Python 官方文档:入门教程 => 点击学习
目录一、concat函数1)横向堆叠与外连接2) 纵向堆叠与内链接二、merge()函数1)根据行索引合并数据2)合并重叠数据一、concat函数 1.concat()函数
1.concat()函数可以沿着一条轴将多个对象进行堆叠,其使用方式类似数据库中的数据表合并
pandas.concat(objs, axis=0, join=’outer’, join_axes=None, ignore_index=False, keys=None, levels=None, verify_integrity=False, sort=None, copy=True)
2.参数含义如下:
| 参数 | 作用 |
|---|---|
| axis | 表示连接的轴向,可以为0或者1,默认为0 |
| join | 表示连接的方式,inner表示内连接,outer表示外连接,默认使用外连接 |
| ignore_index | 接收布尔值,默认为False。如果设置为True,则表示清除现有索引并重置索引值 |
| keys | 接收序列,表示添加最外层索引 |
| levels | 用于构建MultiIndex的特定级别(唯一值) |
| names | 设置了keys和level参数后,用于创建分层级别的名称 |
| verify_integerity | 检查新的连接轴是否包含重复项。接收布尔值,当设置为True时,如果有重复的轴将会抛出错误,默认为False |
3.根据轴方向的不同,可以将堆叠分成横向堆叠与纵向堆叠,默认采用的是纵向堆叠方式
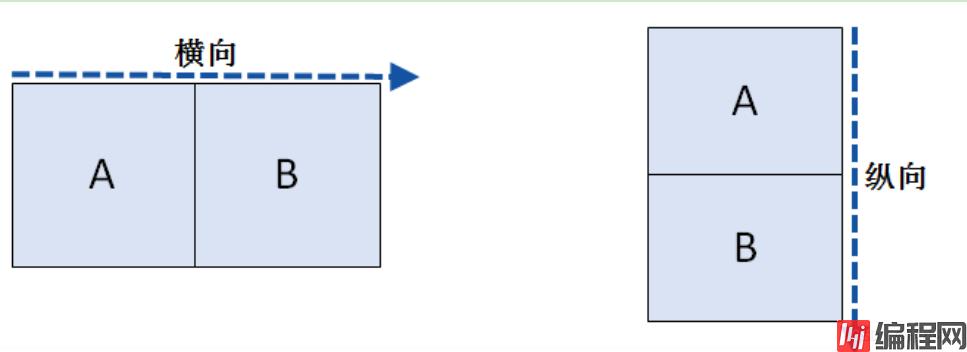
4.在堆叠数据时,默认采用的是外连接(join参数设为outer)的方式进行合并,当然也可以通过join=inner设置为内连接的方式。

import pandas as pd
df1=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
df1

横向堆叠合并df1和df2,采用外连接的方式
pd.concat([df1,df2],join='outer',axis=1)
import pandas as pd
first=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2'],
'C':['C0','C1','C2']})
first
second=pd.DataFrame({'B':['B3','B4','B5'],
'C':['C3','C4','C5'],
'D':['D3','D4','D5']})
second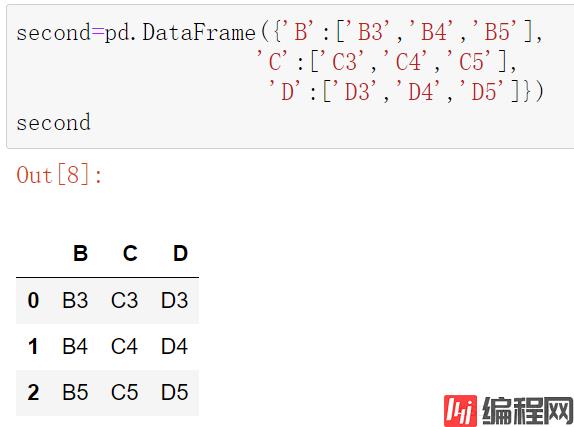
3.当使用concat()函数合并时,若是将axis参数的值设为0,且join参数的值设为inner,则代表着使用纵向堆叠与内连接的方式进行合并
