目录原因1:实例内存达到上限原因2:开启内存大页原因3:使用Swap原因4:网络带宽过载 原因5:其他原因原因1:实例内存达到上限 排查思路 如果你的 Redis 实例设置
排查思路
如果你的 Redis 实例设置了内存上限 maxmemory,那么也有可能导致 Redis 变慢。
当我们把 Redis 当做纯缓存使用时,通常会给这个实例设置一个内存上限 maxmemory,然后设置一个数据淘汰策略。而当实例的内存达到了 maxmemory 后,你可能会发现,在此之后每次写入新数据,操作延迟变大了。
导致变慢的原因
当 Redis 内存达到 maxmemory 后,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据,让整个实例的内存维持在 maxmemory 之下,然后才能把新数据写进来。
这个踢出旧数据的逻辑也是需要消耗时间的,而具体耗时的长短,要取决于你配置的淘汰策略:
具体使用哪种策略,我们需要根据具体的业务场景来配置。一般最常使用的是 allkeys-lru / volatile-lru 淘汰策略,它们的处理逻辑是,每次从实例中随机取出一批 key(这个数量可配置),然后淘汰一个最少访问的 key,之后把剩下的 key 暂存到一个池子中,继续随机取一批 key,并与之前池子中的 key 比较,再淘汰一个最少访问的 key。以此往复,直到实例内存降到 maxmemory 之下。
需要注意的是,Redis 的淘汰数据的逻辑与删除过期 key 的一样,也是在命令真正执行之前执行的,也就是说它也会增加我们操作 Redis 的延迟,而且,写 OPS 越高,延迟也会越明显。
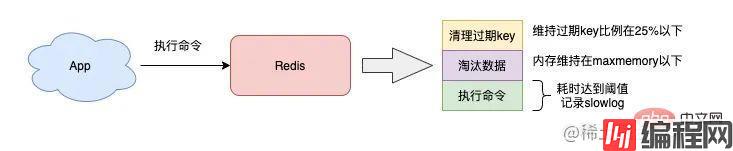
另外,如果此时你的 Redis 实例中还存储了 bigkey,那么在淘汰删除 bigkey 释放内存时,也会耗时比较久。
看到了么?bigkey 的危害到处都是,这也是前面我提醒你尽量不存储 bigkey 的原因。
解决方案
排查思路
导致变慢的原因
解决方案
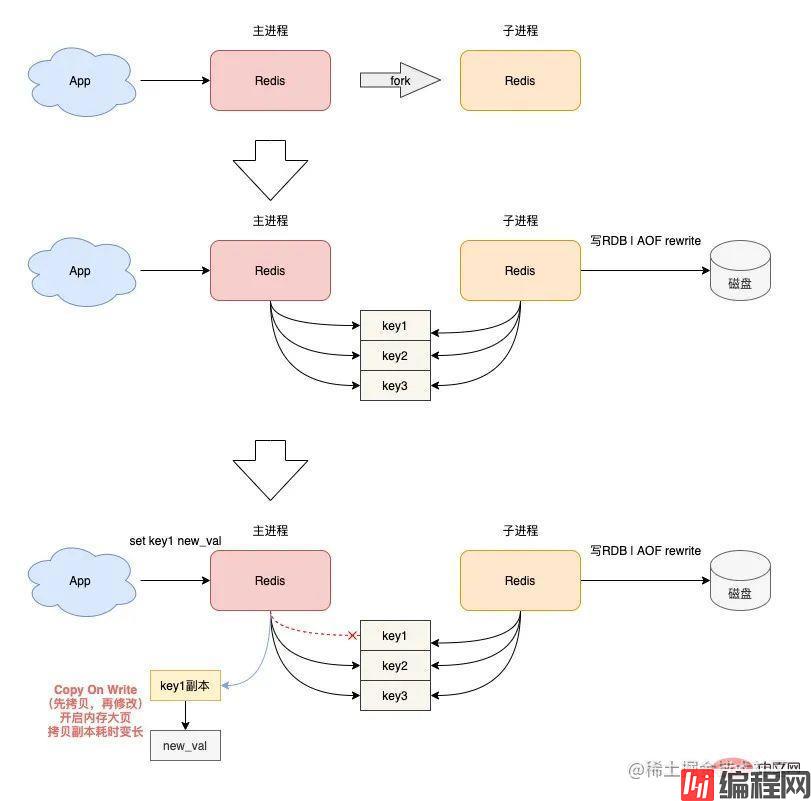
关闭内存大页机制。
首先,你需要查看 Redis 机器是否开启了内存大页:
$ cat /sys/kernel/mm/transparent_hugepage/enabled
[always] madvise never如果输出选项是 always,就表示目前开启了内存大页机制,我们需要关掉它:
$ echo never > /sys/kernel/mm/transparent_hugepage/enabled其实,操作系统提供的内存大页机制,其优势是,可以在一定程序上降低应用程序申请内存的次数。
但是对于 Redis 这种对性能和延迟极其敏感的数据库来说,我们希望 Redis 在每次申请内存时,耗时尽量短,所以我不建议你在 Redis 机器上开启这个机制。
排查思路
如果你发现 Redis 突然变得非常慢,每次的操作耗时都达到了几百毫秒甚至秒级,那此时你就需要检查 Redis 是否使用到了 Swap,在这种情况下 Redis 基本上已经无法提供高性能的服务了。
导致变慢的原因
什么是 Swap?为什么使用 Swap 会导致 Redis 的性能下降?
