存用的是【Last-Modified,If-Modified-Since】和【ETag、If-None-Match】这两对Header来管理的。
注意!!协商缓存需要配合强缓存使用,使用协商缓存需要先设置Cache-Control:no-cache或者pragma:no-cache来告诉浏览器不走强缓存
这两个Header是HTTP1.0版本提出来的,两个字段配合使用。
Last-Modified 表示本地文件最后修改日期,浏览器会在请求头带上If-Modified-Since(上次返回的Last-Modified的值),服务器会将这个值与资源修改的时间匹配,如果时间不一致,服务器会返回新的资源,并且将 Last-Modified 值更新,作为响应头返回给浏览器。如果时间一致,表示资源没有更新,服务器返回 304 状态码,浏览器拿到响应状态码后从本地缓存中读取资源。
但Last-Modified有几个问题。
所以出现了ETAG。
在HTTP1.1版本中,服务器通过 Etag 来设置响应头缓存标识。Etag 的值由服务端生成。在第一次请求时,服务器会将资源和 Etag 一并返回给浏览器,浏览器将两者缓存到本地缓存数据库。在第二次请求时,浏览器会将 Etag 信息放到 If-None-Match 请求头去访问服务器,服务器收到请求后,会将服务器中的文件标识与浏览器发来的标识进行对比,如果不相同,服务器返回更新的资源和新的 Etag ,如果相同,服务器返回 304 状态码,浏览器读取缓存。
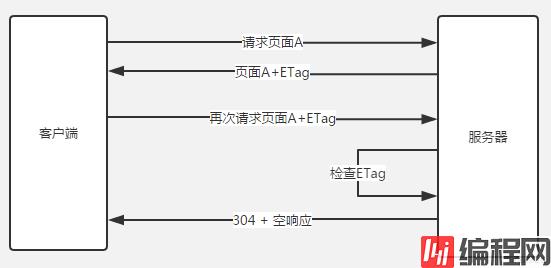
流程总结
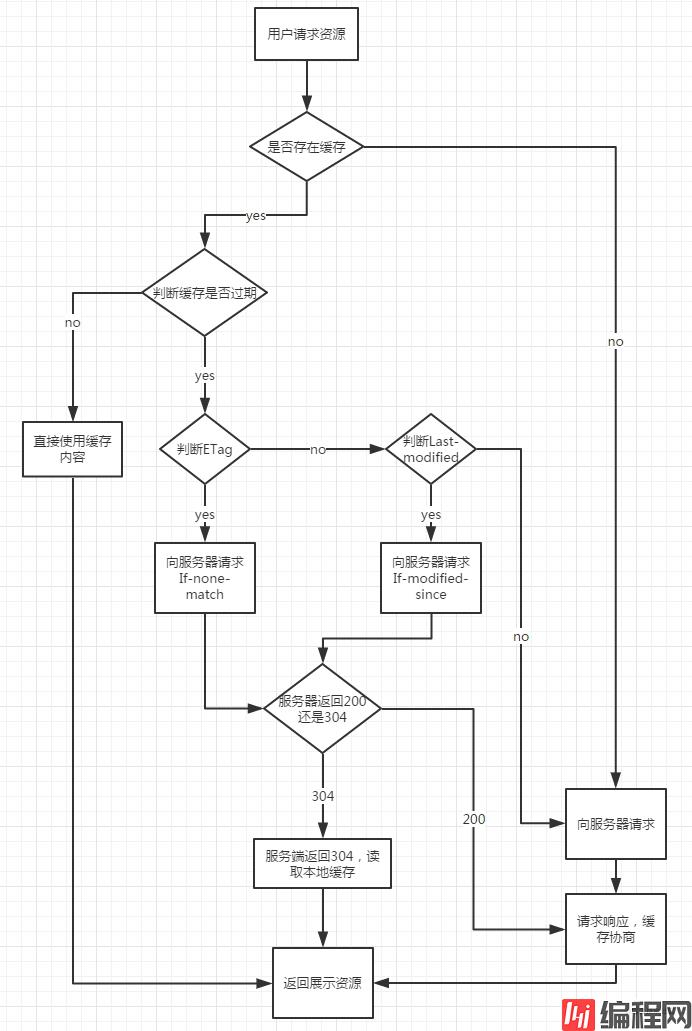
总结这几个字段:
本文用koa来做例子,因为koa是更轻量级的、更纯净的,本身并没有捆绑任何中间件,相比express自带了很多router、static等多种中间件函数,koa更适合本文来做示例。
秉着学习和更容易理解的宗旨,不使用koa-static和koa-router中间件,用koa简易实现web服务器来验证之前的结论。
# 创建并进入一个目录并新建index.js文件
mkdir koa-cache
cd koa-cache
touch index.js
# 初始化项目
git init
yarn init
# 将 koa 安装为本地依赖
yarn add koa
const Koa = require('koa')
const app = new Koa()
app.use(async (ctx) => {
ctx.body = 'hello koa'
})
app.listen(3000, () => {
console.log('starting at port 3000')
})
node index.js这样一个koa服务就起来了,访问localhost:3000可以就看到hello koa。
为了方便调试,修改代码不用重新启动,推荐使用nodemon或者pm2启动服务。
