Python 官方文档:入门教程 => 点击学习
前言 最近有人在Twisted邮件列表中提出诸如"为任务紧急的人提供一份Twisted介绍"的需求。值得提前透露的是,这个系列并不会如他们所愿。尤其是介绍Twisted框架和基于python 的异步编程而言
前言
最近有人在Twisted邮件列表中提出诸如"为任务紧急的人提供一份Twisted介绍"的需求。值得提前透露的是,这个系列并不会如他们所愿。尤其是介绍Twisted框架和基于python 的异步编程而言,可能短时间无法讲清楚。因此,如果你时间紧急,这恐怕不是你想找的资料。
我相信如果对异步编程模型一无所知,快速的介绍同样无法让你对其有所理解,至少你得稍微懂点基础知识吧。我已经用Twisted框架几年了,因此思考过我当初是怎么学习它(学得很慢)并发现学习它的最大难度并不在Twisted本身,而在于对其模型的理解,只有理解了这个模型,你才能更好去写和理解异步程序的代码。大部分Twisted的代码写得很清晰,其在线文档也非常棒(至少在开源软件这个层次上可以这么说)。但如果不理解这个模型,不管是读Twisted源码还是使用Twisted的代码更或者是相关文档,你都会感到非常的伤脑筋。
因此,我会用前面几个部分来介绍这个模型以让你掌握它的机制,稍后会介绍一下Twisted的特点。实际上,一开始,我们并不会使用Twisted,相反,会使用简单的Python代码来说明一个异步模型是如何工作的。我们在初次学习Twisted的时,会从你平常都不会直接使用的底层的实现讲起。Twisted是一个高度抽象的体系,因此在使用它时,你会体会到其多层次性。但当你去学习尤其是尝试着理解它是如何工作时,这种为抽像而带来的多层次性会给你带来极大的理解难度。所以,我们准备来个从内到外,从低层开始学习它。
模型
为了更好的理解异步编程模型的特点,我们来回顾一下两个大家都熟悉的模型。在阐述过程中,我们假设一个包含三个相互独立任务的程序。在此,除了规定这些任务都要完成自己工作外,我们先不作具体的解释,后面我们会慢慢具体了解它们。请注意:在此我用"任务"这个词,这意味着它需要完成一些事情。
第一个模型是单线程的同步模型,如图1所示:
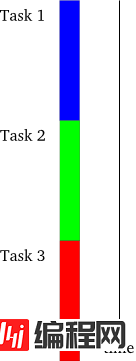
图1 同步模型
这是最简单的编程方式。在一个时刻,只能有一个任务在执行,并且前一个任务结束后一个任务才能开始。如果任务都能按照事先规定好的顺序执行,最后一个任务的完成意味着前面所有的任务都已无任何差错地完成并输出其可用的结果—这是多么简单的逻辑。 下面我们来呈现第二个模型,如图2所示:

图2 线程模型
在这个模型中,每个任务都在单独的线程中完成。这些线程都是由操作系统来管理,若在多处理机、多核处理机的系统中可能会相互独立的运行,若在单处理机上,则会交错运行。关键点在于,在线程模式中,具体哪个任务执行由操作系统来处理。但编程人员则只需简单地认为:它们的指令流是相互独立且可以并行执行。虽然,从图示看起来很简单,实际上多线程编程是很麻烦的,你想啊,任务之间的要通信就要是线程之间的通信。线程间的通信那不是一般的复杂。什么邮槽、通道、共享内存。。。 唉—__-
一些程序用多处理机而不是多线程来实现并行运算。虽然具体的编程细节是不同的,但对于我们要研究的模型来说是一样的。
下面我们来介绍一下异步编程模型,如图3所示
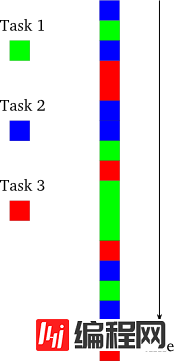
图3 异步模型
