Python 官方文档:入门教程 => 点击学习
目录简介操作1:创建流操作2:中间操作筛选(过滤)、去重映射排序消费操作3:终止操作匹配、最值、个数收集规约简介 说明 本文用实例介绍stream的使用。 jdk8新增了Stream
说明
本文用实例介绍stream的使用。
jdk8新增了Stream(流操作) 处理集合的数据,可执行查找、过滤和映射数据等操作。
使用Stream api 对集合数据进行操作,就类似于使用 sql 执行的数据库查询。可以使用 Stream API 来并行执行操作。
简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
特点
不是数据结构,不会保存数据。
大部分不修改原来的数据源,它会将操作后的数据保存到另外一个对象中。
peek方法可以修改流中元素
惰性求值,流在中间处理过程中,只对操作进行记录,不会立即执行,需等到执行终止操作的时候才会进行实际的计算。
Stream操作步骤
创建Stream=> 转换Stream(中间操作)=> 产生结果(终止操作)
注意:这只是一般操作。实际编程时,创建必须有,而中间操作与终止操作是可选的。
操作分类
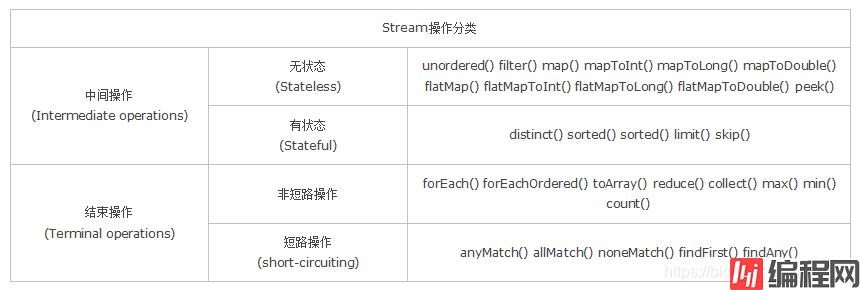
无状态:指元素的处理不受之前元素的影响;
有状态:指该操作只有拿到所有元素之后才能继续下去。
非短路操作:指必须处理所有元素才能得到最终结果;
短路操作:指遇到某些符合条件的元素就可以得到最终结果,如 A || B,只要A为true,则无需判断B的结果。
本文的公共代码
class User {
private String name;
private Integer age;
public User(String name, Integer age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
Collection下的 stream() 和 parallelStream() 方法
List<String> list = new ArrayList<>();
Stream<String> stream = list.stream(); //串行流
Stream<String> parallelStream = list.parallelStream(); //并行流
Arrays 中的 stream() 方法,将数组转成流
Integer[] nums = new Integer[10];
Stream<Integer> stream = Arrays.stream(nums);
Stream中的静态方法:of()、iterate()、generate()
Stream<Integer> stream = Stream.of(1,2,3,4,5,6);
stream.forEach(System.out::println);
// 输出:1 2 3 4 5 6
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 2).limit(6);
stream2.forEach(System.out::println);
// 输出:0 2 4 6 8 10
Stream<Double> stream3 = Stream.generate(Math::random).limit(2);
stream3.forEach(System.out::println);
// 输出:两个随机数
BufferedReader.lines() 方法,将每行内容转成流
BufferedReader reader = new BufferedReader(new FileReader("F:\\test_stream.txt"));
Stream<String> lineStream = reader.lines();
lineStream.forEach(System.out::println);
Pattern.splitAsStream() 方法,将字符串分隔成流
Pattern pattern = Pattern.compile(",");
Stream<String> stringStream = pattern.splitAsStream("a,b,c,d");
stringStream.forEach(System.out::println);
//输出:a b c d
方法
| 方法 | 说明 |
|---|---|
| filter | 过滤流中的某些元素(只保留返回值为true的项) |
| limit(n) | 获取前n个元素 |
| skip(n) | 跳过前n个元素,配合limit(n)可实现分页 |
| distinct | 通过流中元素的 hashCode() 和 equals() 去除重复元素 |
单个元素筛选(过滤)、去重、跳过、获取前n个
List<Integer> list = new ArrayList<>(Arrays.asList(6, 4, 6, 7, 3, 9, 8, 10, 12, 14, 14));
List<Integer> newList = list.stream()
.filter(s -> s > 5) //6 6 7 9 8 10 12 14 14
.distinct() //6 7 9 8 10 12 14
.skip(2) //9 8 10 12 14
.limit(2) //9 8
.collect(Collectors.toList());
根据对象属性去重
List<User> list = new ArrayList<User>() {{
add(new User("Tony", 20, "12"));
add(new User("Pepper", 20, "123"));
add(new User("Tony", 22, "1234"));
add(new User("Tony", 22, "12345"));
}};
//只通过名字去重
List<User> streamByNameList = list.stream().collect(Collectors.collectingAndThen(
Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(User::getName))), ArrayList::new
));
System.out.println(streamByNameList);
//[User{name='Pepper', age=20, Phone='123'},
// User{name='Tony', age=20, Phone='12'}]
//通过名字和年龄去重
List<User> streamByNameAndAgeList = list.stream().collect(Collectors.collectingAndThen(
Collectors.toCollection(
() -> new TreeSet<>(Comparator.comparing(o -> o.getName() + o.getAge()))), ArrayList::new
));
