目录1.定义Loss Function2.Gradient Descent3.求偏微分4.反向传播5.总结BP算法是适用于多层神经网络的一种算法,它是建立在梯度下降法的基础上的。本文
BP算法是适用于多层神经网络的一种算法,它是建立在梯度下降法的基础上的。本文着重推导怎样利用梯度下降法来minimise Loss Function。
给出多层神经网络的示意图:


每一个输出都对应一个损失函数L,将所有L加起来就是total loss。
那么每一个L该如何定义呢?这里还是采用了交叉熵,如下所示:
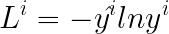

最终Total Loss的表达式如下:
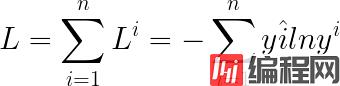
L对应了一个参数,即Network parameters θ(w1,w2…b1,b2…),那么Gradient Descent就是求出参数 θ∗来minimise Loss Function,即:
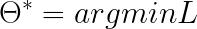
梯度下降的具体步骤为:

从上图可以看出,这里难点主要是求偏微分,由于L是所有损失之和,因此我们只需要对其中一个损失求偏微分,最后再求和即可。
先抽取一个简单的神经元来解释:




因为我们并不知道后面到底有多少层,也不知道情况到底有多复杂,我们不妨先取一种最简单的情况,如下所示:



l对两个z的偏导我们假设是已知的,并且在这里是作为输入,三角形结构可以理解为一个乘法运算电路,其放大系数为 σ′(z)。但是在实际情况中,l对两个z的偏导是未知的。假设神经网络最终的结构就是如上图所示,那么我们的问题已经解决了:

其中:

但是假如该神经元不是最后一层,我们又该如何呢?比如又多了一层,如下所示:
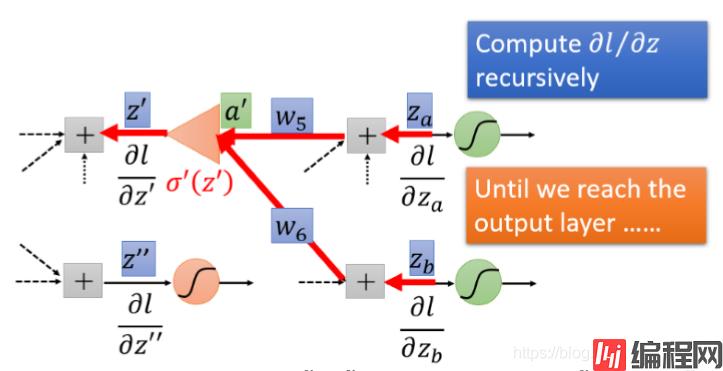

原理跟上面类似,如下所示:
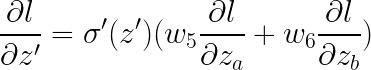

那假设我们再加一层呢?再加两层呢?再加三层呢?。。。,情况还是一样的,还是先求l对最后一层z的导数,乘以权重相加后最后再乘上 σ′(z′′,z′′′,...)即可。
最后给一个实例:
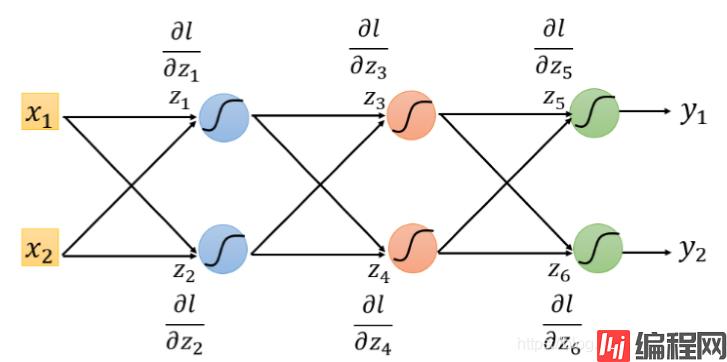
它的反向传播图长这样:
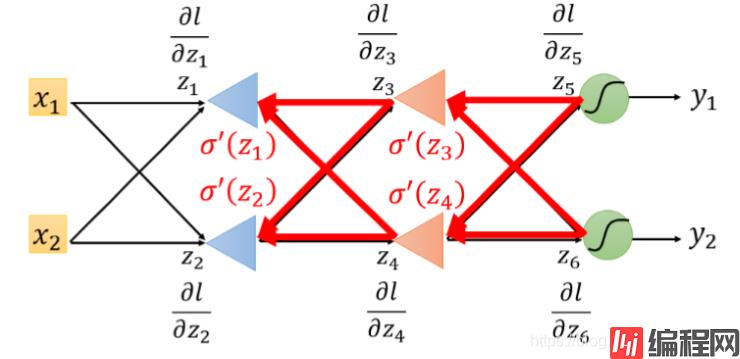

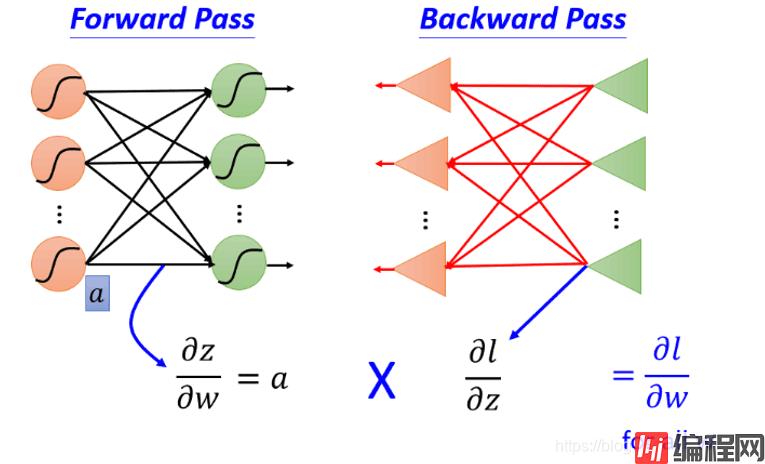
我们不难发现,这种计算方式很清楚明了地体现了“反向传播”四个字。好了,目标达成!!

以上就是反向传播BP学习算法-Gradient Descent的推导过程的详细内容,更多关于BP反向传播Gradient Descent推导的资料请关注编程网其它相关文章!
--结束END--
本文标题: 反向传播BP学习算法Gradient Descent的推导过程
本文链接: https://lsjlt.com/news/148449.html(转载时请注明来源链接)
有问题或投稿请发送至: 邮箱/279061341@qq.com QQ/279061341
2024-03-01
2024-03-01
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
2024-02-29
回答
回答
回答
回答
回答
回答
回答
回答
回答
回答


官方手机版

微信公众号

商务合作

0