实现一个静态资源服务器关键点就是根据前端请求的地址来判断请求的资源类型,设置返回的Content-Type,让浏览器知道返回的内容类型,浏览器才能决定以什么形式,什么编码来读取返回的内容。
const mimes = {
CSS: 'text/css',
less: 'text/css',
gif: 'image/gif',
html: 'text/html',
ico: 'image/x-icon',
jpeg: 'image/jpeg',
jpg: 'image/jpeg',
js: 'text/javascript',
JSON: 'application/json',
pdf: 'application/pdf',
png: 'image/png',
svg: 'image/svg+xml',
swf: 'application/x-shockwave-flash',
tiff: 'image/tiff',
txt: 'text/plain',
wav: 'audio/x-wav',
wma: 'audio/x-ms-wma',
wmv: 'video/x-ms-wmv',
xml: 'text/xml',
}
function parseMime(url) {
// path.extname获取路径中文件的后缀名
let extName = path.extname(url)
extName = extName ? extName.slice(1) : 'unknown'
return mimes[extName]
}
const parseStatic = (dir) => {
return new Promise((resolve) => {
resolve(fs.readFileSync(dir), 'binary')
})
}
app.use(async (ctx) => {
const url = ctx.request.url
if (url === '/') {
// 访问根路径返回index.html
ctx.set('Content-Type', 'text/html')
ctx.body = await parseStatic('./index.html')
} else {
ctx.set('Content-Type', parseMime(url))
ctx.body = await parseStatic(path.relative('/', url))
}
})
这样基本也就完成了一个简单的静态资源服务器。然后在根目录下新建一个html文件和static目录,并在static下放一些文件。这时候的目录应该是这样的:
|-- koa-cache
|-- index.html
|-- index.js
|-- static
|-- css
|-- color.css
|-- ...
|-- image
|-- soldier.png
|-- ...
...