在这个模型中,任务是交错完成,值得注意的是:这是在单线程的控制下。这要比多线程模型简单多了,因为编程人员总可以认为只有一个任务在执行,而其它的在停止状态。虽然在单处理机系统中,线程也是像图3那样交替进行。但作为程序员在使用多线程时,仍然需要使用图2而不是图3的来思考问题,以防止程序在挪到多处理机的系统上无法正常运行(考虑到兼容性)。但单线程的异步程序不管是在单处理机还是在多处理机上都能很好的运行。
在异步编程模型与多线程模型之间还有一个不同:在多线程程序中,对于停止某个线程启动另外一个线程,其决定权并不在程序员手里而在操作系统那里,因此,程序员在编写程序过程中必须要假设在任何时候一个线程都有可能被停止而启动另外一个线程。相反,在异步模型中,一个任务要想运行必须显式放弃当前运行的任务的控制权。这也是相比多线程模型来说,最简洁的地方。 值得注意的是:将异步编程模型与同步模型混合在同一个系统中是可以的。但在介绍中的绝大多数时候,我们只研究在单个线程中的异步编程模型。
动机
我们已经看到异步编程模型之所以比多线程模型简单在于其单指令流与显式地放弃对任务的控制权而不是被操作系统随机地停止。但是异步模型要比同步模型复杂得多。程序员必须将任务组织成序列来交替的小步完成。因此,若其中一个任务用到另外一个任务的输出,则依赖的任务(即接收输出的任务)需要被设计成为要接收系列比特或分片而不是一下全部接收。由于没有实质上的并行,从我们的图中可以看出,一个异步程序会花费一个同步程序所需要的时间,可能会由于异步程序的性能问题而花费更长的时间。
因此,就要问了,为什么还要使用异步模型呢? 在这儿,我们至少有两个原因。首先,如果有一到两个任务需要完成面向人的接口,如果交替执行这些任务,系统在保持对用户响应的同时在后台执行其它的任务。因此,虽然后台的任务可能不会运行的更快,但这样的系统可能会受欢迎的多。
然而,有一种情况下,异步模型的性能会高于同步模型,有时甚至会非常突出,即在比较短的时间内完成所有的任务。这种情况就是任务被强行等待或阻塞,如图4所示:
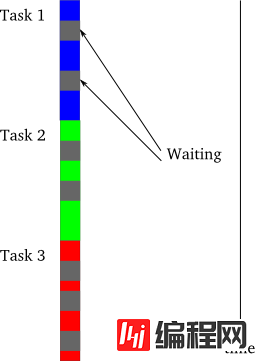
图4 同步模型中出现阻塞
在图4中,灰色的部分代表这段时间某个任务被阻塞。为什么要阻塞一个任务呢?最直接的原因就是等待I/O的完成:传输数据或来自某个外部设备。一个典型的CPU处理数据的能力是硬盘或网络的几个数量级的倍数。因此,一个需要进行大I/O操作的同步程序需要花费大量的时间等待硬盘或网络将数据准备好。正是由于这个原因,同步程序也被称作为阻塞程序。
从图4中可以看出,一个可阻塞的程序,看起来与图3描述的异步程序有点像。这不是个巧合。异步程序背后的最主要的特点就在于,当出现一个任务像在同步程序一样出现阻塞时,会让其它可以执行的任务继续执行,而不会像同步程序中那样全部阻塞掉。因此一个异步程序只有在没有任务可执行时才会出现"阻塞",这也是为什么异步程序被称为非阻塞程序的原因。 任务之间的切换要不是此任务完成,要不就是它被阻塞。由于大量任务可能会被阻塞,异步程序等待的时间少于同步程序而将这些时间用于其它实时工作的处理(如与人打交道的接口),这样一来,前者的性能必然要高很多。
与同步模型相比,异步模型的优势在如下情况下会得到发挥:
有大量的任务,以至于可以认为在一个时刻至少有一个任务要运行
任务执行大量的I/O操作,这样同步模型就会在因为任务阻塞而浪费大量的时间
任务之间相互独立,以至于任务内部的交互很少。
这些条件大多在CS模式中的网络比较繁忙的服务器端出现(如WEB服务器)。每个任务代表一个客户端进行接收请求并回复的I/O操作。客户的请求(相当于读操作)都是相互独立的。因此一个网络服务是异步模型的典型代表,这也是为什么twisted是第一个也是最棒的网络库。
对你的假设
