目录一.引入二.循环链表的定义三.单链表与循环链表对比3.1图示对比3.2代码对比四.循环链表的操作4.1循环链表的初始化4.2循环链表的建立4.2.1头插法建立循环链表4.2.2尾
在单链表中我们是把结点遍历一遍后就结束了,为了使表处理更加方便灵活,我们希望通过任意一个结点出发都可以找到链表中的其它结点,因此我们引入了循环链表。
将单链表中终端结点的指针端由空指针改为头结点,就使整个单链表形成了一个环,这种头尾相接的单链表称为循环链表。
简单理解就是形成一个闭合的环,在环内寻找自己需要的结点。
单链表:

循环链表:
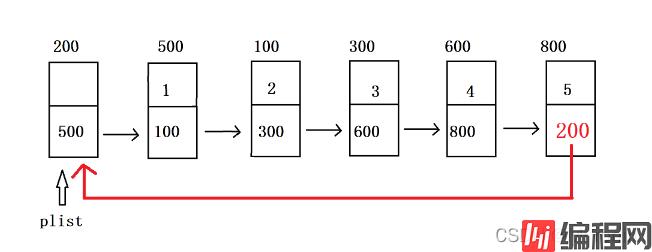
单链表:
typedef struct node{ //定义单链表结点类型
int data; //数据域,可以是别的各种数据类型
struct Node *next; //指针域
}LNode, *LinkList;
循环链表:
typedef int ELEMTYPE;
typedef struct Clist
{
ELEMTYPE data; //数据域 存放数据
struct Clist* next;
//指针域存放下一个节点的地址(尾结点的next保存头结点的地址)
}Clist, * PClist;
循环链表是单链表中扩展出来的结构,所以有很多的操作是和单链表相同的,如求长度,查找元素,获取一个元素,这里我们对循环链表进行初始化,创建,插入,删除,销毁的一系列操作。
单链表和循环链表初始化对比如下:
| 单链表 | 循环链表 |
|---|---|
| 数据域不处理 | 数据域不处理 |
| next域赋值为NULL | next域赋值为头结点自身的地址 |
代码如下:
void InitClist(struct Clist* plist)
{
//assert
//plist->data; // 数据域不处理
plist->next = plist;
}循环链表的建立是基于单链表所以也有头插和尾插两种方式。
头插法建立循环链表的主要是这两行代码:
pnewnode->next=plist->next;
plist->next=pnewnode;
这里我们需要思考一下当链表为空时是否适用:这里明确告诉大家不管是否是空链表,这两行代码均可以使用,下面给大家用示意图表示一下;
不是空链:

是空链:

代码如下:
bool Insert_head(PClist plist, ELEMTYPE val)
{
//assert
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置 (头插 不用找)
//3.插入
pnewnode->next = plist->next;
plist->next = pnewnode;
return true;
}
尾插法建立循环链表主要代码如下:
for(p=plist;p->next!=plist;p=p->next);

代码如下:
bool Insert_tail(PClist plist, ELEMTYPE val)
{
//assert
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置(通过带前驱的for循环)
struct Clist* p = plist;
for (p; p->next != plist; p = p->next);
//此时 for循环执行结束 p指向尾结点
//3.插入
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}
与单向链表的插入不同,循环单链表插入时只能往表头节点的后面插入,由初始结构可知,想完成插入操作,必须先找到要插入位置的前一个节点,然后修改相应指针即可完成操作。
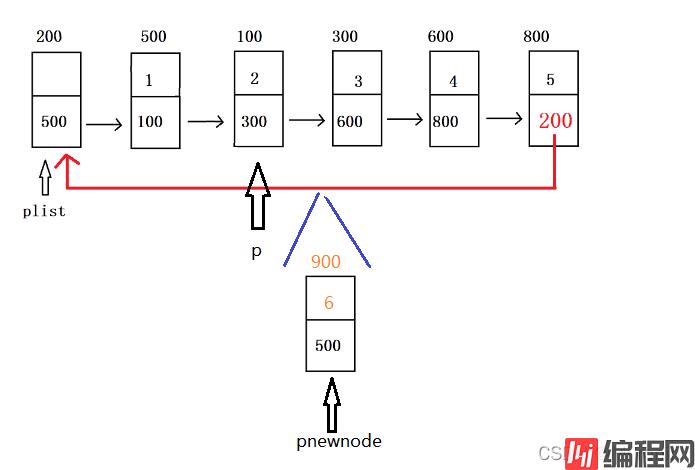
bool Insert_pos(PClist plist, int pos, ELEMTYPE val)
{
assert(plist != NULL);
assert(pos >= 0 && pos <= Get_length(plist));
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置(通过带前驱的for循环)
struct Clist* p = plist;
for (int i = 0; i < pos; i++)
{
p = p->next;
}
//此时 for循环执行结束 p指向待插入的合适位置
//3.插入
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}
循环链表的删除操作相当于单链表的删除操作,主要分为以下三个步骤:
void Delete(list **pNode,int place) //删除操作
{
list *temp,*target;
int i;
temp=*pNode;
if(temp==NULL) //首先判断链表是否为空
{
printf("这是一个空指针 无法删除\n");
return;
}
if(place==1) //如果删除的是头节点
{ //应当特殊处理,找到尾节点,使尾节点的next指向头节点的下一个节点
// rear->next=(*head)->next;然后让新节点作为头节点,释放原来的头节点
