Python 官方文档:入门教程 => 点击学习
目录前言垃圾收集器类型1. Serial收集器1.1 定义1.2 优点1.3 使用的垃圾收集算法1.4 应用场景1.5 工作流程2. Serial Old收集器2.1 定义2.2 优
垃圾收集器 是 垃圾收集算法 的具体实现
本文将对市面上常见的垃圾收集器类型进行讲解,希望你们会喜欢
垃圾收集器 是 垃圾收集算法 的具体实现
现在主流的垃圾收集器有 7 种:
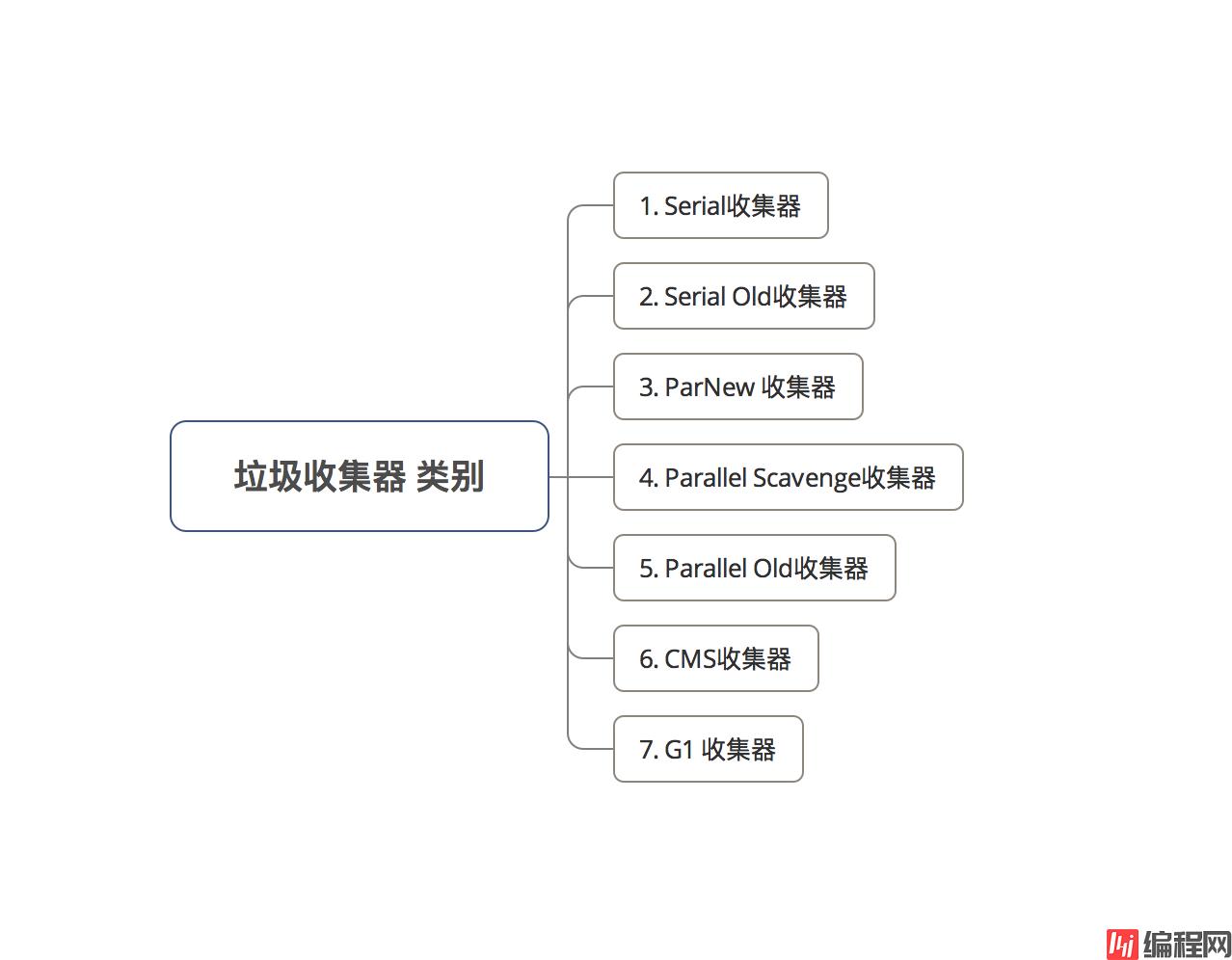
我们会根据需求场景的不同,选择不同特点的垃圾收集器
下面我会详细介绍。
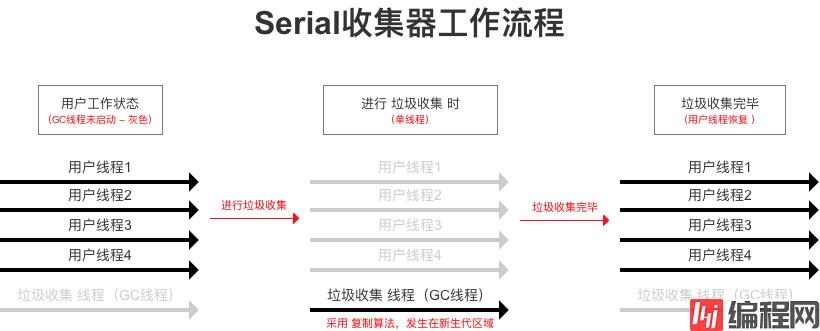
最基本、发展历史最长的垃圾收集器
暂停工作线程 是在用户不可见的情况下进行
注:并发 与 并行的区别 a. 并发:在 某一时段内,交替执行多个任务(即先处理A再处理B,循环该过程) b. 并行:在 某一时刻内,同时执行多个任务(即同时处理A、B)