pd.concat([first,second],join='inner',axis=0)
1)主键合并数据
在使用merge()函数进行合并时,默认会使用重叠的列索引做为合并键,并采用内连接方式合并数据,即取行索引重叠的部分。
import pandas as pd
left=pd.DataFrame({'key':['K0','K1','K2'],
'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
left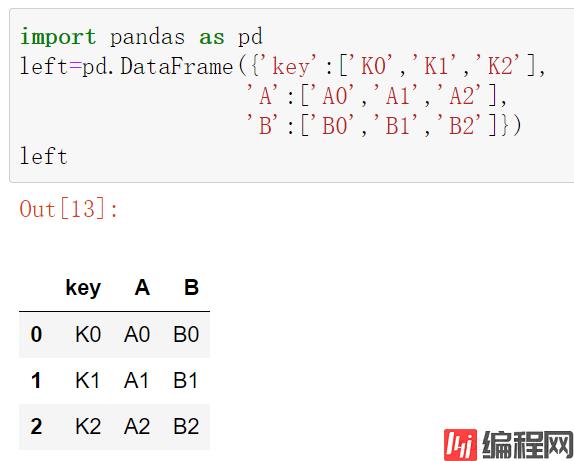
right=pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
right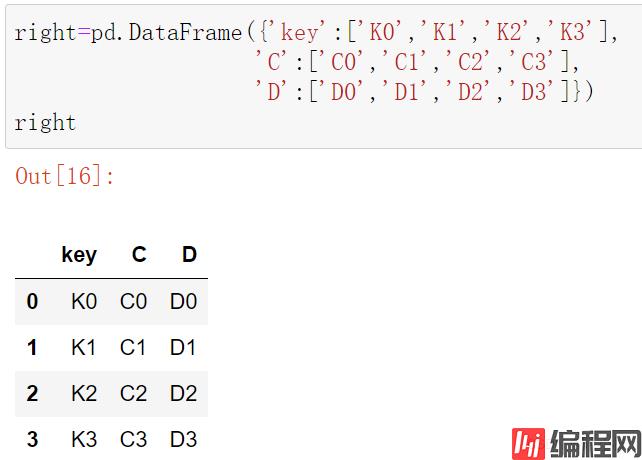
pd.merge(left,right,on='key')
2)merge()函数还支持对含有多个重叠列的DataFrame对象进行合并。
import pandas as pd
data1=pd.DataFrame({'key':['K0','K1','K2'],
'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
data1
data2=pd.DataFrame({'key':['K0','K5','K2','K4'],
'B':['B0','B1','B2','B5'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
data2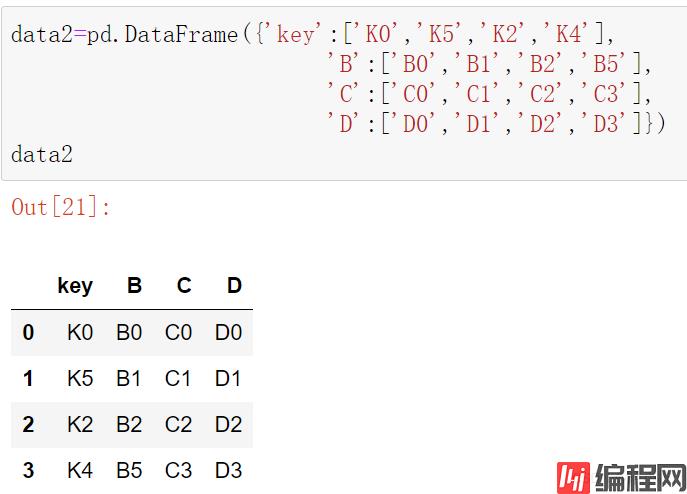
pd.merge(data1,data2,on=['key','B'])
join()方法能够通过索引或指定列来连接多个DataFrame对象
join(other,on = None,how =‘left’,lsuffix =‘’,rsuffix =‘’,sort = False )
| 参数 | 作用 |
|---|---|
| on | 名称,用于连接列名 |
| how | 可以从{‘‘left’’ ,‘‘right’’, ‘‘outer’’, ‘‘inner’’}中任选一个,默认使用左连接的方式。 |
| sort | 根据连接键对合并的数据进行排序,默认为False |
import pandas as pd
data3=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']})
data3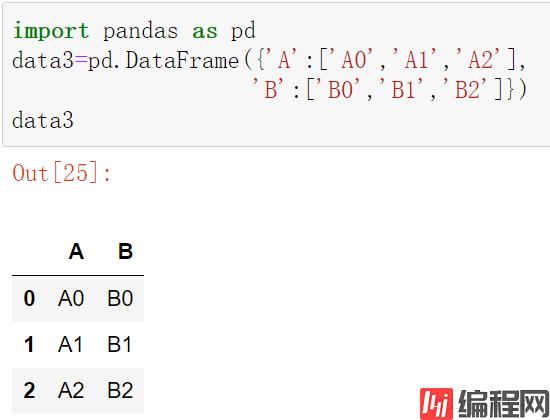
data4=pd.DataFrame({'C': ['C0', 'C1', 'C2'],
'D': ['D0', 'D1', 'D2']},
index=['a','b','c'])