for(target=*pNode;target->next!=*pNode;target=target->next);
temp=*pNode;
*pNode=(*pNode)->next;
target->next=*pNode;
free(temp);
}
else //删除其他节点
{ //首先找出尾节点
for(i=1,target=*pNode;target->next!=*pNode&&i!=place-1;target=target->next,i++);
if(target->next==*pNode) //判断要删除的位置是否大于链表长度,若大于链表长度,
//特殊处理直接删除尾节点
{
//找出尾节的前一个节点
for(target=*pNode;target->next->next!=*pNode;target=target->next);
temp=target->next; // 尾节点的前一个节点直接指向头节点 释放原来的尾节点
target->next=*pNode;
printf("数字太大删除尾巴\n");
free(temp);
}
else
{
temp=target->next;// 删除普通节点 找到要删除节点的前一个节点target,
//使target指向要删除节点的下一个节点 转存删除节点地址
target->next=temp->next; // 然后释放这个节点
free(temp);
}
}
}
循环链表这里有两种销毁方式:
void Destroy1(PClist plist)
{
//assert
while (plist->next != plist)
{
struct Clist* p = plist->next;
plist->next = p->next;
free(p);
}
plist->next = plist;
}
void Destroy2(PClist plist)
{
//assert
struct Clist* p = plist->next;
struct Clist* q = NULL;
plist->next = plist;
while (p != plist)
{
q = p->next;
free(p);
p = q;
}
}循环链表还有查找值,判空,求链表长度,清空等一系列操作,这些操作与单链表那的操作基本相同,这里不进行详细赘述,在后面的完整代码中会写出来。
循环链表相对于单链表来说会稍微复杂一点,主要思想还是和单链表差不多的,只不过是将链表的首位进行相连,但是正是因为首尾的相连,便于我们通过任意一个结点出发都可以找到链表中的其它结点。
#include <stdio.h>
#include <malloc.h>
#include <assert.h>
//循环链表里边很少出现NULL, nullptr
//初始化
void InitClist(struct Clist* plist)
{
//assert
//plist->data; // 数据域不处理
plist->next = plist;
}
//头插
bool Insert_head(PClist plist, ELEMTYPE val)
{
//assert
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置 (头插 不用找)
//3.插入
pnewnode->next = plist->next;
plist->next = pnewnode;
return true;
}
//尾插
bool Insert_tail(PClist plist, ELEMTYPE val)
{
//assert
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置(通过带前驱的for循环)
struct Clist* p = plist;
for (p; p->next != plist; p = p->next);
//此时 for循环执行结束 p指向尾结点
//3.插入
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}
//按位置插
bool Insert_pos(PClist plist, int pos, ELEMTYPE val)
{
assert(plist != NULL);
assert(pos >= 0 && pos <= Get_length(plist));
//1.购买新节点
struct Clist* pnewnode = (struct Clist*)malloc(1 * sizeof(struct Clist));
assert(pnewnode != NULL);
pnewnode->data = val;//购买的新节点 处理完毕
//2.找到插入位置(通过带前驱的for循环)
struct Clist* p = plist;
for (int i = 0; i < pos; i++)
{
p = p->next;
}
//此时 for循环执行结束 p指向待插入的合适位置
//3.插入
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}
//头删
bool Del_head(PClist plist)
{
//assert
if (IsEmpty(plist))//不空 则至少存在一个有效值
{
return false;