System.out.println(streamByNameAndAgeList);
//[User{name='Pepper', age=20, Phone='123'},
// User{name='Tony', age=20, Phone='12'},
// User{name='Tony', age=22, Phone='1234'}]
collectingAndThen 这个方法的意思是: 将收集的结果转换为另一种类型。
因此上面的方法可以理解为:把 new TreeSet<>(Comparator.comparingLong(BookInfoVo::getRecordId))这个set转换为 ArrayList。
方法
| 方法 | 说明 |
|---|---|
| map | 函数作为参数,该函数被应用到每个元素,并将其映射成一个新的元素。新值类型可以和原来的元素的类型不同。 |
| flatMap | 函数作为参数,将流中每个值换成另一个流,再把所有流连成一个流。 新值类型可以和原来的元素的类型不同。 |
| mapToInt/Long/Double | 跟map差不多。只是将其转为基本类型。 |
| flatMapToInt/Long/Double | 跟flatMap差不多。只是将其转为基本类型。 |
新值类型和原来的元素的类型相同示例
List<String> list = Arrays.asList("a,b,c", "1,2,3");
//将每个元素转成一个新的且不带逗号的元素
Stream<String> s1 = list.stream().map(s -> s.replaceAll(",", ""));
s1.forEach(System.out::println);
// abc 123
Stream<String> s2 = list.stream().flatMap(s -> {
//将每个元素转换成一个stream
String[] split = s.split(",");
Stream<String> s3 = Arrays.stream(split);
return s3;
});
s2.forEach(System.out::println);
// a b c 1 2 3
新值类型和原来的元素的类型不同示例
User u1 = new User("aa", 10);
User u2 = new User("bb", 20);
User u3 = new User("cc", 10);
List<User> list = Arrays.asList(u1, u2, u3);
Set<Integer> ageSet = list.stream().map(User::getAge).collect(Collectors.toSet());
ageSet.forEach(System.out::println);
//20 10
int[] ageInt = list.stream().map(User::getAge).mapToInt(Integer::intValue).toArray();
//下边这样也可以
//Integer[] ages = list.stream.map(User::getAge).toArray(Integer[]::new);
for (int i : ageInt) {
System.out.println(i);
}
//10 20 10
map的原型为:<R> Stream<R> map(Function<? super T, ? extends R> mapper);
上边例子中,将Student::getAge作为参数,其实际为:<R> Stream<Integer> map(Function<? super Student, ? extends Integer> mapper);
方法
| 方法 | 说明 |
|---|---|
| sorted() | 自然排序,流中元素需实现Comparable接口。 例:list.stream().sorted() |
| sorted(Comparator com) | 定制排序。常用以下几种: list.stream().sorted(Comparator.reverseOrder()) list.stream().sorted(Comparator.comparing(Student::getAge)) list.stream().sorted(Comparator.comparing(Student::getAge).reversed()) |
示例
List<String> list = Arrays.asList("aa", "ff", "dd");
//String 类自身已实现Comparable接口
list.stream().sorted().forEach(System.out::println);
System.out.println("------------------------------------");
User u1 = new User("dd", 40);
User u2 = new User("bb", 20);
User u3 = new User("aa", 20);
User u4 = new User("aa", 30);
List<User> userList = Arrays.asList(u1, u2, u3, u4);
//按年龄升序
userList.stream().sorted(Comparator.comparing(User::getAge))
.forEach(System.out::println);
System.out.println("------------------------------------");
//先按年龄升序,年龄相同则按姓名升序
userList.stream().sorted(
(o1, o2) -> {
if (o1.getAge().equals(o2.getAge())) {
return o1.getName().compareTo(o2.getName());
} else {
return o1.getAge().compareTo(o2.getAge());
}
}
).forEach(System.out::println);
结果
aa
dd
ff
------------------------------------
User{name='bb', age=20}
User{name='aa', age=20}
User{name='aa', age=30}
User{name='dd', age=40}
------------------------------------
User{name='aa', age=20}
User{name='bb', age=20}
User{name='aa', age=30}
User{name='dd', age=40}
方法
| 方法 | 说明 |
|---|---|
| peek | 类似于map,能得到流中的每一个元素。 但map接收的是一个Function表达式,有返回值; 而peek接收的是Consumer表达式,没有返回值。 |
示例