在展开讨论前,我假设你已经有过用Python写同步程序的经历并且至少知道一点有关Python的Sockt编程的经验。如果你从没有写过Socket程序,或许你可以去看看Socket模块的文档,尤其是后面的示例代码。如果你没有用过Python的话,那后面的描述对你来说可能比看周易还痛苦。
对你的环境假设
我一般是在linux上使用Twisted,这个系列的示例代码也是在Linux下完成的。首先声明的是我并没有故意让代码失去平台无关性,但我所讲述的一些内容确实可能仅仅适应于Linux和其它的类Unix(比如Mac OSX或FreeBSD)。windows是个奇怪诡异的地方(为什么这么评价Windows呢),如果你想尝试在它上面学习这个系列,抱歉,如果出了问题,我无法提供任何帮助。 并且假设你已经安装了Python和Twisted。我所提供的示例代码是基于Python2.5和Twisted8.2.0。 你可以在单机上运行所有的示例代码,也可以在网络系统上运行它们。但是为了学习异步编程的机制,单机上学习是比较理想的。
获取代码的方法
使用git工具来获取Dave的最新示例代码。在shell或其它命令行上输入以下命令(假设已经安装git):
git clone git://GitHub.com/jdavisp3/twisted-intro.git
下载结束后,解压并进入第一层文件夹(你可以看到有个README文件)。
低效的诗歌服务器
虽然CPU的处理速度远远快于网络,但网络的处理速度仍然比人脑快,至少比人类的眼睛快。因此,想通过网络来获得CPU的视角是很困难的,尤其是在单机的回路模式中数据流全速传输时,更是困难重重。
我们所需要的是一个慢速低效诗歌服务器,其用人为的可变延时来体现对结果的影响。毕竟服务器要提供点东西嘛,我们就提供诗歌好了。目录下面有个子目录专门存放诗歌用的。
最简单的慢速诗歌服务器在blocking-server/slowpoetry.py中实现。你可用下面的方式来运行它。
python blocking-server/slowpoetry.py poetry/ecstasy.txt
上面这个命令将启动一个阻塞的服务器,其提供"Ecstasy"这首诗。现在我们来看看它的源码内容,正如你所见,这里面并没有使用任何Twisted的内容,只是最基本的Socket编程操作。它每次只发送一定字节数量的内容,而每次中间延时一段时间。默认的是每隔0.1秒发送10个比特,你可以通过--delay和 --num-bytes参数来设置。例如每隔5秒发送50比特:
python blocking-server/slowpoetry.py --num-bytes 50 ?-delay 5 poetry/ecstasy.txt
当服务器启动时,它会显示其所监听的端口号。默认情况下,端口号是在可用端口号池中随机选择的。你可能想使用固定的端口号,那么无需更改代码,只需要在启动命令中作下修改就OK了,如下所示:
python blocking-server/slowpoetry.py --port 10000 poetry/ecstasy.txt
如果你装有netcat工具,可以用如下命令来测试你的服务器(也可以用telnet):
netcat localhost 10000
如果你的服务器正常工作,那么你就可以看到诗歌在你的屏幕上慢慢的打印出来。对!你会注意到每次服务器都会发送过一行的内容过来。一旦诗歌传送完毕,服务器就会关闭这条连接。
默认情况下,服务器只会监听本地回环的端口。如果你想连接另外一台机子的服务器,你可以指定其IP地址内容,命令行参数是 --iface选项。
不仅是服务器在发送诗歌的速度慢,而且读代码可以发现,服务器在服务一个客户端时其它连接进来的客户端只能处于等待状态而得不到服务。这的确是一个低效慢速的服务器,要不是为了学习,估计没有任何其它用处。