GC线程)CPU环境来说,Serial收集器没有线程交互开销(专一做垃圾收集),拥有更高的单线程收集效率。垃圾收集高效,即其他工作线程停顿时间短(可控制在100ms内),只要垃圾收集发生的频率不高,完全可以接受。
复制 算法
客户端模式下,虚拟机的 新生代区域
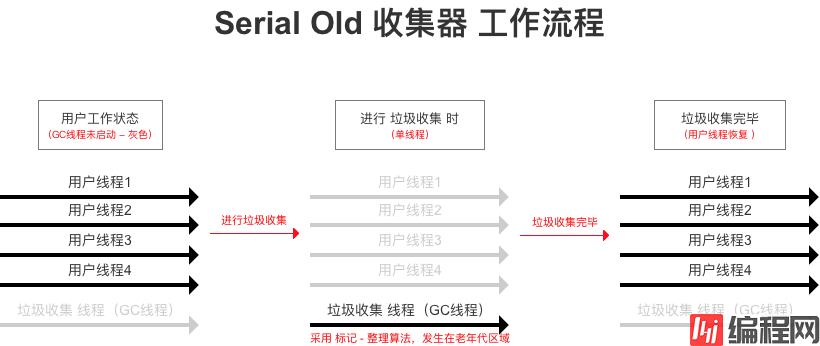
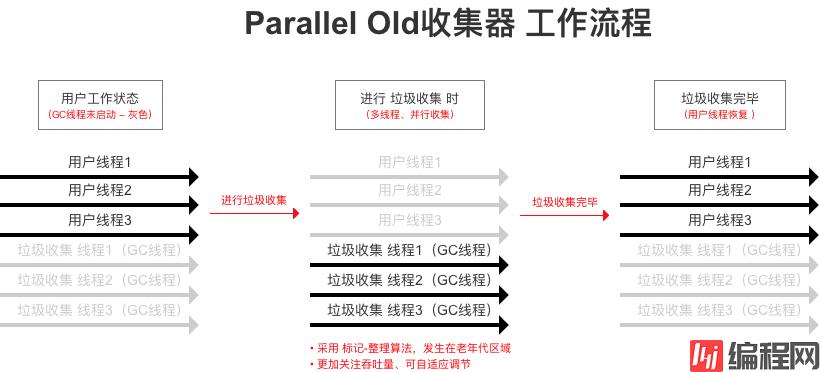
Serial收集器 应用在老年代区域 的版本
并发、单线程、效率高
同Serial收集器,此处不作过多描述
标记-整理 算法
与 Parallel Scavenge 收集器搭配使用
作为CMS收集器的后备预案,在并发收集发生Concurrent Mode Failure时使用
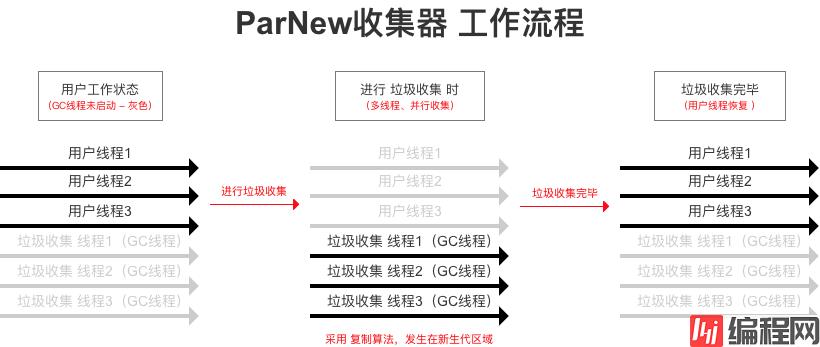
Serial收集器 的 多线程 版本。
Stop The World),直到收集结束。暂停工作线程 是在用户不可见的情况下进行
GC线程) 完成垃圾收集由于存在线程交互的开销,所以在单CPU环境下,性能差于 Serial收集器