User u1 = new User("dd", 40);
User u2 = new User("bb", 20);
User u3 = new User("aa", 20);
User u4 = new User("aa", 30);
List<User> list = Arrays.asList(u1, u2, u3, u4);
List<User> list1 = list.stream()
.peek(o -> o.setAge(100))
.collect(Collectors.toList());
System.out.println(list1);
结果:
[User{name='dd', age=100}, User{name='bb', age=100}, User{name='aa', age=100}, User{name='aa', age=100}]
方法
| 方法 | 说明 |
|---|---|
| allMatch | 接收一个 Predicate 函数,当流中每个元素都符合该断言时才返回true,否则返回false |
| noneMatch | 接收一个 Predicate 函数,当流中每个元素都不符合该断言时才返回true,否则返回false |
| anyMatch | 接收一个 Predicate 函数,只要流中有一个元素满足该断言则返回true,否则返回false |
| findFirst | 返回流中第一个元素 |
| findAny | 返回流中的任意元素 |
| count | 返回流中元素的总个数 |
| max | 返回流中元素最大值 |
| min | 返回流中元素最小值 |
实例1:单个类型
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// 匹配
boolean allMatch = list.stream().allMatch(e -> e > 10); //false
boolean noneMatch = list.stream().noneMatch(e -> e > 10); //true
boolean anyMatch = list.stream().anyMatch(e -> e > 4); //true
// 获取第一个/第任意个
Integer findFirst = list.stream().findFirst().get(); //1
Integer findAny = list.stream().findAny().get(); //1
// 计数、最大值、最小值
long count = list.stream().count(); //5
Integer max = list.stream().max(Integer::compareTo).get(); //5
Integer min = list.stream().min(Integer::compareTo).get(); //1
实例2:获取对象中的字段的最值
User u1 = new User("dd", 40);
User u2 = new User("bb", 20);
User u3 = new User("aa", 20);
User u4 = new User("aa", 30);
List<User> list = Arrays.asList(u1, u2, u3, u4);
//获取最小年龄的用户。
User user1 = list.stream()
.min(Comparator.comparing(User::getAge))
.get();
System.out.println(user1);
System.out.println("------------------------------------");
//获取先按姓名升序,姓名相同则按年龄升序。然后获取最小的那个(第一个)
User user = list.stream().min((o1, o2) -> {
if (o1.getAge().equals(o2.getAge())) {
return o1.getName().compareTo(o2.getName());
} else {
return o1.getAge().compareTo(o2.getAge());
}
}).get();
System.out.println(user);
结果
User{name='bb', age=20}
------------------------------------
User{name='aa', age=20}
方法
| 方法 | 说明 |
|---|---|
| collect | 接收一个Collector实例,将流中元素收集成另外一个数据结构。 |
Collector实例一般由Collectors的静态方法取得。例如:Collectors.toList()
公共代码
User u1 = new User("dd", 40);
User u2 = new User("bb", 20);
User u3 = new User("aa", 20);
User u4 = new User("aa", 30);
List<User> list = Arrays.asList(u1, u2, u3, u4);
转换
字符串分隔符连接
String joinName = list.stream().map(User::getName).collect(Collectors.joining(",", "(", ")"));
System.out.println(joinName);
//(dd,bb,aa,aa)
转成list
List<Integer> ageList = list.stream().map(User::getAge).collect(Collectors.toList());
System.out.println(ageList);
//[40, 20, 20, 30]
转成set
Set<Integer> ageSet = list.stream().map(User::getAge).collect(Collectors.toSet());
System.out.println(ageSet);
//[20, 40, 30]
转成map(注:key不能相同,否则报错)
User s1 = new User("dd", 40);
User s2 = new User("bb", 20);
User s3 = new User("aa", 20);
List<User> list = Arrays.asList(s1, s2, s3);
Map<String, Integer> ageMap = list.stream().collect(Collectors.toMap(User::getName, User::getAge));
System.out.println(ageMap);
//{aa=20, bb=20, dd=40}
本处我将重复的名字给去掉了一个,因为如果key有重复的会报错。
三个参数的map
第一个参数就是用来生成key值的,第二个参数就是用来生成value值的。
第三个参数用在key值冲突的情况下:若新元素产生的key在Map中已经出现过了,第三个参数就会定义解决的办法。