阻塞模式的客户端
在示例代码中有一个可以从多个服务器中顺序(一个接一个)地下载诗歌的阻塞模式的客户端。下面让这个客户端执行三个任务,正如第一个部分图1描述的那样。首先我们启动三个服务器,提供三首不同的诗歌。在命令行中运行下面三条命令:
python blocking-server/slowpoetry.py --port 10000 poetry/ecstasy.txt --num-bytes 30
python blocking-server/slowpoetry.py --port 10001 poetry/fascination.txt
python blocking-server/slowpoetry.py --port 10002 poetry/science.txt
如果在你的系统中上面那些端口号有正在使用中,可以选择其它没有被使用的端口。注意,由于第一个服务器发送的诗歌是其它的三倍,这里我让第一个服务器使用每次发送30个字节而不是默认的10个字节,这样一来就以3倍于其它服务器的速度发送诗歌,因此它们会在几乎相同的时间内完成工作。
现在我们使用阻塞模式的客户端来获取诗歌,运行如下所示的命令:
python blocking-client/get-poetry.py 10000 10001 10002
如果你修改了上面服务口器的端口,你需要在这里相应的修改以保持一致。由于这个客户端采用的是阻塞模式,因此它会一首一首的下载,即只有在完成一首时才会开始下载另外一首。这个客户端会像下面这样打印出提示信息而不是将诗歌打印出来:
Task 1: get poetry from: 127.0.0.1:10000
Task 1: Got 3003 bytes of poetry from 127.0.0.1:10000 in 0:00:10.126361
Task 2: get poetry from: 127.0.0.1:10001
Task 2: got 623 bytes of poetry from 127.0.0.1:10001 in 0:00:06.321777
Task 3: get poetry from: 127.0.0.1:10002
Task 3: got 653 bytes of poetry from 127.0.0.1:10002 in 0:00:06.617523
Got 3 poems in 0:00:23.065661
这图1最典型的文字版了,每个任务下载一首诗歌。你运行后可能显示的时间会与上面有所差别,并且也会随着你改变服务器的发送时间参数而改变。尝试着更改一下参数来观测一下效果。
异步模式的客户端
现在,我们来看看不用Twisted构建的异步模式的客户端。首先,我们先运行它试试。启动使用前面的三个端口来启动三个服务器。如果前面开启的还没有关闭,那就继续用它们好了。接下来,我们通过下面这段命令来启动我们的异步模式的客户端:
python async-client/get-poetry.py 10000 10001 10002
你或许会得到类似于下面的输出:
Task 1: got 30 bytes of poetry from 127.0.0.1:10000
Task 2: got 10 bytes of poetry from 127.0.0.1:10001
Task 3: got 10 bytes of poetry from 127.0.0.1:10002
Task 1: got 30 bytes of poetry from 127.0.0.1:10000
Task 2: got 10 bytes of poetry from 127.0.0.1:10001
...