CMS收集器配合工作 目前,只有ParNew 收集器能与 CMS收集器 配合工作CMS收集器使用广泛,所以该特点非常重要。CMS收集器 下面会详细说明复制 算法
服务器模式下,虚拟机的 新生代区域
多线程收集
ParNew 收集器的升级版
Parallel Scavenge收集器的目标则是:达到 可控制吞吐量CPU用于运行用户代码的时间 与 CPU总消耗时间(运行用户代码时间+垃圾收集时间)的比值该特性称为:GC 自适应的调节策略
这是Parallel Scavenge收集器与 ParNew 收集器 最大的区别
复制 算法
服务器模式下,虚拟机的 新生代区域
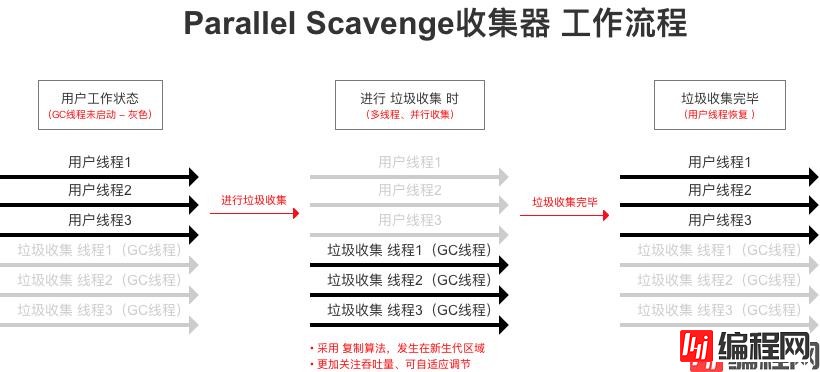
Parallel Scavenge收集器 应用在老年代区域 的版本
以达到 可控制吞吐量 为目标、自适应调节、多线程收集
同Parallel Scavenge收集器
标记-整理 算法
服务器模式下,虚拟机的 老年代区域
即Concurrent Mark Sweep,基于 标记-清除算法的收集器