如果你对操作系统有些了解,就会知道操作系统为了缓解内存不足对应用程序的影响,允许把一部分内存中的数据换到磁盘上,以达到应用程序对内存使用的缓冲,这些内存数据被换到磁盘上的区域,就是 Swap。
问题就在于,当内存中的数据被换到磁盘上后,Redis 再访问这些数据时,就需要从磁盘上读取,访问磁盘的速度要比访问内存慢几百倍!尤其是针对 Redis 这种对性能要求极高、性能极其敏感的数据库来说,这个操作延时是无法接受的。
此时,你需要检查 Redis 机器的内存使用情况,确认是否存在使用了 Swap。你可以通过以下方式来查看 Redis 进程是否使用到了 Swap:
# 先找到 Redis 的进程 ID
$ ps -aux | grep redis-server
# 查看 Redis Swap 使用情况
$ cat /proc/$pid/smaps | egrep '^(Swap|Size)'输出结果如下
Size: 1256 kB
Swap: 0 kB
Size: 4 kB
Swap: 0 kB
Size: 132 kB
Swap: 0 kB
Size: 63488 kB
Swap: 0 kB
Size: 132 kB
Swap: 0 kB
Size: 65404 kB
Swap: 0 kB
Size: 1921024 kB
Swap: 0 kB
...
这个结果会列出 Redis 进程的内存使用情况。
每一行 Size 表示 Redis 所用的一块内存大小,Size 下面的 Swap 就表示这块 Size 大小的内存,有多少数据已经被换到磁盘上了,如果这两个值相等,说明这块内存的数据都已经完全被换到磁盘上了。
如果只是少量数据被换到磁盘上,例如每一块 Swap 占对应 Size 的比例很小,那影响并不是很大。如果是几百兆甚至上 GB 的内存被换到了磁盘上,那么你就需要警惕了,这种情况 Redis 的性能肯定会急剧下降。
解决方案
释放 Redis 的 Swap 过程通常要重启实例,为了避免重启实例对业务的影响,一般会先进行主从切换,然后释放旧主节点的 Swap,重启旧主节点实例,待从库数据同步完成后,再进行主从切换即可。
可见,当 Redis 使用到 Swap 后,此时的 Redis 性能基本已达不到高性能的要求(你可以理解为武功被废),所以你也需要提前预防这种情况。
预防的办法就是,你需要对 Redis 机器的内存和 Swap 使用情况进行监控,在内存不足或使用到 Swap 时报警出来,及时处理。
排查思路
如果以上产生性能问题的场景,你都规避掉了,而且 Redis 也稳定运行了很长时间,但在某个时间点之后开始,操作 Redis 突然开始变慢了,而且一直持续下去,这种情况又是什么原因导致?
此时你需要排查一下 Redis 机器的网络带宽是否过载,是否存在某个实例把整个机器的网路带宽占满的情况。
导致变慢的原因
网络带宽过载的情况下,服务器在 tcp 层和网络层就会出现数据包发送延迟、丢包等情况。
Redis 的高性能,除了操作内存之外,就在于网络 IO 了,如果网络 IO 存在瓶颈,那么也会严重影响 Redis 的性能。
解决方案
1) 频繁短连接
你的业务应用,应该使用长连接操作 Redis,避免频繁的短连接。
频繁的短连接会导致 Redis 大量时间耗费在连接的建立和释放上,TCP 的三次握手和四次挥手同样也会增加访问延迟。
2) 运维监控
前面我也提到了,要想提前预知 Redis 变慢的情况发生,必不可少的就是做好完善的监控。
监控其实就是对采集 Redis 的各项运行时指标,通常的做法是监控程序定时采集 Redis 的 INFO 信息,然后根据 INFO 信息中的状态数据做数据展示和报警。
这里我需要提醒你的是,在写一些监控脚本,或使用开源的监控组件时,也不能掉以轻心。
在写监控脚本访问 Redis 时,尽量采用长连接的方式采集状态信息,避免频繁短连接。同时,你还要注意控制访问 Redis 的频率,避免影响到业务请求。
在使用一些开源的监控组件时,最好了解一下这些组件的实现原理,以及正确配置这些组件,防止出现监控组件发生 Bug,导致短时大量操作 Redis,影响 Redis 性能的情况发生。
我们当时就发生过,DBA 在使用一些开源组件时,因为配置和使用问题,导致监控程序频繁地与 Redis 建立和断开连接,导致 Redis 响应变慢。
3)其它程序争抢资源
最后需要提醒你的是,你的 Redis 机器最好专项专用,只用来部署 Redis 实例,不要部署其他应用程序,尽量给 Redis 提供一个相对「安静」的环境,避免其它程序占用 CPU、内存、磁盘资源,导致分配给 Redis 的资源不足而受到影响。
到此这篇关于浅谈Redis变慢的原因及排查方法的文章就介绍到这了,更多相关Redis变慢内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 浅谈Redis变慢的原因及排查方法
本文链接: https://lsjlt.com/news/151765.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0