data3.join(data4,how='outer') # 外连接
data3.join(data4,how='left') #左连接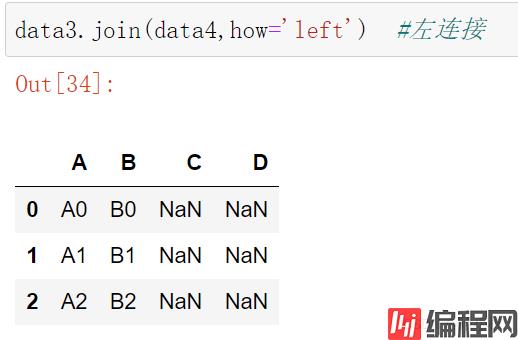
data3.join(data4,how='right') #右连接
data3.join(data4,how='inner') #内连接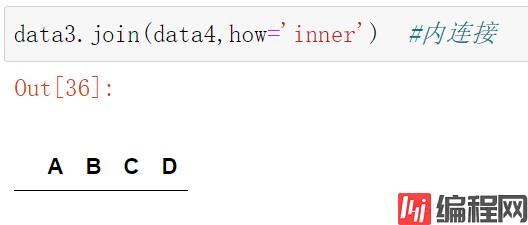
import pandas as pd
left = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2'],
'key': ['K0', 'K1', 'K2']})
left
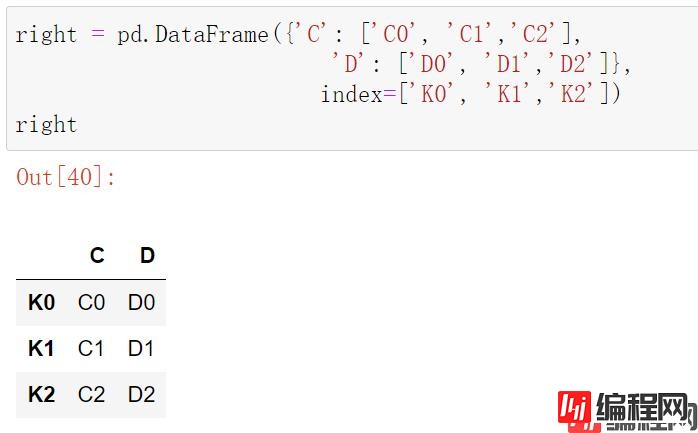
right = pd.DataFrame({'C': ['C0', 'C1','C2'],
'D': ['D0', 'D1','D2']},
index=['K0', 'K1','K2'])
right
on参数指定连接的列名
left.join(right,how='left',on='key') #on参数指定连接的列名
当DataFrame对象中出现了缺失数据,而我们希望使用其他DataFrame对象中的数据填充缺失数据,则可以通过combine_first()方法为缺失数据填充。
import pandas as pd
import numpy as np
from numpy import NAN
left = pd.DataFrame({'A': [np.nan, 'A1', 'A2', 'A3'],
'B': [np.nan, 'B1', np.nan, 'B3'],
'key': ['K0', 'K1', 'K2', 'K3']})
left
right = pd.DataFrame({'A': ['C0', 'C1','C2'],
'B': ['D0', 'D1','D2']},
index=[1,0,2])
right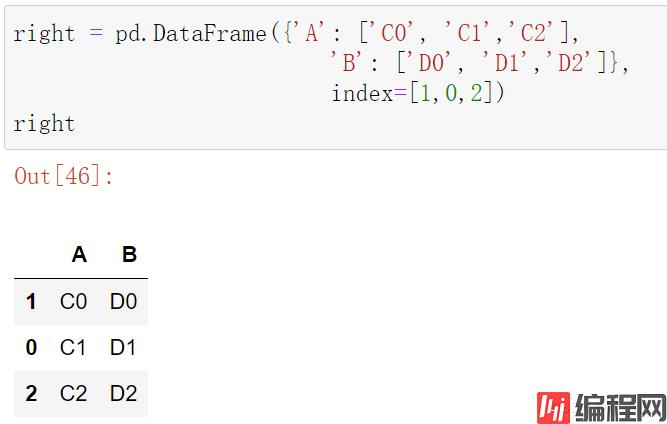
用right的数据填充left缺失的部分
left.combine_first(right) # 用right的数据填充left缺失的部分
到此这篇关于python数据合并的concat函数与merge函数详解的文章就介绍到这了,更多相关Python 数据合并concat函数与merge函数内容请搜索编程网以前的文章或继续浏览下面的相关文章希望大家以后多多支持编程网!
--结束END--
本文标题: Python数据合并的concat函数与merge函数详解
本文链接: https://lsjlt.com/news/148895.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0