并行 用户线程 & 垃圾收集线程同时进行。
即在进行垃圾收集时,用户还能工作。
CPU资源非常敏感,在并发阶段,虽不会导致用户线程停顿,但会因为占用部分线程(CPU资源)而导致应用程序变慢,总吞吐量会降低因为这一部分垃圾出现在标记过程之后,所以CMS无法在当次GC中处理掉它们
因此,CMS无法等到老年代被填满再进行Full GC,CMS需要预留一部分空间。即所谓的:可能出现Concurrent Mode Failure失败而导致另一次Full GC产生。
垃圾收集后会产生大量内存空间碎片 因为 CMS收集器是基于“标记-清除”算法的。
标记-清除 算法
重视应用的响应速度、希望系统停顿时间最短的场景
如互联网移动端应用
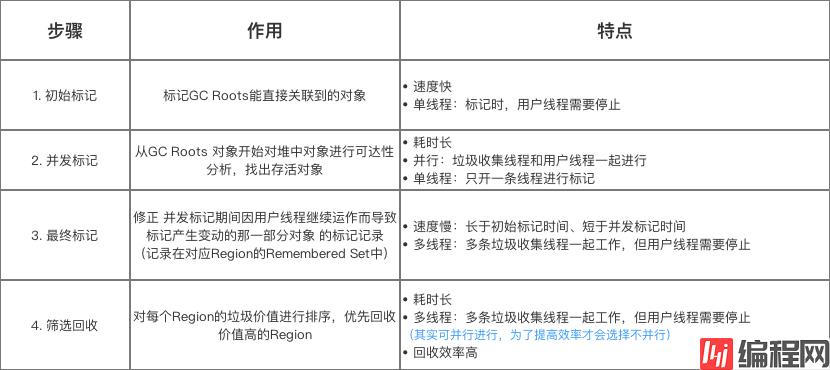
CMS 收集器 是基于 标记-清除算法实现的收集器,工作流程较为复杂:(分为四个步骤)
初始标记
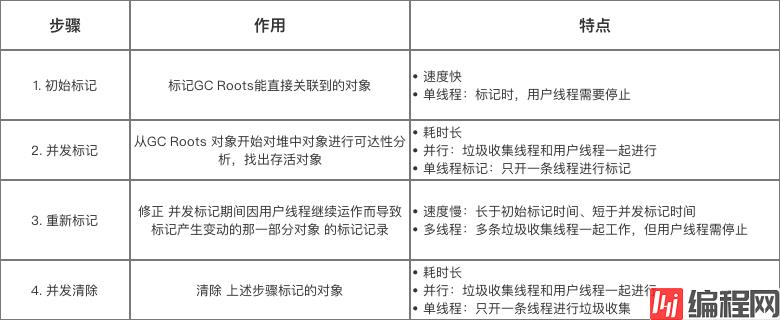
下面用一张图详细说明工作流程:
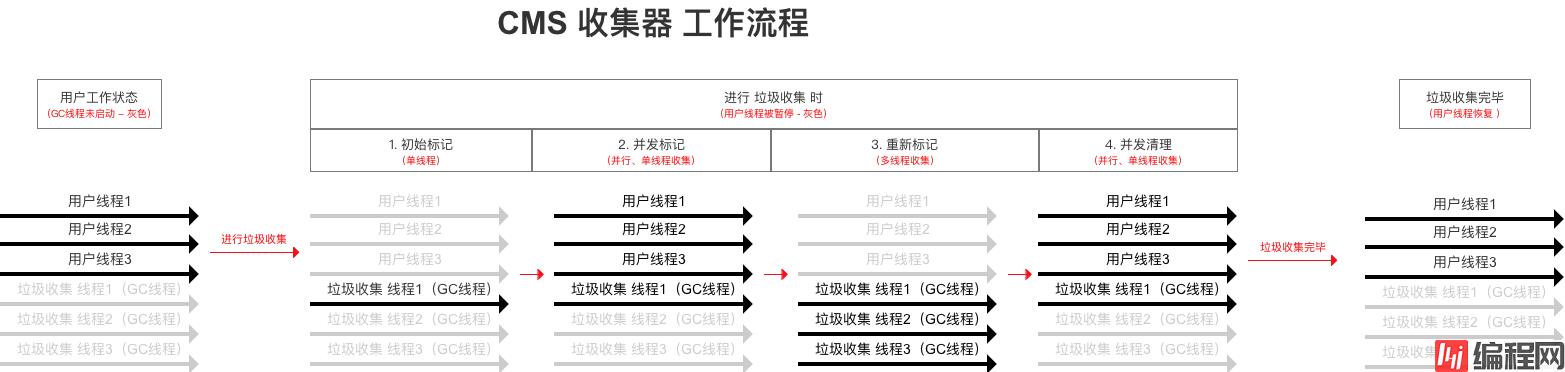
CMS收集器的垃圾收集过程可看作是与用户线程 并发执行的。最新、技术最前沿的垃圾收集器
并行 用户线程 & 垃圾收集线程同时进行。
即在进行垃圾收集时,用户还能工作
多线程 即使用 多条垃圾收集线程(GC线程) 进行垃圾收集
并发 & 并行 充分利用多CPU、多核环境下的硬件优势 来缩短 垃圾收集的停顿时间
垃圾回收效率高 G1 收集器是 针对性 对 Java堆内存区域进行垃圾收集,而非每次都对整个 Java 堆内存区域进行垃圾收集。
即 G1收集器除了将 Java 堆内存区域分为新生代 & 老年代之外,还会细分为许多个大小相等的独立区域( Region),然后G1收集器会跟踪每个 Region里的垃圾价值大小,并在后台维护一个列表;每次回收时,会根据允许的垃圾收集时间 优先回收价值最大的Region,从而避免了对整个Java堆内存区域进行垃圾收集,从而提高效率。