}
//1.指针p指向待删除节点
struct Clist* p = plist->next;
//2.指针q指向待删除节点的前一个节点
//q 就是 头结点 这里就不再额外处理
//3.跨越指向
plist->next = p->next;
free(p);
return true;
}
//尾删
bool Del_tail(PClist plist)
{
//assert
if (IsEmpty(plist))//不空 则至少存在一个有效值
{
return false;
}
//1.指针p指向待删除节点(尾删的话,这里指向尾结点)
struct Clist* p = plist;
for (p; p->next != plist; p = p->next);
//此时 for指向结束 代表着p指向尾结点
//2.指针q指向倒数第二个节点
struct Clist* q = plist;
for (q; q->next != p; q = q->next);
//此时 for指向结束 代表着q指向p的上一个节点
//3.跨越指向
q->next = p->next;
free(p);
return true;
}
//按位置删
bool Del_pos(PClist plist, int pos)
{
assert(plist != NULL);
assert(pos >= 0 && pos < Get_length(plist));
if (IsEmpty(plist))
{
return false;
}
//1.指针p指向待删除节点
//2.指针q指向待删除节点的上一个节点
//这里采用第二种方案找pq,先找q再找p
struct Clist* q = plist;
for (int i = 0; i < pos; i++)
{
q = q->next;
}
struct Clist* p = q->next;
//3.跨越指向
q->next = p->next;
free(p);
return true;
}
//按值删除
bool Del_val(PClist plist, ELEMTYPE val)
{
//assert
struct Clist* p = Search(plist, val);
if (p == NULL)
{
return false;
}
struct Clist* q = plist;
for (q; q->next != p; q = q->next);
q->next = p->next;
free(p);
return true;
}
//查找(如果查找到,需要返回找到的这个节点的地址)
struct Clist* Search(struct Clist* plist, ELEMTYPE val)
{
//assert
for (struct Clist* p = plist->next; p != plist; p = p->next)
{
if (p->data == val)
{
return p;
}
}
return NULL;
}
//判空
bool IsEmpty(PClist plist)
{
//assert
return plist->next == plist;
}
//判满(循环链表不需要这个操作)
//获取长度
int Get_length(PClist plist)
{
//不带前驱的for循环 跑一遍就好
int count = 0;
for (struct Clist* p = plist->next; p != plist; p = p->next)
{
count++;
}
return count;
}
//清空
void Clear(PClist plist)
{
//assert
Destroy1(plist);
}
//销毁1(无限头删)
void Destroy1(PClist plist)
{
//assert
while (plist->next != plist)
{
struct Clist* p = plist->next;
plist->next = p->next;
free(p);
}
plist->next = plist;
}
//销毁2(要用到两个指针变量)
void Destroy2(PClist plist)
{
//assert
struct Clist* p = plist->next;
struct Clist* q = NULL;
plist->next = plist;
while (p != plist)
{
q = p->next;
free(p);
p = q;
}
}
//打印
void Show(struct Clist* plist)
{
//assert
for (struct Clist* p = plist->next; p != plist; p = p->next)
{
printf("%d ", p->data);
}
printf("\n");
}到此这篇关于C语言循环链表的原理与使用操作的文章就介绍到这了,更多相关C语言循环链表内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: C语言循环链表的原理与使用操作
本文链接: https://lsjlt.com/news/149433.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0