User u1 = new User("aa", 10);
User u2 = new User("bb", 20);
User u3 = new User("cc", 10);
User u4 = new User("bb", 30);
List<User> list = new ArrayList<>(Arrays.asList(u1, u2, u3, u4));
Map<String, List<User>> listMap = list.stream().collect(Collectors.toMap(User::getName,
o -> {
List<User> list1 = new ArrayList<>();
list1.add(o);
return list1;
},
(r1, r2) -> {
r1.addAll(r2);
return r1;
}
)
);
System.out.println(listMap);
结果
{aa=[User{name='aa', age=20}, User{name='aa', age=30}], bb=[User{name='bb', age=20}], dd=[User{name='dd', age=40}]}
聚合
聚合(总数、平均值、最大最小值等)
//1.用户总数
Long count = list.stream().collect(Collectors.counting());
System.out.println(count);
//4
//2.最大年龄 (最小的minBy同理)
Integer maxAge = list.stream().map(User::getAge).collect(Collectors.maxBy(Integer::compare)).get();
System.out.println(maxAge);
//40
//3.所有人的年龄
Integer sumAge = list.stream().collect(Collectors.summingInt(User::getAge));
System.out.println(sumAge);
//110
//4.平均年龄
Double averageAge = list.stream().collect(Collectors.averagingDouble(User::getAge));
System.out.println(averageAge);
// 27.5
// 统计上边所有数据
DoubleSummaryStatistics stat = list.stream().collect(Collectors.summarizingDouble(User::getAge));
System.out.println("count:" + stat.getCount() + " max:" + stat.getMax() + " sum:" + stat.getSum()
+ " average:" + stat.getAverage());
//count:4 max:40.0 sum:110.0 average:27.5
分组
//根据年龄分组
Map<Integer, List<User>> listMap = list.stream().collect(Collectors.groupingBy(User::getAge));
for (Map.Entry<Integer, List<User>> entry : listMap.entrySet()) {
System.out.println(entry.geTKEy() + "-->" + entry.getValue());
}
//20-->[User{name='bb', age=20}, User{name='aa', age=20}]
//40-->[User{name='dd', age=40}]
//30-->[User{name='aa', age=30}]
多重分组
// 先根据年龄分再根据
Map<Integer, Map<String, List<User>>> ageNameMap = list.stream().collect(
Collectors.groupingBy(User::getAge, Collectors.groupingBy(User::getName)));
for (Map.Entry<Integer, Map<String, List<User>>> entry : ageNameMap.entrySet()) {
System.out.println(entry.getKey() + "-->" + entry.getValue());
}
//20-->{aa=[User{name='aa', age=20}], bb=[User{name='bb', age=20}]}
//40-->{dd=[User{name='dd', age=40}]}
//30-->{aa=[User{name='aa', age=30}]}
分区
特殊的分组,分为true和false两组
//分成两部分,一部分大于10岁,一部分小于等于10岁
Map<Boolean, List<User>> partMap = list.stream().collect(Collectors.partitioningBy(v -> v.getAge() > 20));
for (Map.Entry<Boolean, List<User>> entry : partMap.entrySet()) {
System.out.println(entry.getKey() + "-->" + entry.getValue());
}
//false-->[User{name='bb', age=20}, User{name='aa', age=20}]
//true-->[User{name='dd', age=40}, User{name='aa', age=30}]
总结
Collector<T, A, R> 是一个接口,有以下5个抽象方法:
1.Supplier<A> supplier():创建一个结果容器A
2.BiConsumer<A, T> accumulator():消费型接口,第一个参数为容器A,第二个参数为流中元素T。
3.BinaryOperator<A> combiner():函数接口,该参数的作用跟上一个方法(reduce)中的combiner参数一样,将并行流中各个子进程的运行结果(accumulator函数操作后的容器A)进行合并。
4.Function<A, R> finisher():函数式接口,参数为:容器A,返回类型为:collect方法最终想要的结果R。
5.Set<Characteristics> characteristics():返回一个不可变的Set集合,表明该Collector的特征。有以下三个特征:
注:如果对以上函数接口不太理解的话,可参考:Java中Lambda表达式的使用详细教程
Collectors.toList() 解析
//toList 源码
public static <T> Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> {