...这时候就可以通过localhost:3000/static访问具体的资源文件了。
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>test cache</title>
<link rel="stylesheet" href="/static/css/index.css" rel="external nofollow" />
</head>
<body>
<div id="app">测试css文件</div>
<img src="/static/image/soldier.png" alt="" />
</body>
</html>
css/color.css
#app {
color: blue;
}
这时候打开localhost:3000,就能看到如下效果:

到这里基本的环境就都搭好了。接下来进入验证阶段。
在没有任何配置之前,可以看下network:
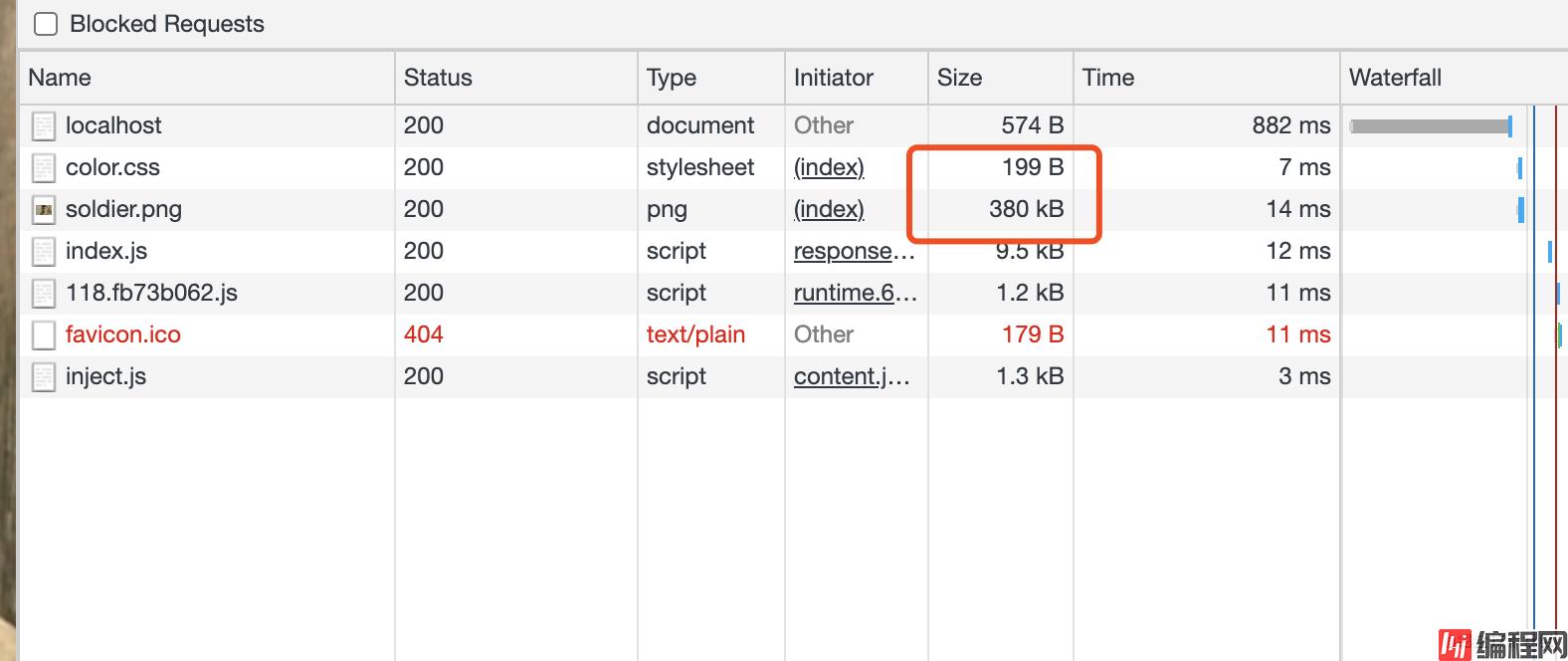
这时候无论是首次还是第几次,都会向服务器请求资源。
注意!!!在开始实验之前要把network面板的Disable cache勾选去掉,这个选项表示禁用浏览器缓存,浏览器请求会带上Cache-Control: no-cache和Pragma: no-cache头部信息,这时候所有的请求都不会走缓存
修改index.js中的app.use代码段。
app.use(async (ctx) => {
const url = ctx.request.url
if (url === '/') {
// 访问根路径返回index.html
ctx.set('Content-Type', 'text/html')
ctx.body = await parseStatic('./index.html')
} else {
const filePath = path.resolve(__dirname, `.${url}`)