因为上述机制,G1收集器还能建立可预测的停顿时间模型:即让 使用者 明确指定一个长度为M毫秒的时间片段内,消耗在垃圾收集上的时间不得从超出N毫秒。即具备实时性
分代收集 同时应用在 内存区域的新生代 & 老年代
不会产生内存空间碎片
从整体上看,G1 收集器是基于 标记-整理算法实现的收集器
从局部上看,是基于 复制算法 实现 上述两种算法意味着 G1 收集器不会产生内存空间碎片。
对于新生代:复制算法
对于老年代:标记 - 整理算法
服务器端虚拟机的内存区域(包括 新生代 & 老年代)
G1 收集器的工作流程分为4个步骤:
初始标记
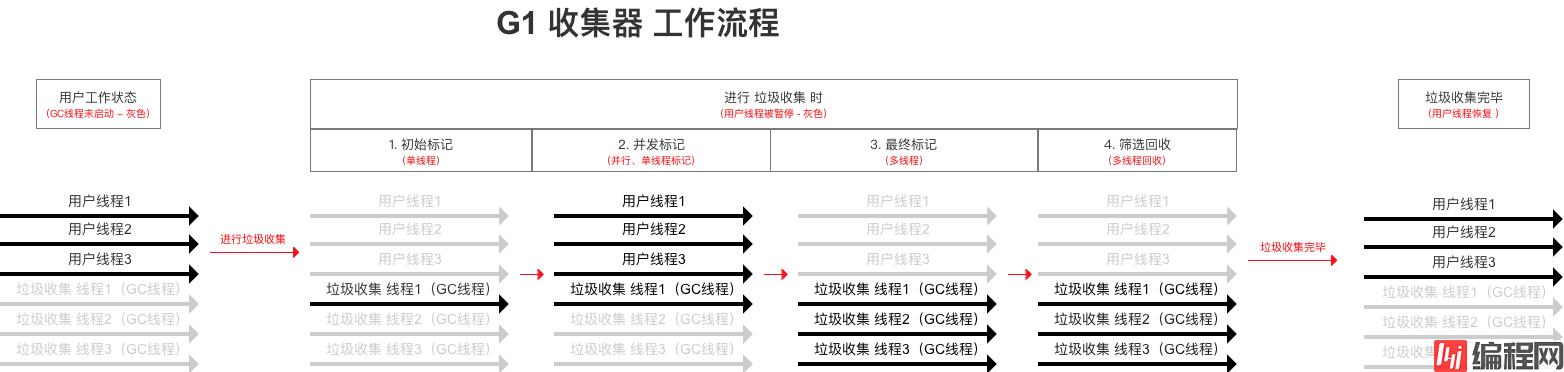
下面用一张图详细说明工作流程
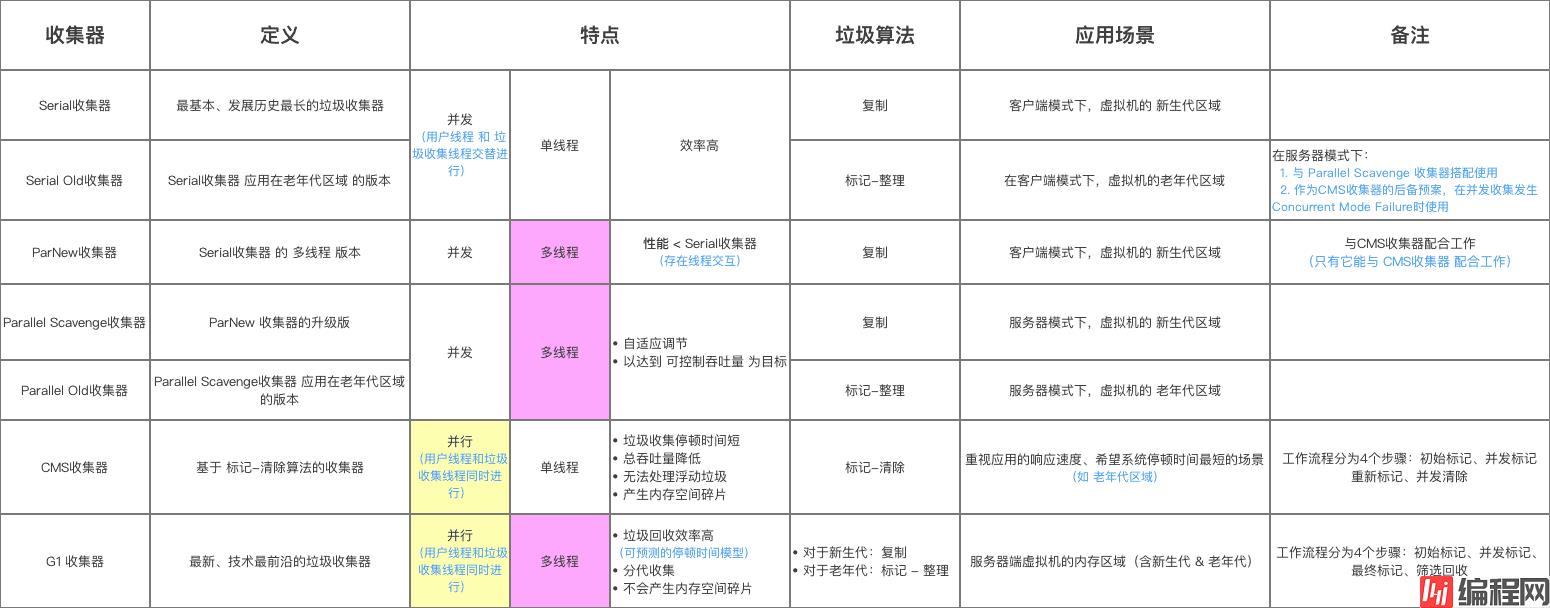
本文对垃圾收集器的类型进行全面讲解
--结束END--
本文标题: JVM常见垃圾收集器学习指南
本文链接: https://lsjlt.com/news/152459.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0