left.addAll(right);
return left;
}, CH_ID);
}
//为了更好地理解,我们转化一下源码中的lambda表达式
public <T> Collector<T, ?, List<T>> toList() {
Supplier<List<T>> supplier = () -> new ArrayList();
BiConsumer<List<T>, T> accumulator = (list, t) -> list.add(t);
BinaryOperator<List<T>> combiner = (list1, list2) -> {
list1.addAll(list2);
return list1;
};
Function<List<T>, List<T>> finisher = (list) -> list;
Set<Collector.Characteristics> characteristics = Collections.unmodifiableSet
(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH));
return new Collector<T, List<T>, List<T>>() {
@Override
public Supplier supplier() {
return supplier;
}
@Override
public BiConsumer accumulator() {
return accumulator;
}
@Override
public BinaryOperator combiner() {
return combiner;
}
@Override
public Function finisher() {
return finisher;
}
@Override
public Set<Characteristics> characteristics() {
return characteristics;
}
};
}
方法
| 方法 | 说明 |
|---|---|
| Optional<T> reduce(BinaryOperator<T> accumulator) | 第一次执行时,accumulator函数的第一个参数为流中的第一个元素,第二个参数为流中元素的第二个元素; 第二次执行时,第一个参数为第一次函数执行的结果,第二个参数为流中的第三个元素; 依次类推。 |
| T reduce(T identity, BinaryOperator<T> accumulator) | 流程跟上面一样,只是第一次执行时,accumulator函数的第一个参数为identity,而第二个参数为流中的第一个元素。 |
| <U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner) | 在串行流(stream)中,该方法跟第二个方法一样,即第三个参数combiner不会起作用。在并行流(parallelStream)中,我们知道流被fork join出多个线程进行执行,此时每个线程的执行流程就跟第二个方法reduce(identity,accumulator)一样,而第三个参数combiner函数,则是将每个线程的执行结果当成一个新的流,然后使用第一个方法reduce(accumulator)流程进行规约。 |
示例
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Integer v = list.stream().reduce((x1, x2) -> x1 + x2).get();
System.out.println(v);
// 15
Integer v0 = list.stream().reduce((x1, x2) -> x1 + x2).get();
System.out.println(v0);
//15
Integer v1 = list.stream().reduce(10, (x1, x2) -> x1 + x2);
System.out.println(v1);
//25
Integer v2 = list.stream().reduce(0,
(x1, x2) -> {
System.out.println("stream accumulator: x1:" + x1 + " x2:" + x2);
return x1 - x2;
},
(x1, x2) -> {
System.out.println("stream combiner: x1:" + x1 + " x2:" + x2);
return x1 * x2;
});
System.out.println(v2);
// -15
Integer v3 = list.parallelStream().reduce(0,
(x1, x2) -> {
System.out.println("parallelStream accumulator: x1:" + x1 + " x2:" + x2);
return x1 - x2;
},
(x1, x2) -> {
System.out.println("parallelStream combiner: x1:" + x1 + " x2:" + x2);
return x1 * x2;
});
System.out.println(v3);
//-120打印结果为:
15
15
25
stream accumulator: x1:0 x2:1
stream accumulator: x1:-1 x2:2
stream accumulator: x1:-3 x2:3
stream accumulator: x1:-6 x2:4
stream accumulator: x1:-10 x2:5
-15
parallelStream accumulator: x1:0 x2:3
parallelStream accumulator: x1:0 x2:5
parallelStream accumulator: x1:0 x2:4
parallelStream combiner: x1:-4 x2:-5
parallelStream accumulator: x1:0 x2:2
parallelStream accumulator: x1:0 x2:1
parallelStream combiner: x1:-3 x2:20
parallelStream combiner: x1:-1 x2:-2
parallelStream combiner: x1:2 x2:-60
-120
到此这篇关于一文详解Java中Stream流的使用的文章就介绍到这了,更多相关Java Stream流内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: 一文详解Java中Stream流的使用
本文链接: https://lsjlt.com/news/149607.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0