ctx.set('Content-Type', parseMime(url))
// 设置过期时间在30000毫秒,也就是30秒后
ctx.set('Expires', new Date(Date.now() + 30000))
ctx.body = await parseStatic(filePath)
}
})
用ctx.set(‘Expires’, new Date(Date.now() + 30000)),设置过期时间为当期时间的30000毫秒,也就是30秒后(后面的设置头部信息都是这里修改)。
再访问下localhost:3000,可以看到多了Expires这个Header。
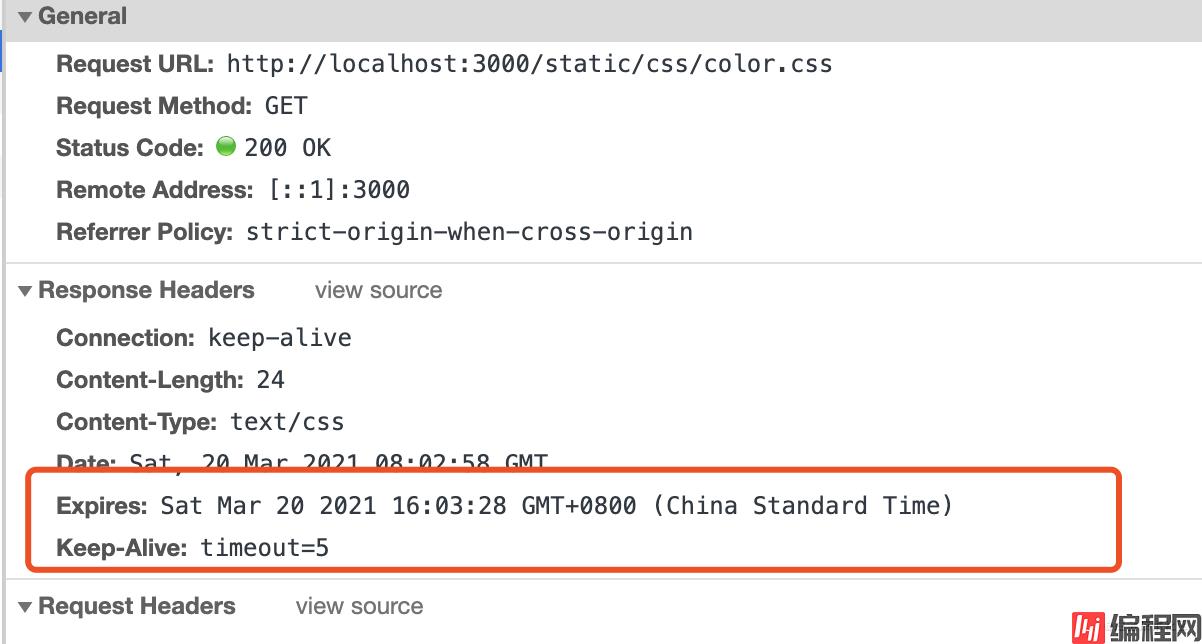
后面在30秒之内访问都可以看到network的Size,css文件显示的是disk cache,而image资源显示的是from memory cache。这时候浏览器是直接读的浏览器缓存,并没有请求服务器,可以尝试把css和图片文件改名称或者删除验证下,页面显示正常,说明之前的结论是没错的。
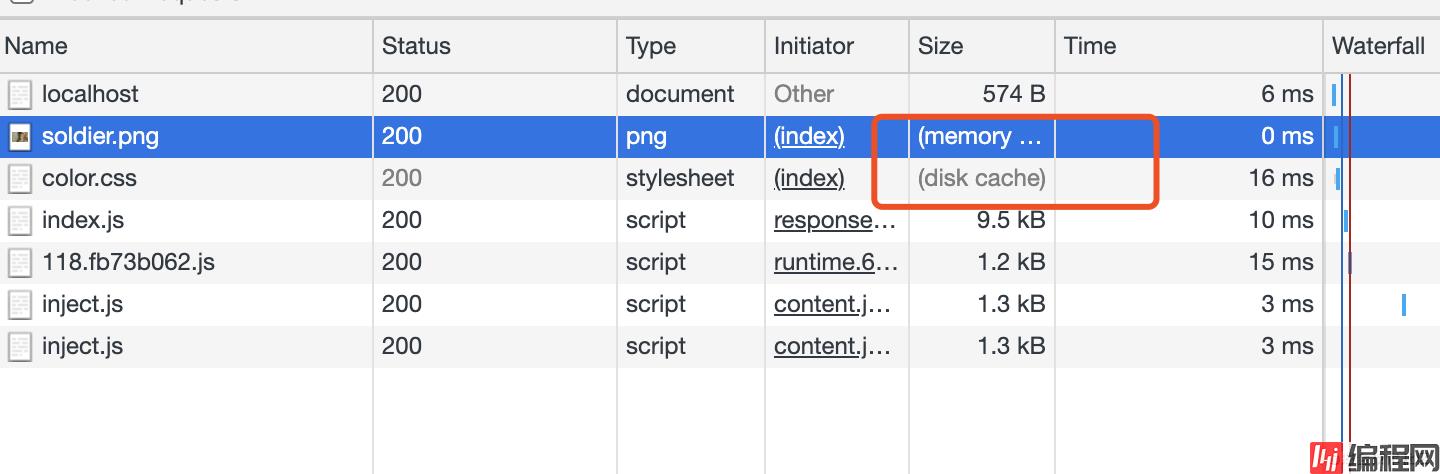
ctx.set(‘Cache-Control’, ‘max-age=300’)设置300秒有效期,验证方式同上。
HTTP1.0协商缓存关键点就是根据客户端请求带的ifModifiedSince字段的时间和请求的资源对应的修改时间来判断资源是否有更新。
首先设置Cache-Control: no-cache, 使客户端不走强缓存,再判断客户端请求是否有带ifModifiedSince字段,没有就设置Last-Modified字段,并返回资源文件。如果有就用fs.stat读取资源文件的修改时间,并进行对比,如果时间一样,则返回状态码304。
ctx.set('Cache-Control', 'no-cache')
