目录写在前面构造思想算法设计构造实例理解代码确定结构体循环找出最小值调用细节调试试图总结写在前面 哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树
哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。所谓树的带权路径长度,就是树中所有的叶结点的权值乘上其到根结点的路径长度(若根结点为0层,叶结点到根结点的路径长度为叶结点的层数)。树的路径长度是从树根到每一结点的路径长度之和,记为WPL=(W1*L1+W2*L2+W3*L3+...+Wn*Ln),N个权值Wi(i=1,2,...n)构成一棵有N个叶结点的二叉树,相应的叶结点的路径长度为Li(i=1,2,...n)。可以证明霍夫曼树的WPL是最小的;但是今天,咱们不谈哈夫曼编码,就只用结构体配合数组来完成哈夫曼树的生成,目标是得到正确的所有权值的和。
以字符的使用频率做权构建一棵哈夫曼树,然后利用哈夫曼树对字符进行编码,俗称哈夫曼编码。具体来讲,是将所要编码的字符作为叶子结点,该字符在文件中的使用频率作为叶子结点的权值,以自底向上的方式、通过执行n-1次的“合并”运算后构造出最终所要求的树,即哈夫曼树,它的核心思想是让权值大的叶子离根最近。每次从树的集合中取出双亲为0且权值最小的两棵树作为左、右子树,构造一棵新树,新树根结点的权值为其左右孩子结点权之和,将新树插入到树的集合中。
步骤1:确定合适的数据结构。
步骤2:初始化。构造n棵结点为n个字符的单结点树集合F={T1,T2,…, Tn},每棵树中只有一个带权的根结点,权值为该字符的使用频率;
步骤3:如果F中只剩下一棵树,则哈夫曼树构造成功,转步骤6;否则,从集合F中取出双亲为0且权值最小的两棵树Ti和Tj,将它们合并成一棵新树Zk,新树以Ti为左儿子, Tj为右儿子(反之也可以)。新树Zk的根结点的权值为Ti与Tj的权值之和;
步骤4:从集合F中删去Ti、Tj,加入Zk;
步骤5:重复步骤3和4;
步骤6:从叶子结点到根结点逆向求出每个字符的哈夫曼编码(约定左分支表示字符“0”,右分支表示字符“1”)。则从根结点到叶子结点路径上的分支字符组成的字符串即为叶子字符的哈夫曼编码。算法结束。
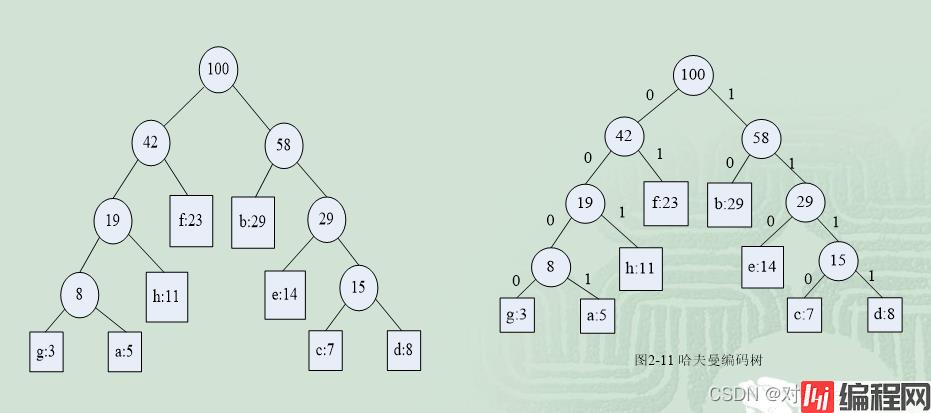
已知某系统在通信联络中只可能出现8种字符,分别为a,b,c,d,e,f,g,h,其使用频率分别为0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11,试设计哈夫曼编码。设权w=(5,29,7,8,14,23,3,11),n=8,按哈夫曼算法的设计步骤构造一棵哈夫曼编码树,具体过程如下:

源码:
#include <iOStream>
using namespace std;
#define N 8
struct node
{
char L;//字母
int K;//权值
bool IsRoot;//是否为根结点
int Lc, Rc;//左右子树
Node(char l = '/0', int k = 0, bool isRoot = false) {
L = l; K = k; IsRoot = isRoot; Lc = Rc = -1;
}
};
Node A[N + N - 1] = { Node('a',5,true) , Node('b',29,true), Node('c',7,true), Node('d',8,true),
Node('e',14,true), Node('f',23,true), Node('g',3,true), Node('h',11,true) };
void FindMin(Node A[], int &min1, int &min2,int num)
{
min1 = num - 1;
for (int i = 0; i < num; i++) {
if (A[i].IsRoot && A[i].K < A[min1].K) min1 = i;
}
min2 = num - 1;
for (int i = 0; i < num; i++) {
if (min1 != i && A[i].IsRoot &&A[i].K < A[min2].K) min2 = i;
}
}
int main()
{
int y = 1, num = N;
int min1=0, min2=0;
for (int i = 0; i < N; i++) {
FindMin(A,min1,min2,num);
A[num].K = A[min1].K + A[min2].K;
A[num].Lc = min1;
A[num].Rc = min2;
A[num].IsRoot = true;
A[min1].IsRoot = false;
A[min2].IsRoot = false;
A[num].L = 'h' + y;
y++; num++;
}
cout << "最终权值为:" << A[14].K << endl;
}首先我们创建结点 Node 结构体,并给他定义了五个属性,分别是字符、权值、布尔型根结点标志、以及左右子树。随后直接定义Node类型数组Node(char l,int k,bool isRoot),初始化Node A数组的长度为 N+N-1的原因是:选取两个最小权值生成新的结点,并把结点放入A数组中,相当于每两个结点会多生成一个节点,那么n个结点就会生成n-1个结点,总数就是n+n-1;我们依次把八个结点放入数组中,并把IsRoot置为true,初始结点均没有参加生成新节点,都是根结点。
将A传入找最小值的函数,初始num为N,随着新节点的生成,逐渐++,然后默认最小值为数组的最后一个元素,利用一重for循环遍历出最小值和次小值,这里注意,找出的最小值必须是根结点才可以,参加过生成新结点的都要把IsRoot设为false,次小值就是在不等于最小值的情况下找出最小值。
主函数中利用一重for循环调用FindMin函数找出两个最小权值结点并默认放到数组的num位置上,即为最后一个位置;首先新节点的权值由两个最小权值相加,并把新节点的左右子树设为找到的两个最小权值结点,由于结构体数组默认IsRoot为false,所有要把新节点设为根结点,而把用过的结点取消根结点身份,L用来更换结点的字符,最后num++,y++都很好理解,经过七次新节点的生成,我们不难猜到A[14]的权值k为100;

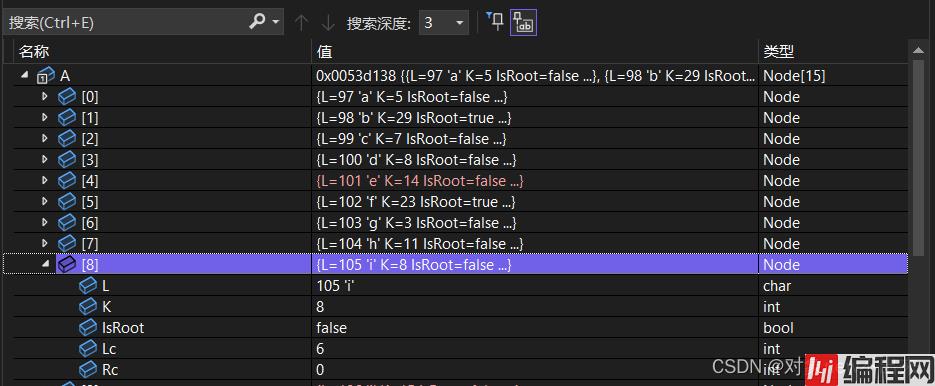
通过调试界面可以看到第一个生成的A[8]结点的左右子树是A[0]和A[6],而且权值正好是他们两个结点的权相加;

A[9]的k是新的两个最小根结点A[2]和A[8]组成的,可以确认权值没有问题,A[8]能参加新节点的合成说明我们成功的把他设置为了根结点,然后直接看最后一个结点的信息;

权值正确为100,是根节点,因为只有一个根结点,没法继续合成新节点,程序结束。
哈夫曼在算法和数据结构中都挺重要的,只是不同场景下实现的方法和形式会有所不同,但就算千变万化也离不开最基础的“二合一”形式,我提出的这个哈夫曼是不难理解的,希望对大家有所帮助,共同进步!!!
到此这篇关于c++使用数组来实现哈夫曼树的文章就介绍到这了,更多相关C++哈夫曼树内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: C++使用数组来实现哈夫曼树
本文链接: https://lsjlt.com/news/149936.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0