Task 1: 3003 bytes of poetry
Task 2: 623 bytes of poetry
Task 3: 653 bytes of poetry
Got 3 poems in 0:00:10.133169
这次的输出可能会比较长,这是由于在异步模式的客户端中,每次接收到一段服务器发送来的数据都要打印一次提示信息,而服务器是将诗歌分成若干片段发送出去的。值得注意的是,这些任务相互交错执行,正如第一部分图3所示。
尝试着修改服务器的设置(如将一个服务器的延时设置的长一点),来观察一下异步模式的客户端是如何针对变慢的服务器自动调节自身的下载来与较快的服务器保持一致。这正是异步模式在起作用。
还需要值得注意的是,根据上面的设置,异步模式的客户端仅在10秒内完成工作,而同步模式的客户端却使用了23秒。现在回忆一下第一部分中图3与图4.通过减少阻塞时间,我们的异步模式的客户端可以在更短的时间里完成下载。诚然,我们的异步客户端也有些阻塞发生,那是由于服务器太慢了。由于异步模式的客户端可以在不同的服务器来回切换,它比同步模式的客户产生的阻塞就少得多。
更近一步的观察
现在让我们来读一下异步模式客户端的代码。注意其与同步模式客户端的差别:
异步模式中客户端的核心就是最高层的循环体,即get_poetry函数。这个函数可以被拆分成两个步骤:
使用select函数等待所有Socket,直到至少有一个socket有数据到来。 对每个有数据需要读取的socket,从中读取数据。但仅仅只是读取有效数据,不能为了等待还没来到的数据而发生阻塞。 重复前两步,直到所有的socket被关闭。可以看出,同步模式客户端也有个循环体(在main函数内),但是这个循环体的每个迭代都是完成一首诗的下载工作。而在异步模式客户端的每次迭代过程中,我们可以完成所有诗歌的下载或者是它们中的一些。我们并不知道在一个迭代过程中,在下载哪首诗,或者一次迭代中我们下载了多少数据。这些都依赖于服务器的发送速度与网络环境。我们只需要select函数告诉我们哪个socket有数据需要接收,然后在保证不阻塞程序的前提下从其读取尽量多的数据。
如果在服务器端口固定的条件下,同步模式的客户端并不需要循环体,只需要顺序罗列三个get_poetry就可以了。但是我们的异步模式的客户端必须要有一个循环体来保证我们能够同时监视所有的socket端。这样我们就能在一次循环体中处理尽可能多的数据。
这个利用循环体来等待事件发生,然后处理发生的事件的模型非常常见,而被设计成为一个模式:Reactor模式。其图形化表示如图5所示:
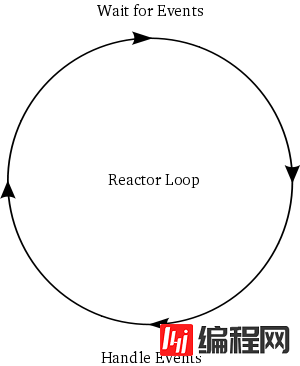
这个循环就是个"reactor"(反应堆),因为它等待事件的发生然后对其作相应的反应。正因为如此,它也被称作事件循环。由于交互式系统都要进行I/O操作,因此这种循环也有时被称作select loop,这是由于select调用被用来等待I/O操作。因此,在本程序中的select循环中,一个事件的发生意味着一个socket端处有数据来到。值得注意的是,select并不是唯一的等待I/O操作的函数,它仅仅是一个比较古老的函数而已(因此才被用的如此广泛)。现在有一些新api可以完成select的工作而且性能更优,它们已经在不同的系统上实现了。不考虑性能上的因素,它们都完成同样的工作:监视一系列sockets(文件描述符)并阻塞程序,直到至少有一个准备好的I/O操作。
严格意义上来说,我们的异步模式客户端中的循环并不是reactor模式,因为这个循环体并没有独立于业务处理(在此是接收具体的服务器传送来的诗歌)之外。它们被混合在一起。一个真正reactor模式的实现是需要实现循环独立抽象出来并具有如下的功能:
一个设计优秀的reactor模式实现需要做到:
处理所有不同系统会出现的I/O事件 提供优雅的抽象来帮助你在使用reactor时少花些心思去考虑它的存在 提供你可以在抽象层外使用的公共协议实现。 好了,我们上面所说的其实就是Twisted — 健壮、跨平台实现了reactor模式并含有很多附加功能。--结束END--
本文标题: Python的Twisted框架上手前所必须了解的异步编程思想
本文链接: https://lsjlt.com/news/14845.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0