const ifModifiedSince = ctx.request.header['if-modified-since']
const fileStat = await getFileStat(filePath)
if (ifModifiedSince === fileStat.mtime.toGMTString()) {
ctx.status = 304
} else {
ctx.set('Last-Modified', fileStat.mtime.toGMTString())
ctx.body = await parseStatic(filePath)
}
etag的关键点在于计算资源文件的唯一性,这里使用nodejs内置的crypto模块来计算文件的hash值,并用十六进制的字符串表示。cypto的用法可以看nodejs的官网。
crpto不仅支持字符串的加密,还支持传入buffer加密,作为nodejs的内置模块,在这里用来计算文件的唯一标识再合适不过。
ctx.set('Cache-Control', 'no-cache')
const fileBuffer = await parseStatic(filePath)
const ifNoneMatch = ctx.request.headers['if-none-match']
const hash = crypto.createHash('md5')
hash.update(fileBuffer)
const etag = `"${hash.digest('hex')}"`
if (ifNoneMatch === etag) {
ctx.status = 304
} else {
ctx.set('etag', etag)
ctx.body = fileBuffer
}
效果如下图,第二次请求浏览器会带上If-None-Match,服务器计算文件的hash值再次比较,相同则返回304,不同再返回新的文件。而如果修改了文件,文件的hash值也就变了,这时候两个hash不匹配,服务器则返回新的文件并带上新文件的hash值作为etag。
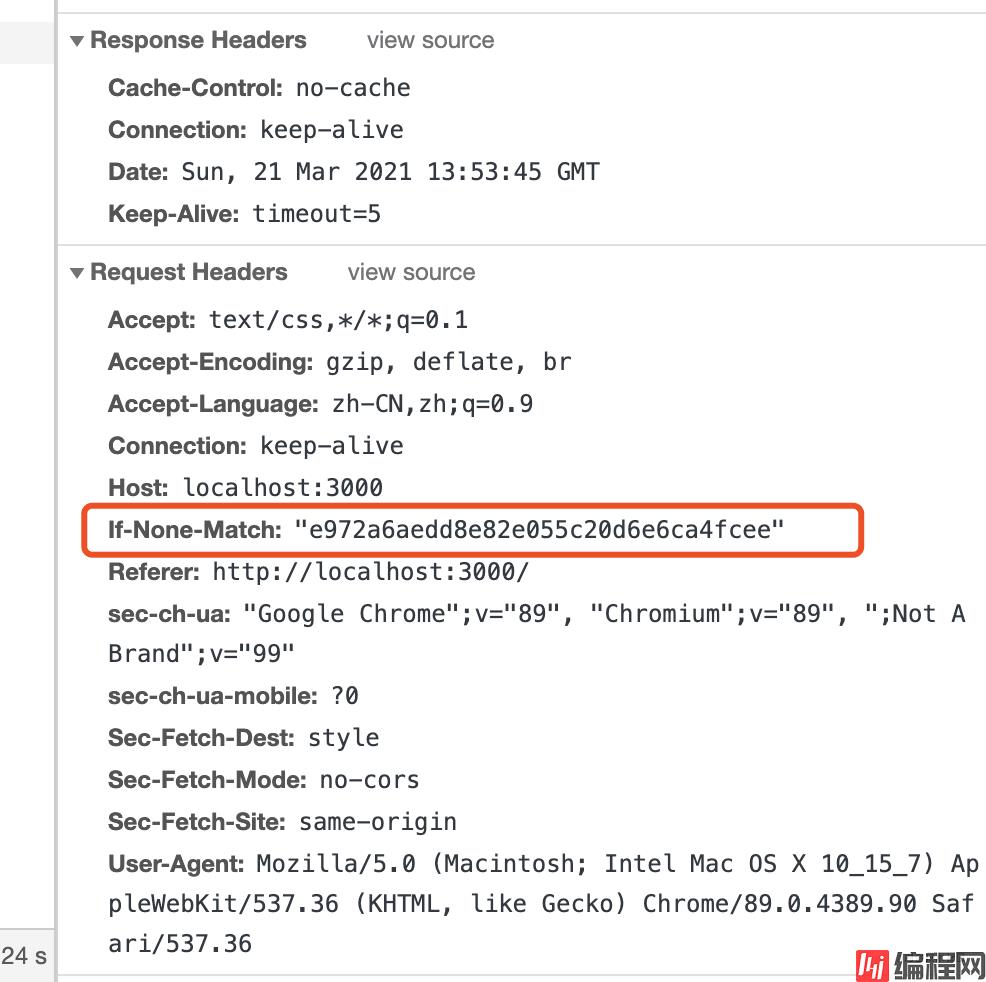
通过以上代码实践了每个缓存字段的效果,代码仅作为演示,生产的静态资源服务器会更加复杂,例如etag不会每次都重新获取文件来计算文件的hash值,这样太费性能,一般都会有响应的缓存机制,比如对资源的 last-modified 和 etag 值建立索引缓存。
通常web服务器都有默认的缓存配置,具体的实现可能也不大相同,像Nginx、Tomcat、express等web服务器都有相应的源码,有兴趣的可以去阅读学习。
合理的使用强缓存和协商缓存具体需要看项目的使用场景和需求。像目前常见的单页面应用,因为通常打包都是新生成html与相应的静态资源依赖,所以可以对html文件配置协商缓存,而打包生成的依赖,例如js、css这些文件可以使用强缓存。或者只对第三方库使用强缓存,因为第三方库通常版本更新较慢,可以锁定版本。
node示例完整代码 https://GitHub.com/chen-junyi/code/blob/main/node/cache/koa2.js
以上就是node强缓存和协商缓存实战示例的详细内容,更多关于node强缓存协商缓存的资料请关注编程网其它相关文章!
--结束END--
本文标题: node强缓存和协商缓存实战示例
本文链接: https://lsjlt.com/news/153422.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-01-12
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
2023-05-20
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0